TensorRT 基础笔记
Categories: CNN_Deploy
一 概述
TensorRT 是 NVIDIA 官方推出的基于 CUDA 和 cudnn 的高性能深度学习推理加速引擎,能够使深度学习模型在 GPU 上进行低延迟、高吞吐量的部署。采用 C++ 开发,并提供了 C++ 和 Python 的 API 接口,支持 TensorFlow、Pytorch、Caffe、Mxnet 等深度学习框架,其中 Mxnet、Pytorch 的支持需要先转换为中间模型 ONNX 格式。截止到 2021.4.21 日, TensorRT 最新版本为 v7.2.3.4。
深度学习领域延迟和吞吐量的一般解释:
- 延迟 (
Latency): 人和机器做决策或采取行动时都需要反应时间。延迟是指提出请求与收到反应之间经过的时间。大部分人性化软件系统(不只是 AI 系统),延迟都是以毫秒来计量的。 - 吞吐量 (
Throughput): 在给定创建或部署的深度学习网络规模的情况下,可以传递多少推断结果。简单理解就是在一个时间单元(如:一秒)内网络能处理的最大输入样例数。
二 TensorRT 工作流程
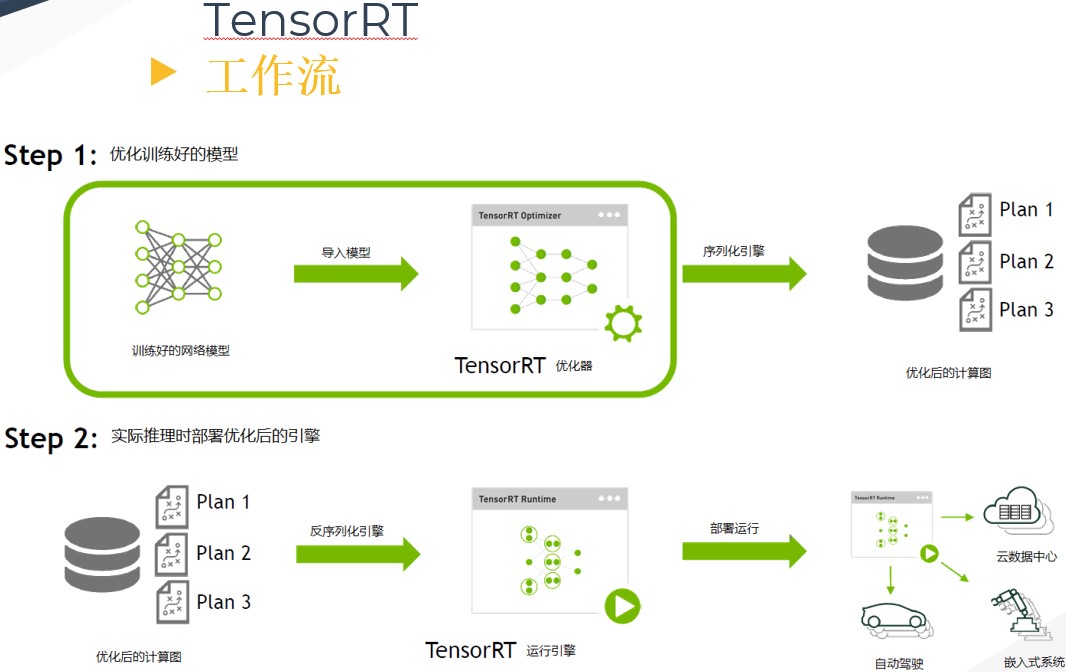
在描述 TensorRT 的优化原理之前,需要先了解 TensorRT 的工作流程。首先输入一个训练好的 FP32 模型文件,并通过 parser 等方式输入到 TensorRT 中做解析,解析完成后 engin 会进行计算图优化(优化原理在下一章)。得到优化好的 engine 可以序列化到内存(buffer)或文件(file),读的时候需要反序列化,将其变成 engine以供使用。然后在执行的时候创建 context,主要是分配预先的资源,engine 加 context 就可以做推理(Inference)。
三 TensorRT 的优化原理
TensorRT 的优化主要有以下几点:
- 算子融合(网络层合并):我们知道
GPU上跑的函数叫Kernel,TensorRT是存在Kernel调用的,频繁的Kernel调用会带来性能开销,主要体现在:数据流图的调度开销,GPU内核函数的启动开销,以及内核函数之间的数据传输开销。大多数网络中存在连续的卷积conv层、偏置bias层和 激活relu层,这三层需要调用三次 cuDNN 对应的 API,但实际上这三个算子是可以进行融合(合并)的,合并成一个CBR结构。同时目前的网络一方面越来越深,另一方面越来越宽,可能并行做若干个相同大小的卷积,这些卷积计算其实也是可以合并到一起来做的(横向融合)。比如GoogLeNet网络,把结构相同,但是权值不同的层合并成一个更宽的层。 concat层的消除。对于channel维度的concat层,TensorRT通过非拷贝方式将层输出定向到正确的内存地址来消除concat层,从而减少内存访存次数。-
Kernel可以根据不同batch size大小和问题的复杂度,去自动选择最合适的算法,TensorRT预先写了很多GPU实现,有一个自动选择的过程(没找到资料理解)。其问题包括:怎么调用CUDA核心、怎么分配、每个block里面分配多少个线程、每个grid里面有多少个block。 FP32->FP16、INT8、INT4:低精度量化,模型体积更小、内存占用和延迟更低等。- 不同的硬件如
P4卡还是V100卡甚至是嵌入式设备的卡,TensorRT都会做对应的优化,得到优化后的engine。
四 参考资料
- 内核融合:GPU深度学习的“加速神器”
- 高性能深度学习支持引擎实战——TensorRT
- 《NVIDIA TensorRT 以及实战记录》PPT
- https://www.tiriasresearch.com/wp-content/uploads/2018/05/TIRIAS-Research-NVIDIA-PLASTER-Deep-Learning-Framework.pdf