lightllm 性能瓶颈分析
Categories: Framework_analysis
LightLLM 推理框架静态性能测试及分析
算子占比分析、通信时间对比分析、不同阶段的算子分析。
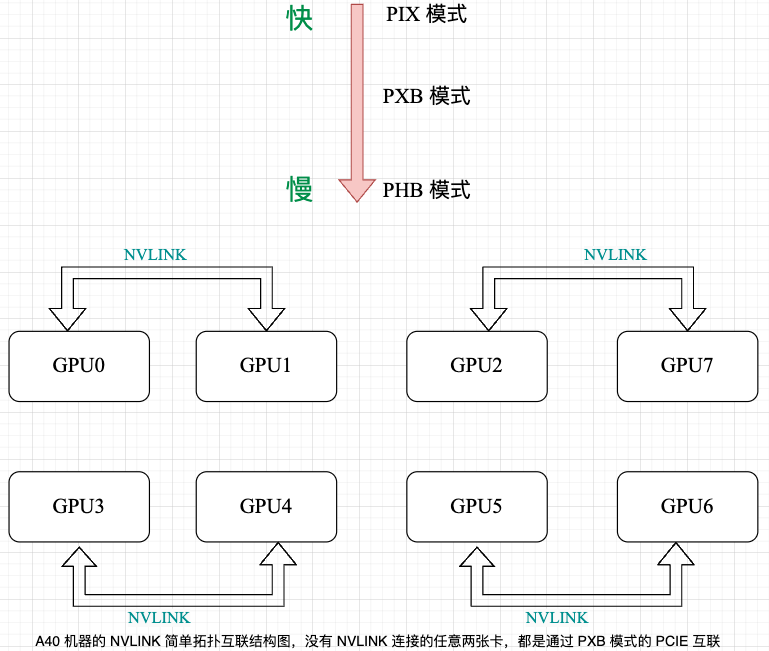
1,之前的问题是因为 Prometheus 工具是 Python 工具没办法统计异步时间,而 cuda 流是异步的,所以统计的 kernel 时间不对。启用 CUDA_LAUNCH_BLOCKING 变量后,可以得到更准确的算子维度的性能数据。 2,A40 机器的简单拓扑互联结构图,卡间互联通信速度对比,注意 A40 机器的 NVLINK 是阉割版的!理论值为 112.5 GB/s。
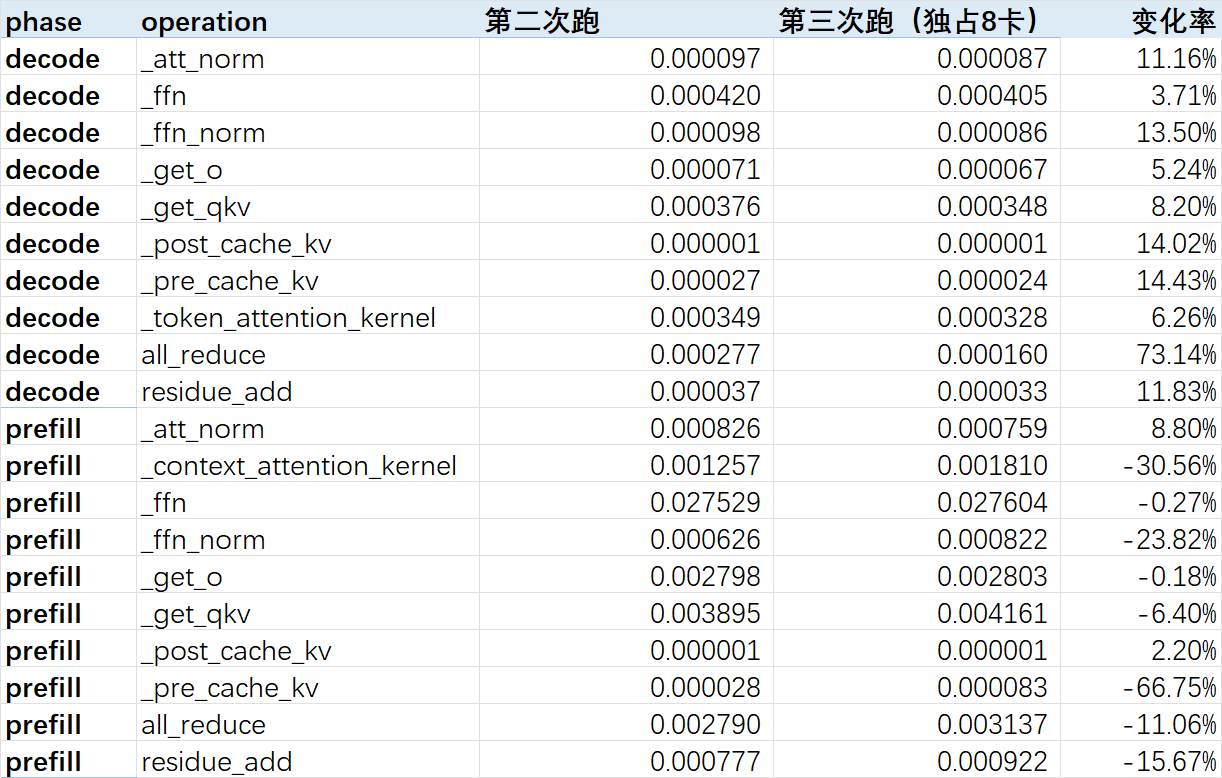
3,备注:集群不稳定的两束证据,尤其是 decode 阶段的 all_duce 通信时间,这个问题很重要!!!如果集群不解决,我们集群的性能数据都得重复测好几次,且结果不稳定。
一、Prefill/Decode 阶段算子执行时间占比情况
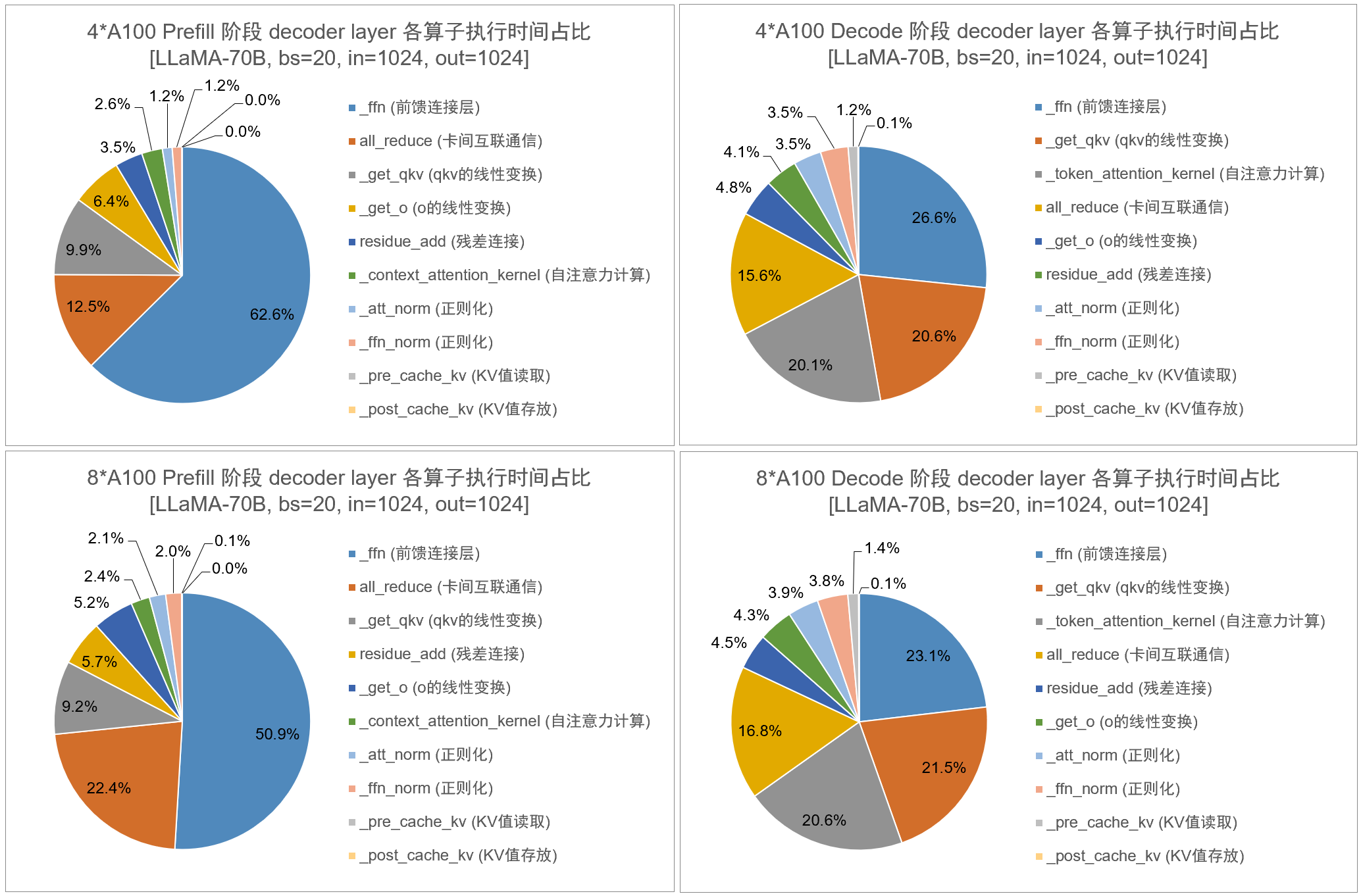
1,将 LLaMA2-70B 模型分别在 4/8 卡 A100-40GB 上部署,设置 batch_size=20, input_length=1024, output_length=1024,统计 prefill/decode 阶段各算子的执行时间占比:
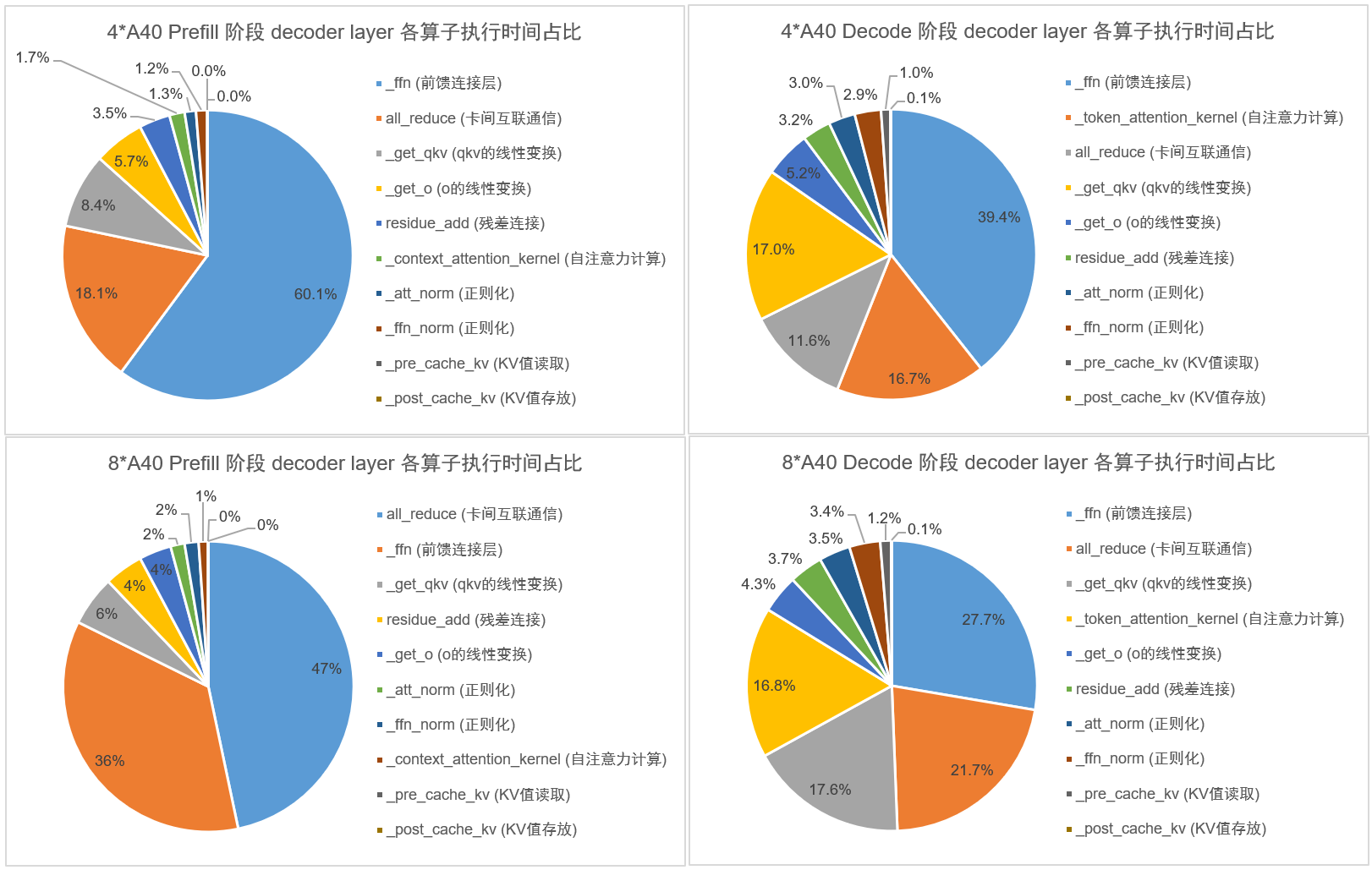
2,将 LLaMA2-70B 模型分别在 4/8 卡 A40-48GB 上部署,设置 batch_size=20, input_length=1024, output_length=1024,统计 prefill/decode 阶段各算子的执行时间占比:
3,将 LLaMA2-7B 模型分别在 4/8 卡 T4-16GB 上部署,设置 batch_size=32, input_length=1024, output_length=1024,统计 prefill/decode 阶段各算子的执行时间占比:
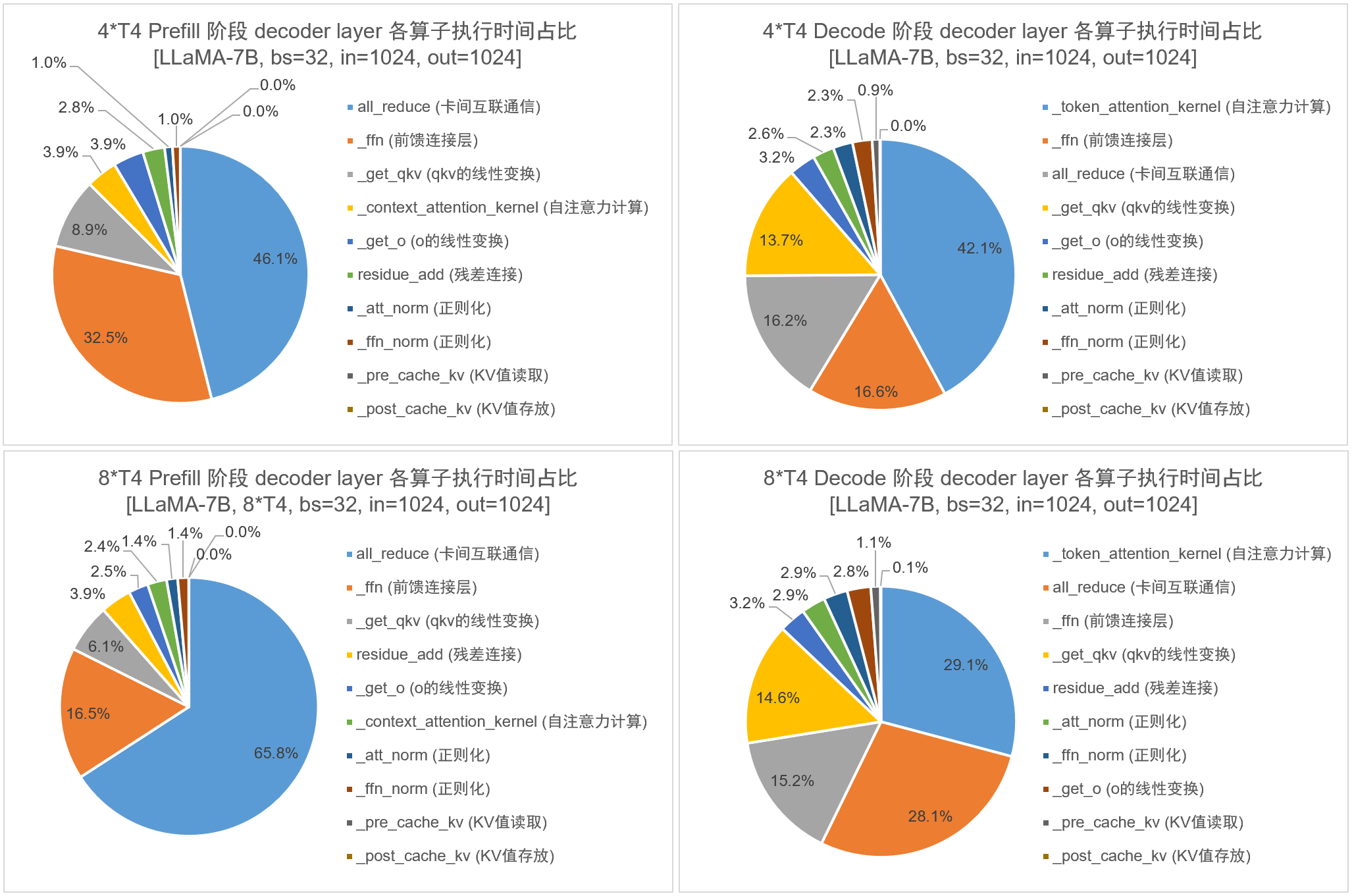
算子开销实验结论:对于 Prefill 阶段:
- 如果在使用 NVLink 互联的卡(A100)上部署模型,则无论 4 卡还是 8 卡,都是 ffn 算子的执行时间占比最高;
- 如果在使用 PCIe 互联的卡(T4)上部署模型,则无论 4 卡还是 8 卡,都是 all_reduce 算子的执行时间占比最高;
- 如果在两两一组 NVLink 互联、其余均为 PCIe 互联的卡(A40)上部署模型,4 卡时是 ffn 算子的执行时间占比最高,而使用 8 卡时转变为 all_reduce 算子的执行时间占比最高。
理论 FLOPs:对于 Prefill 阶段的每个 decoder 层的算子计算量:
- MHA (attention) 层,占计算量大头的是线性变换计算 $Q$、$K$、$V$ 和输出投影矩阵 O: $\text{FLOPs} = 3 \times 2sh^2 + 2sh^2 = 8 sh^2$。
- Feed-forward(MLP/FFN)层的计算量分析:$\text{FLOPs} = 16 sh^2$。
二、4 卡 A100 和 4 卡 A40 对比
实验设计:LLaMA2-70b 模型,输入/输出 tokens 长度都为 1024,batch_size 设为 20,比较 4 卡 A100 和 4 卡 A40 的性能差异。
2.2、推理性能分析结果
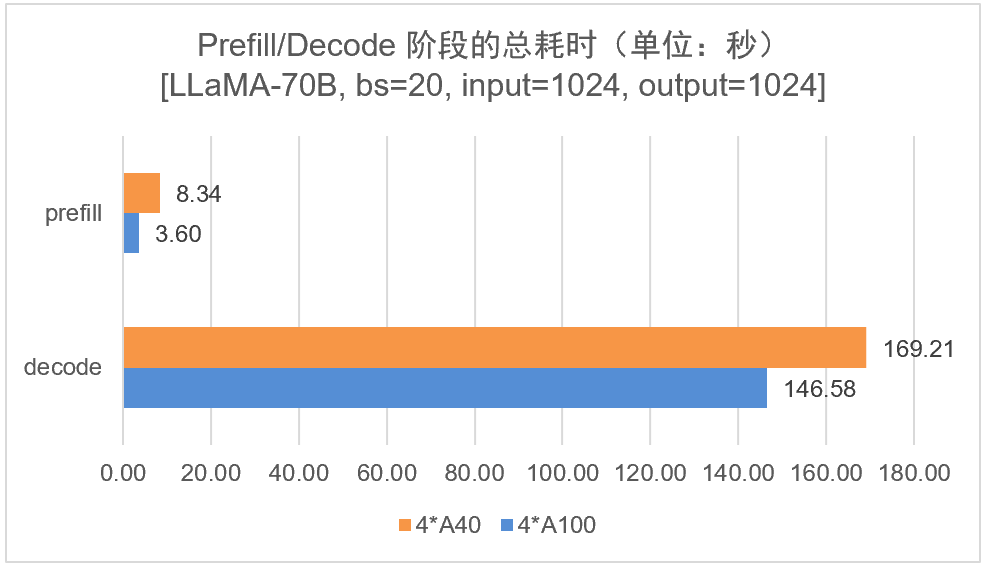
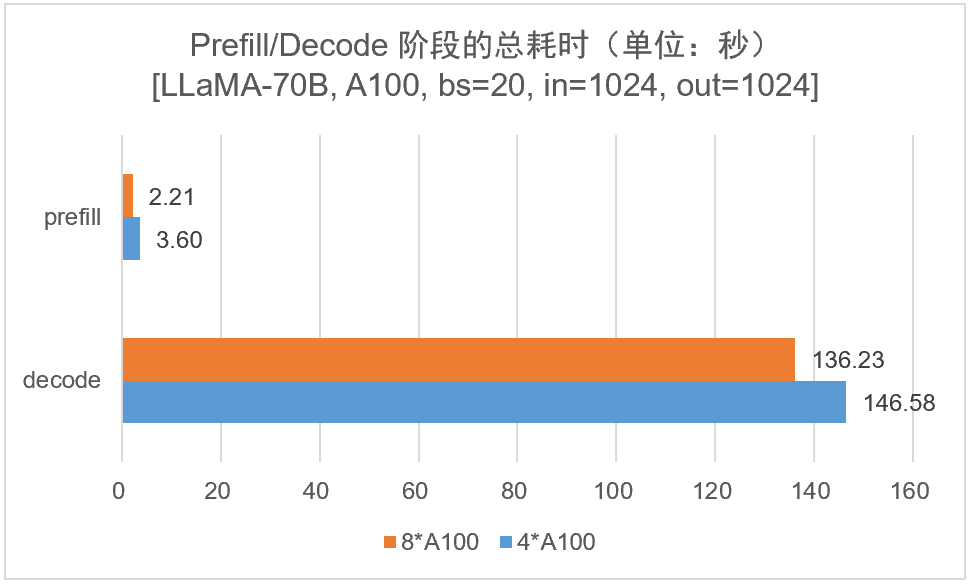
结果分析:在推理层,无论是 prefill 阶段还是 decode 阶段,4 卡 A100 的推理性能都优于 4 卡 A40 的性能。这是符合预期的,因为 A100 在算力、显存带宽、卡间通信方面都优于 A40。另外,4 卡 A100 的 prefill 阶段性能 2 倍于 A40,但是在 decode 阶段性能提升只有 15%,这是否意味着在 Decode 阶段可利用算力更低的 A40 降低成本。
2.3、算子性能分析结果
A100 和 A40 卡的各算子的总耗时情况对比如下图所示,图中也展示了 A100 相对于 A40 的加速比。
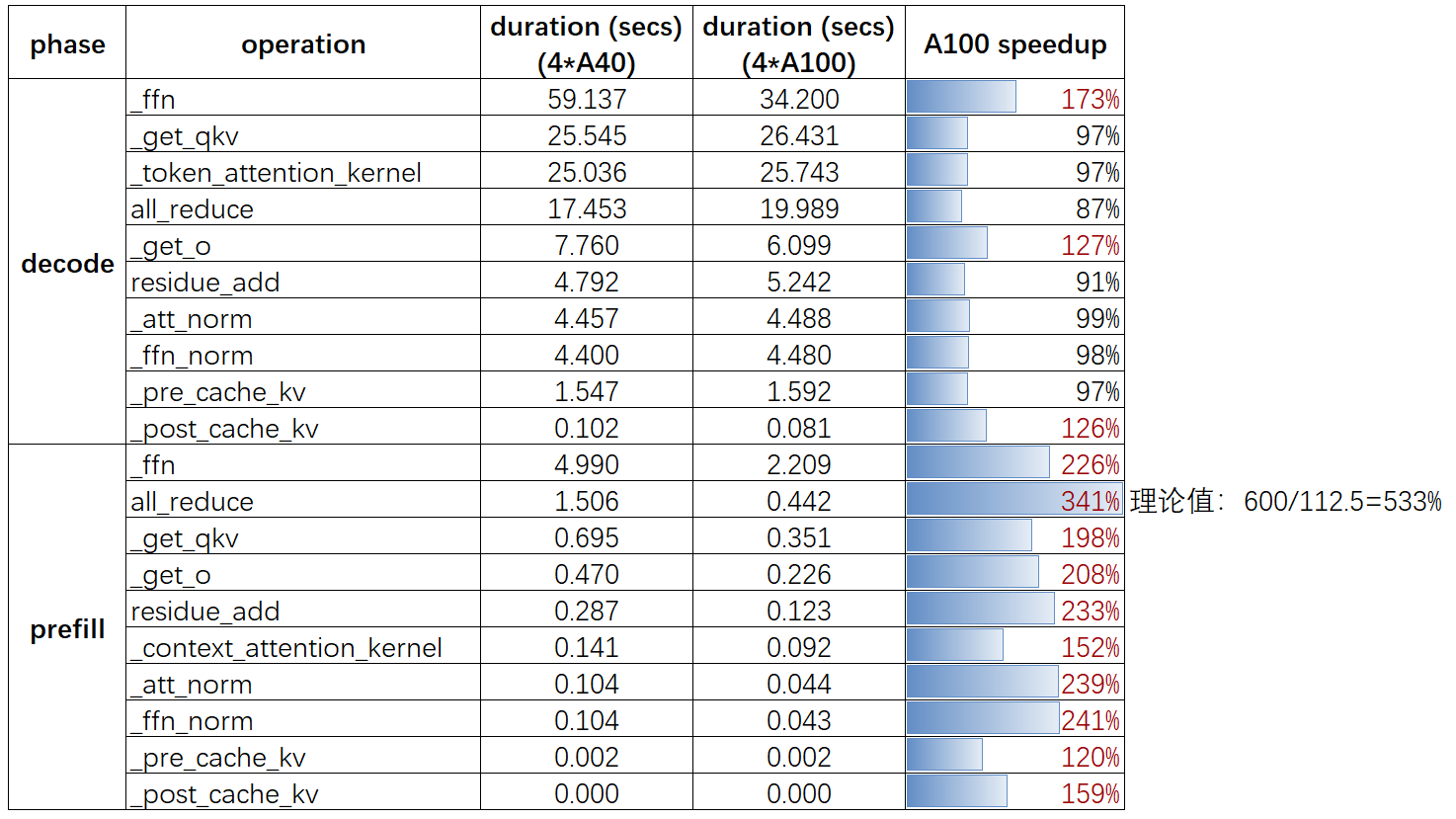
结果分析:
- prefill 阶段 A100 的 all_reduce【卡间互联通信时间】时间比 a40 快了 300%,理论值的对比是 600/112.5 = 5.33,和理论值对比有些差距;decode 阶段 的 all_reduce 时间 4 卡 A40 比 A100 快了
13%左右(异常),可能是集群数据抖动。 - prefill 和 decode 阶段 a100 ffn 算子【纯矩阵运算】比 a40 的计算加速比是 $2.2%$ 和 $1.72$,理论上 a100 比 a40 的算力加速比是 $312/150 = 2.08$,实验结果和理论预估几乎一致。
prefill 阶段 sequence 和 batch_size 都大于 1,算子非访存密集型算子,有利于发挥 Tensor 性能。
三、4 卡 A40 和 8 卡 A40 对比
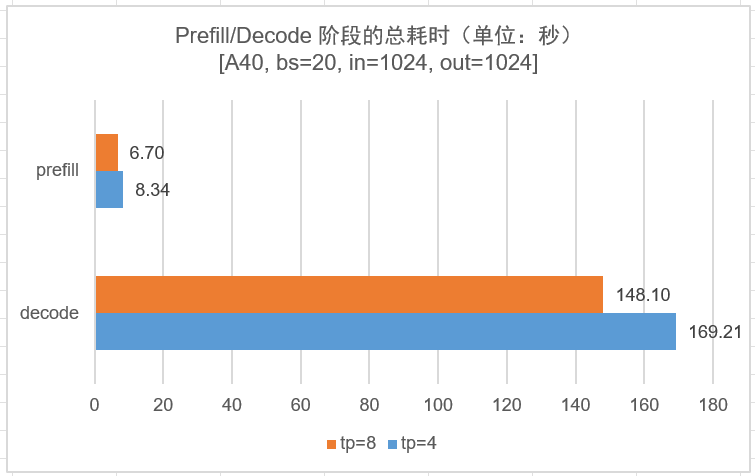
实验设计:llama2-70b 模型,输入/输出 tokens 长度都为 1024,batch_size 设为 20,比较 4 卡 A40 和 8 卡 A40 的性能差异。
3.2、推理性能分析结果
3.3、算子性能分析结果
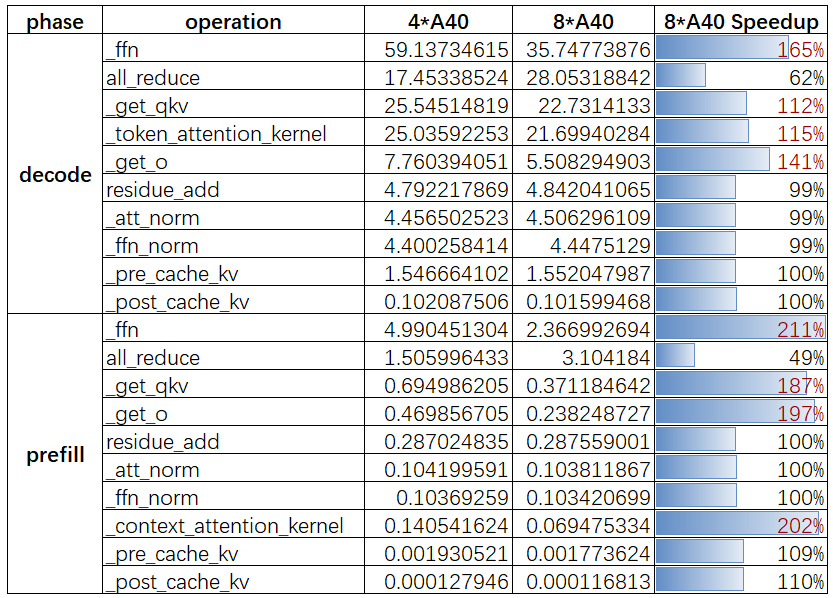
结果分析:
无论是 prefill 还是 decode 阶段:
- 4 卡 A40 的 all_reduce 时间比 8 卡 A40 少了近一半,有待理论分析。
- 4 卡和 8 卡 A40 的占据最大头的 ffn + all_reduce 时间只差了
20%左右。对应的从总的 prefill 和 decode 时间看,8 卡 A40 的最大并发跟 4 卡 A40 的时间也只相差不到25%(8.34/6.7),考虑到最大并发数对首次延时的要求,这就能解释为什么 4 卡/8 卡 A40 支持的最大并发书数目相差无几。
四、4 卡 A100 和 8 卡 A100 对比
实验设计:LLaMA2-70b 模型,输入/输出 tokens 长度均为 1024,batch_size 设为 20,比较 4 卡 A100 和 8 卡 A100 的性能差异。
4.1、推理性能分析结果
4.2、算子性能分析结果
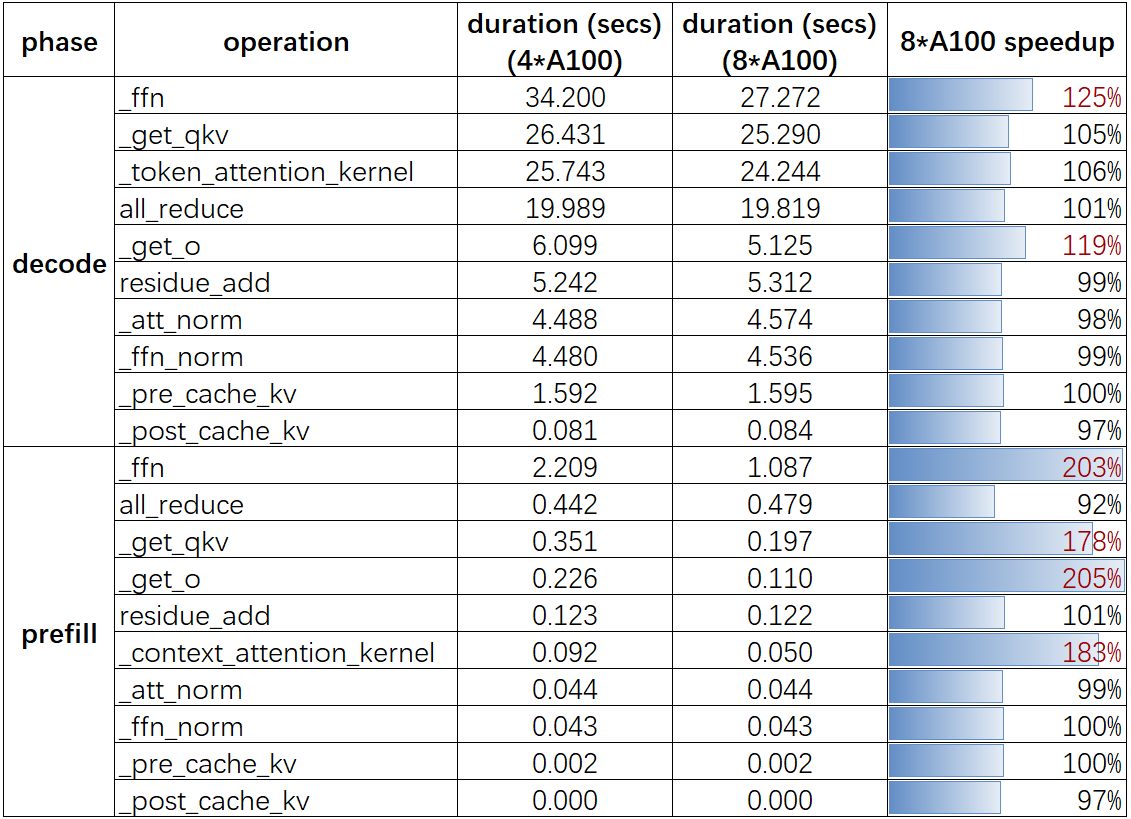
结果分析:
1,对于 A100 卡,增加 TP 数在 prefill 阶段对于大多计算密集型算子上都有近乎线性性能提升。
具体来说,对于纯计算算子(线性层等),使用 8 张 A100 相对于 4 张 A100 能带来接近 2x 的性能提升,这符合预期,因为 8 卡 A100 的算力大约是 4 卡 A100 的两倍;而 decode 阶段,因为 sequence = 1,所以算术(计算)强度比较低,性能受内存带宽限制而不是算力限制,即 GPU 算力无法被充分利用,这也导致 decode 阶段通过增加算力给纯计算算子带来的性能提升并不明显的原因。
总结:长上下文、Llama70B 模型在 Decode 阶段没必要使用高算力机器,但有必要使用高带宽的机器。
奇怪点:8 卡比 4 卡 A100,单个卡的通信和访存变少了,但是为什么 decode 阶段 all_reduce 算子没有性能提升?
2,在 A100 上增加 TP 数不会给 all_reduce 算子带来性能提升,甚至略微降低一点点。
无论 TP = 4 或者 8,每次 llm 推理的总通信量是相同的,都是 4bsh * 2byte。
五、2 卡 A40 上 PCIe 和 NVLink 互联对比
实验设计:LLaMA-7B 模型,输入/输出 tokens 长度都为 1024,batch_size 设为 64,比较 A40 使用 NVLink 通信和使用 PCIe 通信的 2 卡的性能差异。
实验过程:在 8 卡 A40 机器上,GPU0 和 GPU1 是两两一组的 NVLink 通信,但是 GPU0 和 GPU3 之间没有 NVLink 通信,而是使用 PCIE4.0 通信。因此,分别在 A40 的 0,1 号卡和 0,3 号卡上进行测试。
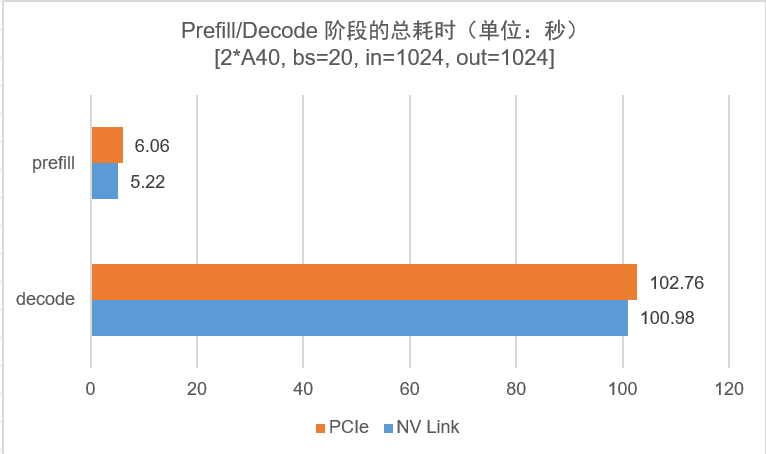
5.1、推理性能分析结果
5.2、算子性能分析结果
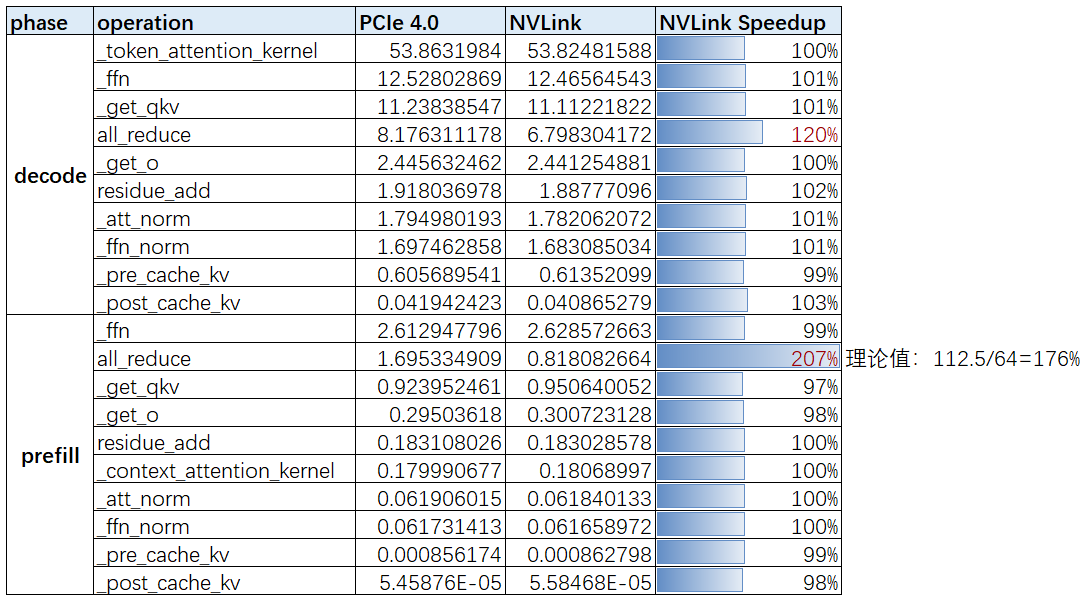
结果分析:
Prefill阶段通信量很大,对于 all_reduce 算子来说,实验中,NVLink互连的卡的 all_reduce 算子时间是 PCIe 的一半,即 A40 的 NVLink 比 PCIe4.0 的实际带宽的加速比为 $2$,而两者的理论带宽加速比是 1.76x。之所以实际加速比超过理论值,是因为,A40 机器的 GPU0 和 GPU3 是 PXB 连接方式【跨过多个 PCIE bridges】,其通信速度略低于PIX模式,即低于理论的 PCIE4.0 的通信带宽。实验结果和理论预估几乎一致。Decode阶段通信量很小,PCIe 互联卡的 all_reduce 时间是 NVLink 互联卡的时间的 1.2 倍(可能是数据抖动的原因),但为什么NVLink通信带来的性能提升不明显呢?
六、总结-lightllm 推理框架性能瓶颈分析实验结论
- PD 分离方案可考虑:
prefill阶段倾向于算力高的机器(PCIE 卡),decode阶段倾向于高带宽(低算力)的机器,从而降低 LLM 推理服务的成本。 - 直接实验例子:4 卡 A100 的 prefill 阶段性能 2 倍于 A40,但是在 decode 阶段性能提升只有 15%(总的 decode 时间),prefill 阶段倾向于算力高的机器(PCIE 卡),decode 阶段倾向于高带宽(低算力)的机器,从而降低 LLM 推理服务的成本。
- 对比 PCIE 通信,
NVLink通信在prefill阶段是能明显提升all_reduce操作性能。但是在decode阶段all_reduce操作时间几乎不变。 - 带
PCIe互联的卡(如 T4 卡和 8 张 A40 卡),prefill 阶段的 all_reduce 时间占比是最大的。 decode阶段,因为sequence = 1,所以算子的算术(计算)强度比较低,即性能受内存带宽限制而不是算力限制(GPU 算力无法被充分利用),所以增加TP数给算子带来的性能提升并不明显。