英伟达GPU架构总结
Categories: Hpc
- 背景知识
- 一,NVIDIA GPU 架构发展史
- 二,Volta(伏特)架构
- 三,Turing 架构
- 四,Ampere 架构
- 五,Hopper 架构
- 六,V100/A100/H100 计算能力对比
- 参考资料
背景知识
深度神经网络是由大量具有相同结构的神经元堆叠而成的,它们本质上具有很高的并行性,同时,神经网络严重依赖矩阵数学运算。对于多层网络来说,其需要大量的浮点性能和带宽来提高计算效率和速度,而 GPU 拥有数千个针对矩阵数学运算优化的处理核心-CUDA 核心,可提供数十至数百 TFLOPS 的性能,因此 GPU 硬件天然适合神经网络的训练和推理计算。
Tensor 算力和 FP32 算力
Tensor Core 专注于矩阵计算,是专门用于深度学习的混合精度计算单元。
单指令多线程 SIMT
SIMT(Single Instruction, Multiple Threads)模型一种并行计算模型,由 NVIDIA 的 GPU 架构 CUDA 引入的。在 SIMT 模型中,多个线程同时执行相同的指令,但操作的数据可以是不同的。每个线程都有自己的程序计数器和寄存器状态,但它们共享指令内存和全局内存。
与我们熟知的 SIMD(Single Instruction,Multiple Data)以及 SMT(Simultaneous Multithreading)相比,SIMT 带来了一些新的特性,在并行机制上总结如下:
- 在 SIMD 中,在一个 vector 中的多个 element 是完全同步并行计算的;
- 在 SMT 中,多个线程(thread)中的指令是并行执行的;
- 在 SIMT 中,多个 thread 共享一条指令并行执行(SMT 是各个线程 run 各自的指令),每个 thread 处理一个 scalar 数据,使之看起来像 SIMD,但是并不限制同时执行的 thread 之间的同步性。
带宽计算公式
带宽的计算使用公式:位宽 x 频率 x 倍率 / 8
以 GTX 1660 为例(Memory Clock = 2001 MHz, Effective Mem.Clock = 8 Gbps, Memory Bus Width = 192 bit):
显存带宽:8004bits * 192/8 = 192 096 Bytes = 192 GB/s
一,NVIDIA GPU 架构发展史
英伟达 GPU 架构简要发展史如下图所示。

- Kepler 架构里,FP64单元和FP32单元的比例是1:3或者1:24;K80。
- Maxwell 架构里,这个比例下降到了只有1:32;型号M10/M40。
- Pascal 架构里,这个比例又提高到了1:2(P100)但低端型号里仍然保持为1:32,型号Tesla P40、GTX 1080TI/Titan XP、Quadro GP100/P6000/P5000
- Votal 架构里,FP64 单元和 FP32 单元的比例是 1:2;型号有 Tesla V100、GeForceTiTan V、Quadro GV100 专业卡。
- Turing 架构里,一个SM中拥有64个半精度,64个单精度,8个Tensor core,1个RT core。
- Ampere 架构的设计突破,在8代GPU架构中提供了该公司迄今为止最大的性能飞跃,统一了AI培训和推理,并将性能提高了20倍。A100是通用的工作负载加速器,还用于数据分析,科学计算和云图形。
总结:NVDIA GPU 用到的 SIMT(Single Instruction, Multiple Threads)基本编程模型都是一致的,每一代相对前代基本都会在 SM 数量、SM 内部各个处理单元的流水线结构等等方面有一些升级和改动。
英伟达各个架构官网总览页面。
二,Volta(伏特)架构
本文对 Volta 架构的总结是基于 Volta 架构白皮书资料总结而来,该白皮书介绍了 Tesla V100 加速器和 Volta GV100 GPU 架构。
2.1,Volta 架构主要特性
以基于 Volta GV100 GPU 架构的 Tesla V100 加速器为例,介绍 Volta 架构的主要特点:
1,专门为深度学习优化的全新流式多处理器 (SM) 架构
- 新型 Volta SM 的能效比上一代 Pascal 架构设计高
50%,可在相同功率范围内显着提升 FP32 和 FP64 性能。 - 专为深度学习设计的全新
Tensor Core可提供高达 12 倍的训练峰值 TFLOPS 和 6 倍的推理峰值 TFLOPS。
2,第二代 NVIDIA NVLink™
Volta GV100 支持多达六个 NVLink 链路和 300 GB/秒的总带宽,而 GP100 仅支持四个 NVLink 链路和 160 GB/s 的总带宽。
3,HBM2 显存:更快更高效
Volta 架构高度优化l HBM2 显存,可提供 900 GB/秒的峰值内存带宽。值得注意的是,虽然 Tesla P100 是全球第一个支持高带宽 HBM2 内存技术的 GPU 架构,但是基于 Volta 架构的 Tesla V100 的 HBM2 更快、更高效,支持最大 16GB 的内存容量,峰值内存带宽可达 900GB/s,而 Tesla P100 仅为 732GB/s。
4,Volta 多进程服务
Volta 多进程服务 (MPS) 是 Volta GV100 架构的一项新功能,可为 CUDA MPS 服务器的关键组件提供硬件加速,从而为共享 GPU 的多个计算应用程序提高性能、隔离和更好的服务质量 (QoS)。
5,等等
基于 Volta 架构的 Tesla V100 加速器的主要新技术如下图所示:

总结:个人认为 Volta 架构的最主要新特性是,在传统的单双精度计算之外还增加了专用的Tensor Core 张量单元,用于深度学习的 GEMM 计算。
2.2,Volta GV100 GPU 硬件结构
与上一代 Pascal GP100 GPU 一样,GV100 GPU 由多个 GPU 处理集群 (GPC)、纹理处理集群 (TPC)、流式多处理器 (SM-STREAMING MULTIPROCESSOR) 和内存控制器组成。完整的 GV100 GPU 包括:
6个GPC,每个 GPC 都有:7个TPC(每个包含两个 SM)14个SM
84个 VoltaSM,每个SM都有:- 64 个 FP32 核心
- 64 个 INT32 核心
- 32 个 FP64 核心
- 8 个张量核心(Tensor Cores)
- 4 个纹理单元(texture units)
- 8 个 512 位内存控制器(总共 4096 位)
总结: 一个完整的 GV100 GPU 含有 84 个 SM,总共有 5376 个 FP32 核心、5376 个 INT32 核心、2688 个 FP64 核心、672 个Tensor Cores 和 336 个纹理单元。 每个 HBM2 DRAM 堆栈都由一对内存控制器控制。 完整的 GV100 GPU 包括总计 6144 KB 的二级缓存。
下图显示了具有 84 个 SM 的完整 GV100 GPU(注意,不同的产品可以使用不同配置的 GV100)。Tesla V100 加速器使用 80 个 SM。
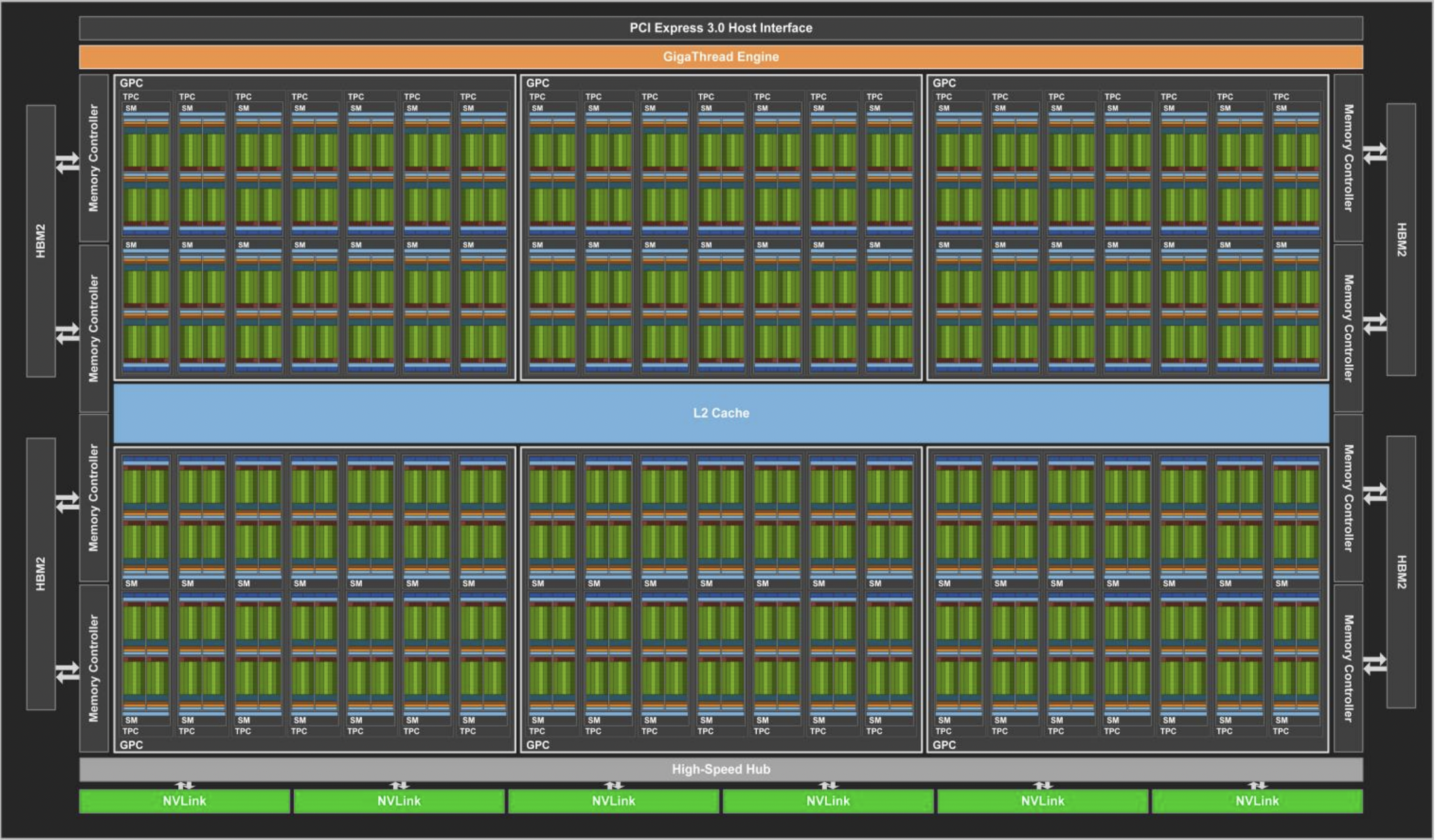
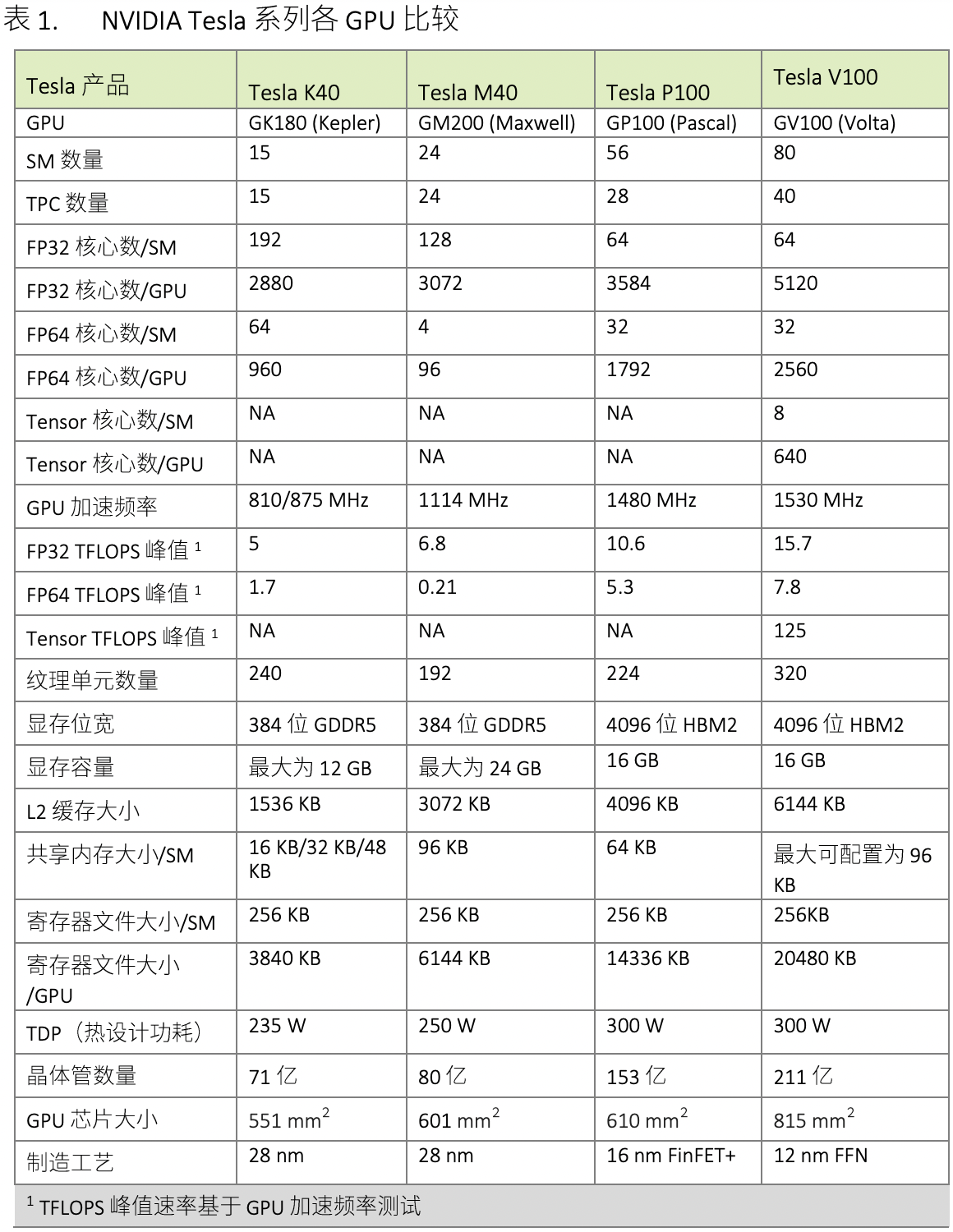
表 1 比较了过去五年的 NVIDIA Tesla GPU。
下表展示了 NVIDIA Tesla GPU 的比较。
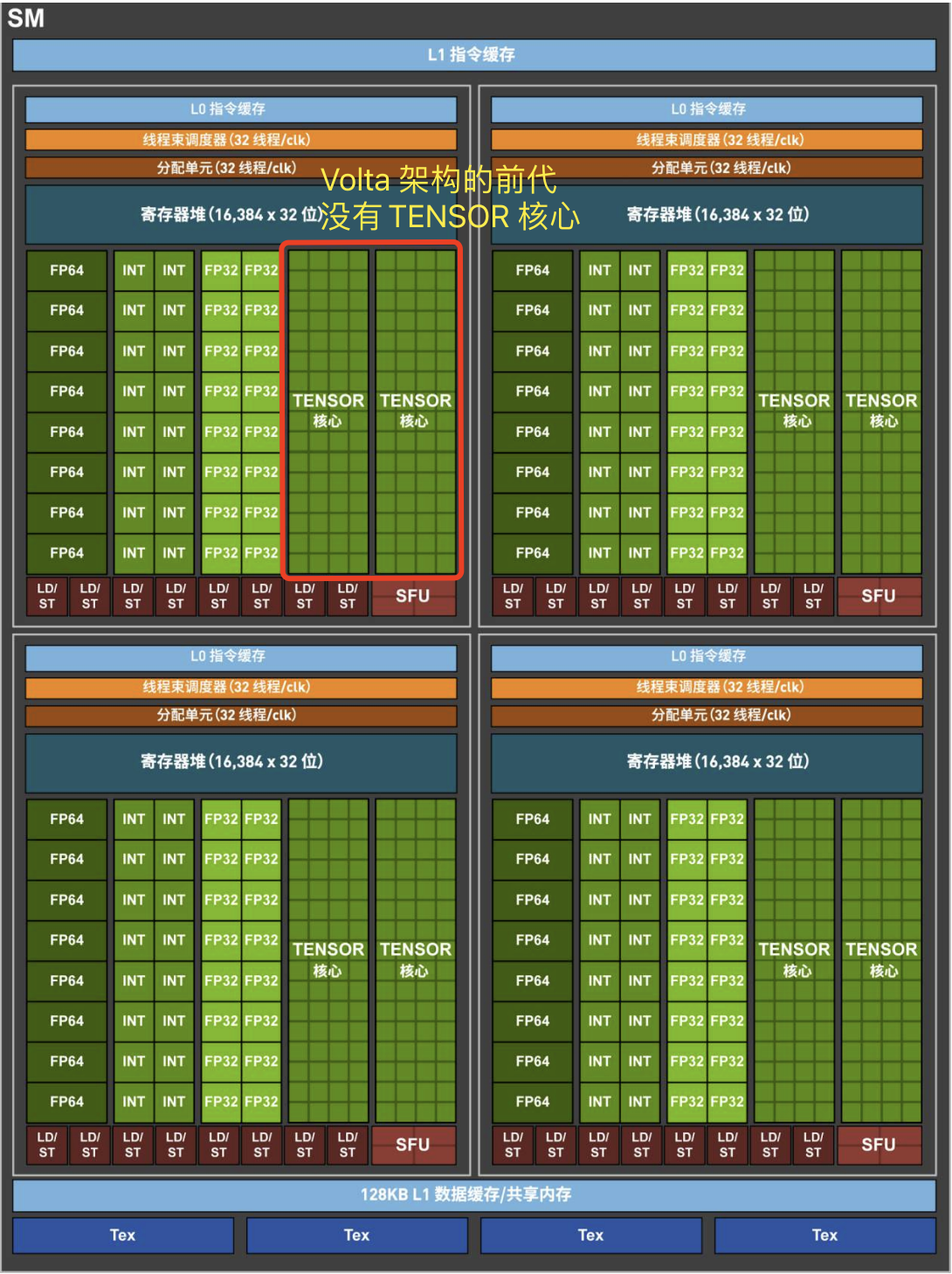
2.3,Volta SM 硬件结构
GV100 GPU 有 84 个 SM。与 Pascal GP100 类似,GV100 的每个 SM 都包含 64 个 FP32 内核和 32 个 FP64 内核。 但是,GV100 SM 使用了一种新的分区方法来提高 SM 利用率和整体性能。
GP100SM被划分为两个处理块,每个处理块具有32个 FP32 内核、16 个 FP64 内核、一个指令缓冲区、一个warp调度程序、两个调度单元和一个 128 KB 的寄存器文件。GV100SM分为四个处理块,每个处理块有16个 FP32 内核、8 个 FP64 内核、16 个 INT32 内核、两个用于深度学习矩阵运算的新混合精度 Tensor 内核、一个新的 L0 指令缓存、一个 warp 调度程序、一个调度单元和一个 64 KB 的寄存器文件。新的 L0 指令缓存现在用于每个分区,用以提供比以前的 NVIDIA GPU 中使用的指令缓冲区更高的效率。
总的来说,与前几代 GPU 相比,GV100 支持更多的线程、线程束和线程块。 共享内存和 L1 资源的合并使每个 Volta SM 的共享内存容量增加到 96 KB,而 GP100 为 64 KB。
Volta GV100 流式多处理器(SM)架构如下图像所示:
2.3.1,Volta 和 Pascal 在内存层次的比较

2.4,Volta Tensor 核心
NVIDIA Volta 的 Tensor Core 是第一代,是专门用于深度学习的混合精度计算单元。
Tesla V100 GPU 包含 640 个 Tensor Core:每个 SM 有 8 个 Tensor Core,每个 SM 中的每个处理块(分区)有 2 个 Tensor Core。
在 Volta GV100 中,每个 Tensor Core 每个时钟执行 64 次浮点 FMA(混合乘加)运算,即一个 SM 中的 8 个 Tensor Core 每个时钟执行总共 512 个 FMA 运算(或 1024 个单独的浮点运算)。
Tensor Cores 在具有 FP32 累加的 FP16 输入数据上运行。FP16 乘法产生全精度乘积,然后使用 FP32 加法与其他中间乘积进行累加,以实现 4x4x4 矩阵乘法,计算过程如下图所示。在实际项目中,Tensor Core 是用于执行更大的 2D 或更高维的矩阵运算,这些运算又由这些较小的元素块构建而成。

如果使用 CUDA 核心,对于 4x4 矩阵乘法需要执行 64 次浮点运算来生成 4x4 输出矩阵,而具有 Tensor Core 的基于 Volta 的 V100 GPU 执行此类计算的速度比基于 Pascal 的 Tesla P100 会快 12 倍。4x4 矩阵乘法使用cuda核心和tensor核心计算过程对比如下图所示。

Volta 架构的 Tensor Core 的特性已经在 CUDA9 C++ API 提供,公开了专门的矩阵加载、矩阵乘法和累加以及矩阵存储操作,在 CUDA 级别,warp 级接口假设 16x16 大小的矩阵跨越 warp 的所有 32 个线程。
2.5,NVIDIA TESLA V100 芯片
NVIDIA TESLA V100 芯片是用于 HPC(高性能计算)的专业卡,是第一个配备 Tensor Core 的 GPU,采用 Volta 架构,提供 16GB 和 32GB 显存两个版本。主要规格如下如下表所示。
| GPU 架构 | Tensor核心 | CUDA 核心 | FP64 算力 | FP32算力 | Tensor 效能 | 显存 | 显存带宽 | 双向互连带宽 | |
|---|---|---|---|---|---|---|---|---|---|
Tesla V100 PCle |
Volta | 640 | 5120 | 7 TFLOPS | 14 TFLOPS | 112 TFLOPS | 32GB /16GB HBM2 | 900GB/sec | 32GB/sec |
Tesla V100 SXM2 |
Volta | 640 | 5120 | 7.8TFLOPS | 15.7 TFLOPS | 125 TFLOPS | 32GB /16GB HBM2 | 900GB/sec | 300GB/sec |
更加详细的规格如下图所示:

三,Turing 架构
Turing 核心架构采用全新 GPU 处理器(流式多元处理器,SM)架构,可有效提升着色器执行效率,同时还配备支持最新 GDDR6 显存技术的全新显存系统架构。得益于这两大关键配置,Turing 的图形性能得以显著提升。另外,Turing GPU 采用全新 RT 核心,第一次带来了光线追踪功能。
3.1,Turing 架构的主要特性
3.1.1,新型流式多元处理器 (SM)
Turing 架构升级了 SM,能够大幅度提升着色效率(shading efficiency),且相较 Pscal 系列,能使每个 CUDA 核心的性能提升 50%。SM 性能的提升,主要是得益于两项关键的架构更新:
- Turing SM 添加了新的独立整型数据通道,可与浮点数据通道同时执行指令。在前几代中,执行这些指令将会阻止浮点指令的发出。
- SM 存储路径已经过重新设计,能够将共享内存、纹理缓存和内存负载缓存整合到一个单元中。对于普通工作负载而言,这可为 L1 缓存提供 2 倍以上的带宽和可用容量。
3.1.2,新型 Tensor 核心
Tensor 核心是为执行张量或矩阵运算而设计的专用执行单元,而这些运算正是深度学习所采用的核心计算函数。
与 Volta Tensor 核心类似,Turing Tensor 核心也能够大幅加速处于深度学习神经网络训练和推理运算核心的矩阵计算。
Turing Tensor 核心的升级是对推理性能的优化,加入了新的 INT8 和 INT4 精度模式,支持模型量化推理,且能完全支持 FP16!
3.1.3,新型 RT 核心-实现实时光线追踪加速
Turing 的新型 RT 核心能够加速光线追踪并可用于多个系统和接口,如 NVIDIA RTX 光线追踪技术和 Microsoft DXR、NVIDIA OptiX™ 以及 Vulkan 光线追踪等 API,以提供实时光线追踪体验。
3.1.4,着色技术的全新进展
- 网格着色
- 可变速率着色 (VRS)
- 纹理空间着色
- 多视图渲染 (MVR)
3.1.5,显存升级-GDDR6 高性能显存子系统
Turing 是首款支持 GDDR6 显存的 GPU 架构。GDDR6 是高带宽 GDDR DRAM 内存设计的又一次重大飞跃。与 Pascal GPU 中使用的 GDDR5X 显存相比,GDDR6 可达到 14 Gbps 的传输速率,并将能效提高 20%。
3.1.6,第二代 NVIDIA NVLink
Turing TU102 和 TU104 GPU 采用 NVIDIA NVLink™ 高速互联技术,可在数对 Turing GPU 之间提供可靠的高带宽和低延迟连通性。NVLink 具有高达 100GB/秒的双向带宽,能够使定制工作负载在两个 GPU 之间进行高效分割并共享内存容量。
3.2,TURING TU102 GPU 硬件结构
完整的 TU102 GPU 硬件结构包括:
6个图像处理集群 (GPC),每个GPC都有:
- 一个专用的光栅化引擎
6个TPC,每个 TPC 均包含2个SM。
72个流式多元处理器 (SM),每个 SM 都有:
- 64 个 CUDA 核心
- 8 个 Tensor 核心
- 1 个 256 KB 寄存器堆
- 4 个纹理单元以及 96 KB 的 L1 或共享内存
总的来说,完整的 TU102 GPU 包含 6 个图像处理集群 (GPC)、36 个纹理处理集群 (TPC) 和 72 个流式多元处理器 (SM)。从 SM 架构描述,就是包括以下部件:
- 4608 个 CUDA 核心
- 72 个 RT 核心
- 576 个 Tensor 核心
- 288 个纹理单元
- 12 个 32 位 GDDR6 显存控制器(共 384 位)。
Turing TU102 GPU 的内部结构图如下所示。

图 2. 含 72 个 SM 单元的完整 Turing TU102 GPU 内部构造。
3.2,TURING 架构的 SM 结构
Turing 架构采用全新 SM 设计。每个 TPC 均包含两个 SM,每个 SM 共有 64 个 FP32 核心和 64 个 INT32 核心。相比之下,Pascal GP10x GPU 的每个 TPC 仅有一个 SM,且每个 SM 只含 128 个 FP32 核心。
Turing TU102/TU104/TU106 流式多元处理器 (SM)结构图如下所示:

3.4,基于 TURING GPU 架构的专业训练卡对比-RTX 6000 卡
1,以 Quadro P6000 专业卡和 Quadro RTX 6000 专业卡的对比为例,对比 Pacal 和 Turing 的特性:
| GPU 架构 | Tensor核心 | CUDA 核心 | FP32算力 | Tensor 效能 | 显存 | 显存带宽 | |
|---|---|---|---|---|---|---|---|
| NVIDIA® QUADRO® P6000 | Volta | 不适用 | 3840 | 12 TFLOPS | 112 TFLOPS | 24 GB GDDR5X | 432 GB/ses |
| Quadro RTX 6000 | Turing | 576 | 4,608 | 16.3 TFLOPS | 130.5 TFLOPS | 24 GB GDDR6X | 672 GB/ses |
2,更详细的 NVIDIA Pascal GP102 与 Turing TU102 对比表如下所示:


3.5,基于 TURING GPU 架构的专业推理卡对比-T4 卡
NVIDIA Tesla T4 是首款基于 Turing 架构的专业推理卡,专为数据中心而设计,可提供卓越的推理性能和能效。
Tesla T4 采用的 TU104 芯片包含 5 个 GPC、20 个 TPC、40 个 SM 以及 320 个 Turing Tensor 核心,CUDA 核心总数达 2560 个。此外,Tesla T4 TU104 芯片还包含 256 位 显存位宽,显存数据速率为 10 Gbps,总带宽达 320 GB/秒。
Pascal Tesla P4 和 Turing Tesla T4 对比表总结如下所示(更详细对比参考 Turing 架构白皮书):
| GPU 架构 | Tensor 核心数/GPU | CUDA 核心 | FP32 峰值算力 | FP16 TFLOPS | INT8 TFLOPS | 显存 | |
|---|---|---|---|---|---|---|---|
| Tesla P4 (Pascal) | Volta | 不适用 | 2560 | 5.5 TFLOPS | 16.2 TFLOPS | 22 TOPS* | 8 GB GDDR5X |
| Tesla T4 (Turing) | Turing | 320 | 2560 | 8.1TFLOPS | 不适用 | 130 TOPS | 16GB GDDR6X |
TOPS* (Tera-Operations per Second) Tesla P4 专业推理卡数据手册,Tesla T4 专业推理卡数据手册。
Pascal Tesla P4 专业推理卡和 Turing Tesla T4 专业推理卡的规格对比如下图所示:

四,Ampere 架构
4.1,Ampere 架构的主要特性
1,第二代 RT 核心
2,第三代 Tensor Cores
NVIDIA Tensor Core 技术在 NVIDIA Volta™ 架构中是首次引入,Ampere 架构和前面相比,引入了 Tensor Float 32 (TF32) 和浮点 64 (FP64)精度类型。TF32 数据类型的工作方式与 FP32 一样,无需更改任何代码即可为 AI 提供高达 20 倍的加速。

3,结构稀疏性
Tensor Core 可为稀疏模型提供高达 2 倍的性能提升,GPU 支持稀疏性,不仅有利于 AI 模型推理,也有利于训练。

4,第三代 NVLink
NVIDIA Ampere 架构中的第三代 NVIDIA® NVLink® 将 GPU 到 GPU 的直接带宽增加了一倍,达到每秒 600 GB (GB/s),几乎是 PCIe Gen4 的 10 倍。

5,多实例 GPU (MIG)
多实例 GPU (MIG) 是 A100 和 A30 GPU 支持的一项功能,允许工作负载共享 GPU。 借助 MIG,每个 GPU 都可以划分为多个 GPU 实例,通过它们自己的高带宽内存、缓存和计算核心在硬件级别完全隔离和保护。

4.2,Ampere GA100 GPU 硬件结构
NVIDIA GA100 GPU 由多个 GPU 处理群集(GPC),纹理处理群集(TPC),流式多处理器 (SM) 和 HBM2 显存控制器组成。
1,GA100 GPU 的完整实现包括以下单元:
- 每个完整 GPU 有 8 个 GPC,每个 GPC 有 8 个 TPC,每个 TPC 有 2 个SM,每个 GPC 有 16 个SM,总共 128 个 SM;
- 每个 SM 有 64 个 FP32 CUDA 核,总共 8192 个 FP32 CUDA 核;
- 每个 SM 有 4 第三代 Tensor Core,总共 512 个第三代 Tensor Core;
- 总共 6 个 HBM2 堆栈,12 个 512 位显存控制器;
基于 GA100 GPU 实现的 A100 Tensor Core GPU 包括以下单元:
- 每个 GPU 有 7 个 GPC,每个 GPC 有 7 个或 8 个 TPC ,每个 TPC 有 2 个 SM,每个 GPC 最多 16 个 SM,总共 108个SM;
- 每个 SM 有 64 个 FP32 CUDA 核,总共 6912 个 FP32 CUDA 核;
- 每个 SM 有 4 个第三代 Tensor Core,总共 432个第三代 Tensor Core;
- 总共 5个HBM2 堆栈,10 个 512 位显存控制器;
图 4 展示了一颗带有 128 个 SM 的完整 GA100 GPU,值得注意的是,基于 GA100 的 A100 只有 108 个 SM。

4.3,A100 流处理器(SM)结构
新的 A100 SM 显著提升了性能,在 Volta 和 Turing SM 架构的特性基础上新增了许多功能。A100 SM 的硬件结构如下图示:

A100 SM 结构的关键特性总结如下:
- 第三代 Tensor Cores(最重要的更新)
- 支持数据类型的加速,包括 FP16、BF16、TF32、FP64、INT8、INT4 和 Binary。
- 新的 Tensor Core 的稀疏性支持细粒度稀疏性,与标准 Tensor Cores 相比,性能提升高达 1 倍。
- BF16/FP32 混合精度 Tensor Core 运算能以与 FP16/FP32 混合精度相同的速率运行。
- 等等。
- 192 KB 组合共享内存和 L1 数据缓存,是 V100 的 1.5(192/128)倍。
- 新的异步复制指令将数据直接从全局内存加载到共享内存中,可选择绕过 L1 缓存,并且无需使用中间寄存器文件 (RF)。
- 新的基于共享内存的屏障单元(异步屏障)用于新的异步复制指令。
- L2 缓存管理和驻留控制的新说明。
- CUDA 合作组支持的新扭曲级减少指令。
- 许多可编程性改进以降低软件复杂性。
下图为 V100 和 A100 FP16/FP32/FP64/INT8 Tensor Core 计算对比示意图。
4.3.1,L1 Data Cache 和 Shared Memory
即 L1 数据缓冲和共享内存合并,共用一个硬件内存块,首次引入于 Volta V100 芯片,NVIDIA 的结合 L1 数据缓存和共享内存子系统架构显著提高了性能,同时简化了编程,减少了达到或接近应用性能峰值所需的调优工作。将数据缓存和共享内存功能合并到一个内存块中,为两种类型的内存访问提供了最佳的整体性能。A100 的 L1 数据缓存和共享内存的总容量为 192 KB/SM,而 V100 为 128 KB/SM。其中 V100 共享内存最大可配置为 96KB,A100 最大可配置为 164 KB。
在共享内存块内集成 L1 缓存,确保了 L1 缓存具有低延迟和高带宽。L1 缓存作为高吞吐量的数据流通道,同时为频繁重用的数据提供高带宽和低延迟访问,兼顾两者的优点。A100 的更大 L1/共享内存子系统进一步提升了使用 L1 数据缓存访问设备内存的应用性能,使得性能接近于使用并显式管理快速共享内存的水平。
4.4,NVIDIA A100 芯片规格
NVIDIA A100 Tensor Core GPU 与前前一代 NVIDIA Volta™ 相比,借助 Tensor 浮点运算 (TF32) 精度,A100 可使性能提升高达 20 倍;若使用自动混合精度和 FP16,性能可进一步提升 2 倍。与 NVIDIA® NVLink®、NVIDIA NVSwitch™、PCIe 4.0、NVIDIA® InfiniBand® 和 NVIDIA Magnum IO™ SDK 结合使用时,它能扩展到数千个 A100 GPU。
A100 提供了高达 80GB 的 GPU 显存和 2TB/s 的显存带宽,主要规格如下如下表所示。
| GPU 架构 | FP64 算力 | FP64 Tensor Core | FP32 算力 | Tensor Float 32(TF32) |
BFLOAT16 Tensor Core | FP16 Tensor Core | INT8 Tensor | GPU 显存 | GPU 显存带宽 | |
|---|---|---|---|---|---|---|---|---|---|---|
| A100 PCIe | Ampere | 9.7TFLOPS | 19.5TFLOPS | 19.5TFLOPS | 156 TFLOPS/312 TFLOPS* | 312 TFLOPS/624 TFLOPS* | 312 TFLOPS/624 TFLOPS* | 624 TOPS/1248 TOPS* | 80GB HBM2e | 1935GB/s |
| A100 SXM | Ampere | 9.7 TFLOPS | 19.5TFLOPS | 19.5TFLOPS | 156 TFLOPS/312 TFLOPS* | 312 TFLOPS/624 TFLOPS* | 312 TFLOPS/624 TFLOPS* | 624 TOPS/1248 TOPS* | 80GB HBM2e | 2039GB/s |
更加详细的规格如下图所示:

NVIDIA A100 GPU 的突破性创新点:
- 基于 NVIDIA AMPERE 架构
- 第三代 TENSOR CORE 技术
- 新一代 NVLINK
- 多实例 GPU(MIG)技术
- 高带宽显存(HBM2E)
- 结构化稀疏:A100 中的 TENSOR CORE 可为稀疏模型提供高达
2倍多性能提升。
美国监管机构去年出台规定,以国家安全为由,禁止英伟达向中国客户销售两款最先进的芯片A100和更新的H100。由于中国高性能计算市场对英伟达来说是一个不可放弃的巨大市场,英伟达分别于2022年11月、23年3月发布A100、H100 的“阉割”版本A800、H800,通过降低数据传输速率(显存带宽)避开美国限制,从而合法出口到中国。A800芯片的数据传输速率为400GB/s,低于A100芯片的600GB/s,而其他参数变化不大,A800较A100整体通信带宽性能砍了33%,阉割的部分很小的,A800只影响多卡互联的性能,而计算能力完全保留!A800有三种不同版本,以及SXM和PCIe两种不同形态,分别是40GB HBM2线程PCIe接口、80GB HBM2e显存PCIe接口、80GB HBM2e显存SXM接口,可满足不同客户和环境的需求。来源这里。
4.4.1,NVIDIA A100 GPU 计算性能规格

4.4.2,P100/V100/A100 芯片规格比较


五,Hopper 架构
5.1,Hopper 架构的主要特性
以基于 NVIDIA Hopper™ GPU 计算架构的 H100 GPU 为例,介绍 Hopper™ 架构的主要特点:
1,新的流式多处理器 (SM),在性能和效率方面有很多改进,包括:
- 与
A100相比,新的第四代 Tensor Core 芯片之间的速度最高可提升 6 倍,包括每个 SM 加速、额外的 SM 数量以及更高的 H100 时钟频率。对于单个 SM,与上一代 16 位相比,Tensor Core 在同等数据类型上计算 MMA(矩阵乘积累加)速度是 A100 SM 的 2 倍,如果使用新的FP8数据类型时,计算速度是 A100 的4倍。 - 值得注意点是,稀疏功能能支持细粒度结构化稀疏,这使得使标准 Tensor Core 运算的性能提高了一倍。
- 与 A100 GPU 相比,新的 DPX 指令最高可将动态编程算法的速度提升 7 倍。
- 与 A100 相比,IEEE FP64 和 FP32 的芯片间处理速度可提升 3 倍,这是因为每个 SM 的时钟频率提升了 2 倍,此外还有额外的 SM 数量以及更高的 H100 时钟频率。
- 新的线程块簇功能允许以比单个 SM 上的单个线程块更大的粒度对局部性进行编程控制。
- 新的异步执行功能包括新的 Tensor Memory Accelerator (TMA) 单元,此单元可以在全局显存和共享内存之间非常高效地传输大数据块。
2,新的 Transformer 引擎
该引擎结合了软件和定制的 Hopper Tensor Core 技术,专门用于加速 Transformer 模型的训练和推理,且能够智能管理并动态选择 FP8 和 FP16 计算,自动处理每层中 FP8 和 FP16 之间的重铸和缩放。与上一代 A100 相比,可令大型语言模型的 AI 训练速度最高提升 9 倍、AI 推理速度最高提升 30 倍。
3,使用 HBM3 显存子系统
与上一代产品相比,HBM3 显存子系统的带宽提升了近 2 倍。H100 SXM5 GPU 率先采用 HBM3 显存,可提供 3TB/s 的超高显存带宽。
4,使用第二代多实例 GPU (MIG) 技术
与 A100 相比,第二代多实例 GPU (MIG) 技术提供的计算容量大约增加了 3 倍,每个 GPU 实例的显存带宽提升了近 2 倍。现在首次提供具有 MIG 级别可信执行环境 (TEE) 的机密计算能力。支持多达七个单独的 GPU 实例,每个实例均配备专门的 NVDEC 和 NVJPG 单元。
5,第四代 NVIDIA NVLink
与上一代 NVLink 相比,第四代 NVIDIA NVLink® 可将全局归约操作的带宽提升 3 倍,通用带宽提升 50%,同时多 GPU IO 的总带宽为 900GB/s,是 PCIe 5.0 的 7 倍。
6,PCIe 5.0 技术
PCIe 5.0 的总带宽为 128GB/s(每个方向 64GB/s),而 PCIe 4.0 的总带宽为 64GB/s(每个方向 32GB/s)。PCIe 5.0 支持 H100 与超高性能的 x86 CPU 和智能网卡 / DPU(数据处理器)交互。
5.2,Hopper GH100 GPU 硬件结构
基于新 Hopper GPU 架构的 NVIDIA H100 GPU,这里简称为
GH100 GPU。
完整的 GH100 GPU 架构包括以下单元:
- 8 个 GPC、72 个 TPC(9 个 TPC/GPC)、2 个 SM/TPC、每个完整 GPU 内含 144 个 SM,每个 SM 内含:
128个 FP32 CUDA Core 核心,即每个 GPU 内含18432个 FP32 CUDA Core 核心;4个第四代 Tensor Core 核心,即每个 GPU 内含576个第四代 Tensor Core 核心。
- 6 个 HBM3 或 HBM2e 堆栈、12 个 512 位内存控制器
- 60MB 二级缓存
- 第四代 NVLink 和 PCIe 5.0
采用 SXM5 主板封装的 NVIDIA H100 GPU 包括以下单元:
- 8 个 GPC、66 个 TPC、2 个 SM/TPC、每个 GPU 内含 132 个 SM
- 每个 SM 内含 128 个 FP32 CUDA Core 核心、每个 GPU 内含 16896 个 FP32 CUDA Core 核心
- 每个 SM 内含 4 个第四代 Tensor Core 核心、每个 GPU 内含 528 个第四代 Tensor Core 核心
- 80GB HBM3、5 个 HBM3 堆栈、10 个 512 位内存控制器
- 50MB 二级缓存
- 第四代 NVLink 和 PCIe 5.0
采用 PCIe 5.0 主板封装的 NVIDIA H100 GPU 包括以下单元:
- 7 或 8 个 GPC、57 个 TPC、2 个 SM/TPC、每个 GPU 内含 114 个 SM
- 每个 SM 内含 128 个 FP32 CUDA Core 核心、每个 GPU 内含 14592 个 FP32 CUDA Core 核心 每个 SM 内含 4 个第四代 Tensor Core 核心、每个 GPU 内含 456 个第四代 Tensor Core 核心
- 80GB HBM2e、5 个 HBM2e 堆栈、10 个 512 位内存控制器
- 50MB 二级缓存
- 第四代 NVLink 和 PCIe 5.0
与采用 TSMC 7nm N7 制造工艺的上一代 GA100 GPU 相比,采用 TSMC 4N 制造工艺使 H100 能够增加 GPU 核心频率、提高性能功耗比,并整合更多的 GPC、TPC 和 SM。
配备 144 个 SM 的完整 GH100 GPU 核心的架构图如下所示:

5.3,Hopper SM 架构总结
H100 SM 基于 NVIDIA A100 Tensor Core GPU SM 结构而构建。但由于引入了 FP8,与 A100 相比,H100 SM 将每 SM 浮点计算能力峰值提升了 4 倍,并且对于之前所有的 Tensor Core 和 FP32 / FP64 数据类型,将各个时钟频率下的原始 SM 计算能力增加了一倍。
Hopper 新的第四代 Tensor Core、Tensor 内存加速器以及许多其他新 SM 和 H100 架构的总体改进,在许多其他情况下可令 HPC 和 AI 性能获得最高 3 倍的提升。
GH100 流式多处理器 (SM)架构如下图所示:

5.4,H100 Tensor Core 架构
Tensor Core 是专门用于矩阵乘积累加 (MMA) 数学运算的高性能计算核心,可大大提升 AI 和 HPC 应用的性能。与标准浮点 (FP) 运算、整数 (INT) 运算和融合乘加 (FMA) 运算相比,在一个 NVIDIA GPU 内跨 SM 并行运行的 Tensor Core 可大幅提高吞吐量和效率。Tensor Core 首次引入是在 NVIDIA Tesla® V100 GPU 中,并在每一代新的 NVIDIA GPU 架构中不断增强这一核心。
与 A100 相比,H100 中新的第四代 Tensor Core 架构可使每时钟每个 SM 的原始密集计算和稀疏矩阵运算吞吐量提升一倍,考虑到 H100 比 A100 拥有更高的 GPU 加速频率,其甚至会达到更高的吞吐量。
其支持 FP8、FP16、BF16、TF32、FP64 和 INT8 MMA 数据类型。新的Tensor Core 还能够实现更高效的数据管理,最高可节省 30% 的操作数传输功耗。
NVIDIA Hopper™ 架构通过使用新的 8 位浮点精度 (FP8) 的 Transformer Engine 改进了第四代 Tensor Cores,H100 FP16 Tensor Core 的吞吐量是 A100 FP16 Tensor Core 的 3 倍。

5.5,NVIDIA H100 芯片
NVIDIA H100 GPU 是用于 HPC(高性能计算)的专业卡,基于 NVIDIA Hopper™ GPU 计算架构,内置 transformer Engine,对生成式 AI、大型语言模型 (LLM) 和推荐系统的开发、训练和部署都进行了优化。
与上一代产品 A100 相比,H100 的综合技术创新可以将 LLM 训练速度提高 9 倍,LLM 推理速度提高 30 倍!
另外,NVIDIA H100 是第一款完全异步 GPU。H100 扩展了 A100 跨所有地址空间的全局到共享异步传输,并增加了对张量内存存取模式的支持。它使应用能够构建端到端的异步流水线,将数据移入和移出芯片,在完成计算同时完全隐藏数据搬运。

H100 提供了高达 80GB 的 GPU 显存和 3.35TB/s(H100 SXM)的显存带宽,主要性能规格如下如下表所示。
| GPU 架构 | FP64 算力 | FP64 Tensor Core | FP32 算力 | TF32 Tensor Core | BFLOAT16 Tensor Core | FP16 Tensor Core | FP8 Tensor Core | INT8 Tensor Core | GPU 显存 | GPU 显存带宽 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| H100 PCIe | Hopper | 26 teraFLOPS | 51 teraFLOPS | 51 teraFLOPS | 756 teraFLOPS* | 1513 teraFLOPS* | 1513 teraFLOPS* | 3026 teraFLOPS* | 3026 teraFLOPS* | 80GB HBM2e | 2TB/s |
| H100 SXM | Hopper | 34 teraFLOPS | 67 teraFLOPS | 67 teraFLOPS | 989 teraFLOPS* | 1979 teraFLOPS* | 1979 teraFLOPS* | 3958 teraFLOPS* | 3958 teraFLOPS* | 80GB HBM2e | 3.35TB/s |
*表示采用稀疏技术后的算力情况,不使用稀疏技术时,规格降低一半。
更加详细的规格如下图所示:

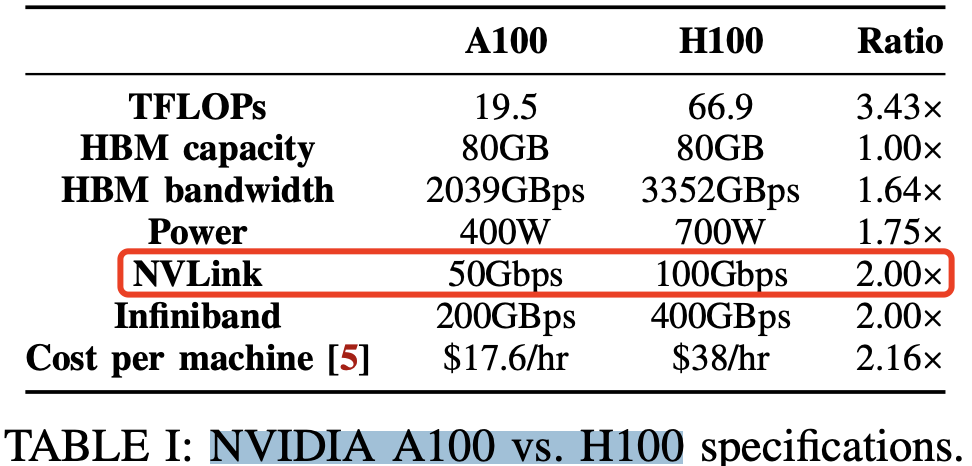
NVIDIA A100 vs. H100 规格表如下所示:
六,V100/A100/H100 计算能力对比
下表比较了不同 NVIDIA GPU 架构之间的计算能力参数。

6.1,英伟达不同架构的 Tensor Core 特性总结
英伟达不同架构的 Tensor Core 特性对比如下表所示:

参考资料
- NVIDIA Volta-Architecture 白皮书-中文版
- NVIDIA Turing-Architecture-Whitepaper
- NVIDIA Ampere Architecture Whitepaper
- NVIDIA Hopper Architecture Whitepaper中文版
- NVIDIA TESLA V100 GPU 加速器数据手册
- NVIDIA A100 GPU 中文数据手册
- NVIDIA H100 GPU 英文数据手册
- NVIDIA H100 GPU 英文数据手册
- Quadro P6000 专业卡数据手册
- Quadro RTX 6000 专业卡数据手册
- Tesla P4 专业推理卡数据手册
- Tesla T4 专业推理卡数据手册
- SIMD < SIMT < SMT: parallelism in NVIDIA GPUs
- Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking - 2018 - Slides (1804.06826).