flashattention3 论文解读
Categories: LLM_Infer_Optimize
介绍
flashattention-2 虽然减少了非矩阵乘法的计算量,提高了运行速度,但是其并未充分利用最新硬件的功能,导致在 H100 GPU 上的利用率仅为 35%,由此作者提出了 flashattention-3,提出了3 项优化策略来提升 Hopper GPU 上的注意力计算性能:
- 通过
warp专用化重叠计算和数据移动,充分利用 Tensor Cores 和 TMA 的异步特性; - 交替进行块级矩阵乘法和 softmax 操作;
- 使用块量化和非一致处理,结合硬件对 FP8 低精度的支持。
展开来说就是:
- 生产者-消费者异步机制:我们提出了一种基于 warp 专门化的软件流水线方案,将数据的生产者和消费者分配到不同的 warp 中,利用 Tensor Cores 的异步执行和数据传输能力,从而延长算法隐藏内存访问延迟和指令调度的时间。
- 在异步块级 GEMM 操作下隐藏 softmax:我们将 softmax 中较低吞吐量的运算(如乘加和指数运算)与异步 WGMMA 指令(用于矩阵乘法)进行重叠处理。在这一过程中,我们重新设计了 FlashAttention-2 的算法,以减少 softmax 和矩阵乘法之间的依赖。例如,在我们的两阶段算法中,softmax 操作一块分数矩阵时,WGMMA 异步执行下一块的计算。
- 硬件加速的低精度 GEMM:我们调整了前向计算算法,使其能够利用 FP8 Tensor Cores 进行矩阵乘法,从而使实际测得的 TFLOPs/s 几乎翻倍。这要求在内存布局上解决 FP32 累加器和 FP8 操作数矩阵块的不同要求。为此,我们使用块量化和不相干处理技术来降低精度损失的影响。
flashattention-3:算法改进
解码中的多头注意力机制
在解码过程中,每个新生成的 token 需要关注所有之前生成的 token,以计算:softmax(queries @ keys.transpose) @ values。
在训练时,FlashAttention(最近发布的 v1 和 v2 版本)已经对这一操作进行了优化,主要瓶颈在于读取和写入中间结果所需的内存带宽(例如 Q @ K^T)。但是,这些优化无法直接应用于推理过程中,因为推理中的瓶颈和训练不同。在训练中,FlashAttention 在批量大小和查询长度维度上进行了并行化处理。而在推理中,查询的长度通常是 1,这意味着如果批量大小小于 GPU 上流处理器(SM)的数量(A100 GPU 上有 108 个 SM),那么该操作只能使用一小部分 GPU!尤其是在使用较长的上下文时,由于需要更小的批量大小以适应 GPU 内存,批量大小为 1 的情况下,FlashAttention 的 GPU 利用率不到 1%。
的情况下,FlashAttention1-2 的注意力计算的并行过程可视化如下图所示:

可以看出,FlashAttention 只在查询块和批次大小维度上进行并行处理,因此在解码过程中无法充分利用 GPU 的全部计算资源。
一种更快的解码注意力机制:Flash-Decoding
本文提出的新方法 Flash-Decoding 基于 FlashAttention,并增加了一个新的并行化维度:键/值的序列长度。它结合了上述两种方法的优点。与 FlashAttention 一样,它将非常少量的额外数据存储在全局内存中,但只要上下文长度足够长,即使批次大小很小,也能充分利用 GPU。
Flash-Decoding 在前作对 batch size 和 query length 并行的基础上增加了一个新的并行化维度:keys/values 的序列长度,代价是最后一个小的归约步骤。
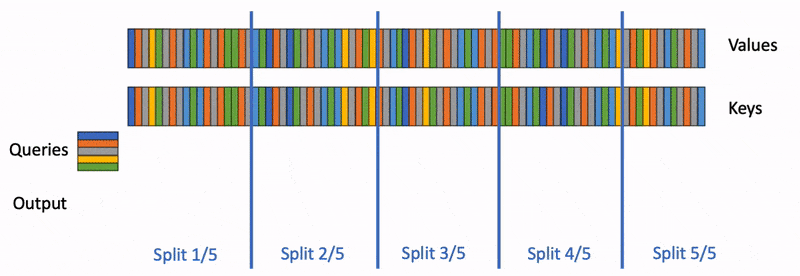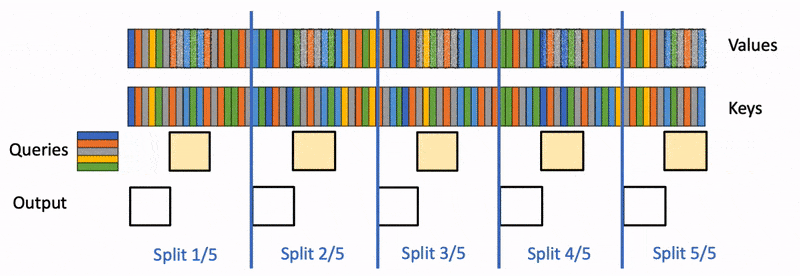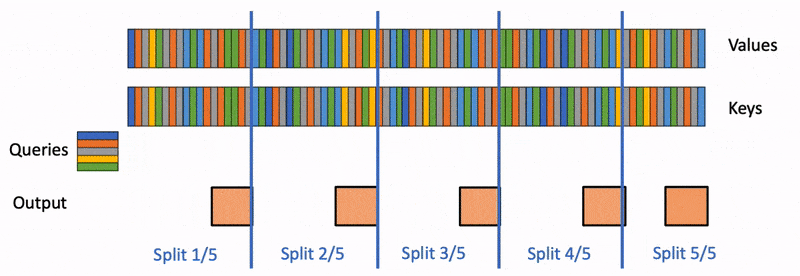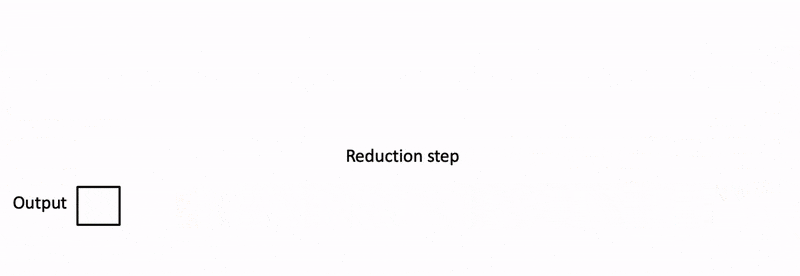
Flash-Decoding 的工作流程分为三个步骤:
- 首先,将键/值拆分成更小的块。
- 然后,使用 FlashAttention 并行计算查询与每个拆分块的注意力值,同时为每行和每个块记录一个额外的标量:注意力值的 log-sum-exp。
- 最后,通过对所有拆分块进行归约,结合 log-sum-exp 调整各个块的贡献,计算出最终的结果。
上述步骤之所以可行,是因为注意力/softmax 可以迭代计算(前作的贡献)。在 Flash-Decoding 中,它在两个层次上使用:在拆分内(类似于 FlashAttention)和跨拆分来执行最终归约。
实际上,步骤 (1) 不涉及任何 GPU 操作,因为键/值块是完整键/值张量的视图。接下来,我们有两个独立的内核分别执行步骤 (2) 和 (3)。
总结
Flash-Decoding 主要是针对 llm 推理的加速,在 batch_size 较小和序列长度较大时有着明显的加速效果,且性能对序列长度的增加并不敏感。