flashattention1-2-3 系列总结
Categories: LLM_Infer_Optimize
1. Online Softmax
Original Softmax
1,Naive softmax
给定输入向量 $\mathbf{x} = [x_1, x_2, \dots, x_N]$,$Softmax(x)$ 函数的输出定义为(默认对行进行 Softmax。):
Naive Softmax 算法主要包括两个步骤,其算法实现步骤和 FLOPs 分析如下:

- 计算归一化项 $dn$:先对矩阵每个元素都需要进行指数运算,涉及
FLOPs为 $N^2$(逐元素操作),假设是对每一行进行Softmax,每一行有 $N$ 个元素,需要进行 $N - 1$ 次加法,矩阵总共有 $N$ 行,因此需要 $s\times(N - 1)$ 次加法,最后计算归一化项 $d_N$ 的FLOPs为 $2N^2N$ - 计算 softmax 输出:分为两步进行每个元素都需要除以所在行的总和,总共 $N^2$ 个元素,
FLOPs为 $N^2$。
综上,Native Softmax 的总 FLOPs 为:
算法的 python 代码实现和其对 global memory 的访存量 MAC 数值如下所示:
"""
在 attenion 算子中, softmax 函数的输入 QK^T, 输入矩阵大小就是 [s,s]
"""
# [N, N] -> [N, N], 每个元素进行 3 次内存访问:2次读取和一次写入.
# mac = 3N^2, flops = 3N^2 - N
def native_softmax(x):
s, s = x.shape # 第一个维度是序列长度,第二个维度是隐藏层大小
output = np.array(x) # np.array() 将 python 中的数据结构(如列表、元组等)转换为 NumPy 的数组
for r in range(s):
sum = 0
for i in range(s):
sum += np.exp(x[r][i])
for i in range(s):
output[r][i] = np.exp(x[r][i]) / sum
return output
2,Safe Softmax
和 Native Softmax 相比,Safe Softmax 为了防止数值溢出还需要将 $x_i$ 再额外减掉一个 max 最大值:
Safe Softmax 涉及三个步骤,其算法实现步骤和 FLOPs 分析如下:

- 对每行求最大值:遍历每行元素,做 $N-1$ 次比较,得到每行元素的最大值,总共 $N$ 行,因此该操作涉及
FLOPs为 $N(N-1)$ - 计算指数并求和得到归一化项 $d_N$:将每个元素减去最大值后,再计算指数,这个过程是逐元素操作,
FLOPs为 $N^2 + N^2$。对每行进行求和,每行进行 $N - 1$ 次加法,整个矩阵共 $N\times(N - 1)$ 次加法。 - 计算 softmax 输出:将每个元素减去最大值后,再计算指数,最后除以行总和,需要 $2N^2$ 次除法。
值的注意的是,这里计算 max 需要一次独立的全局 reduce,计算分母的 sum 再需要一次独立的全局 reduce,最后分别计算每一个元素的 softmax 值。三个步骤之间存在数据依赖。
结合前面 Native Softmax 的 FLOPs 计算,再加上对每行求最大值的操作,可知 Safe Softmax 总 FLOPs:
Safe Softmax 算法的 python 代码实现和其对 global memory 的访存量 MAC 数值如下所示:
# [N, N] -> [N, N], 每个元素进行 4 次内存访问:3次读取和一次写入.
# mac = 4N^2, flops = 4N^2 - 2N
def safe_softmax(x):
s, s = x.shape # 第一个维度是序列长度,第二个维度是隐藏层大小
output = np.array(x) # np.array() 将 python 中的数据结构(如列表、元组等)转换为 NumPy 的数组
for r in range(s):
max_r = 0
for i in range(s):
max_r = max(max_r, x[r][i]) # flops 为 1
sum = 0
for i in range(s):
sum += np.exp(x[r][i] - max_r) # flops 为 2 + 1
for i in range(s):
output[r][i] = np.exp(x[r][i] - max_r) / sum # flops 为 2
return output
IO 复杂度分析:Safe Softmax 需要 $3$ 个独立的循环对输入向量进行了三次遍历:第一次计算最大值 $m_N$,第二次计算归一化项 $d_N$,第三次计算最终值 $softmax_i$,再加上将结果写回内存中,这导致每个向量元素需要 4 次内存访问,即 Safe Softmax 算法的内存访问(MAC)偏大,即 softmax 函数的 HBM 访问次数为 $4N^2$,和序列长度呈二次方关系。
Online Softmax
从 Safe Softmax 公式很明显看出,MAC 大原因是因为存在数据依赖:
- 公式 (2) 需要依赖 $m_N$;
- 公式 (3) 则需要依赖 $m_N$ 和 $d_N$。
但如果能同时计算最大值 $m$ 和归一化项(normalization term)$d$,即在一个 for 循环中得到最终的 $m_N$ 和 $d_N$,则能直接减少 HBM 的访问次数(MAC),又因为 Softmax 典型情况都是内存受限,所以这肯定能提高 Softmax 算子的运行速度。
Online normalizer calculation for softmax 论文将 3 步 safe softmax 合并成 2 步完成的方法,并证明了 $d_i’$ 存在如下递推性质:
\[\begin{aligned} d_i' &= \sum^i_{j=1}e^{x_j - m_i} \\ &= \sum^{i-1}_{j=1}e^{x_j - m_i} + e^{x_i-m_i} \\ &= \left ({\sum^{i-1}_{j=1}e^{x_j - m_{i-1}}} \right ) * e^{m_{i-1} - m_i} + e^{x_i-m_i} \\ &= d_{i-1}'* e^{m_{i-1} - m_i} + e^{x_i-m_i} \\ \end{aligned}\]即 $m_i$ 和 $d_i’$ 可以在一个 for 循环中计算并更新,这样 softmax 的实现就可以通过两个 for 循环完成,即两步 softmax,Online Softmax 计算公式如下:
这里 $m_j$ 和 $d_j$, 可以在一个 for 循环中同时实现,或者说在一个 kernel 中计算完成;$m_N$ 和 $d_N$ 是全局的最大值和归一化项。其算法实现过程如下所示:

如果想继续优化,则使用分块技术计算归一化常数,假设 $x = [x_1,x_2], y = [x_3, x_4]$,$m_{xy} = \text{max}(m_x, m_y)$定义分块计算:
\[d_{xy} = d([x^{},y]) = d_x * e^{m_x - m_{xy}} + d_y * e^{m_y - m_{xy}}\]分块计算完 $m$ 和 $d$ 之后,再将所有子块结果重新聚合得到全局结果 $m_N$ 和 $d_N$,其和串行顺序计算结果在数学上完全等价。
算法分析和公式证明过程,本文不再描述,感兴趣的可以看我上一篇文章-《online-softmax 论文解读》。
这篇论文在算法上其实有两个创新:
- 提出并证明了通过一次遍历输入数据来计算 Softmax 函数归一化项的方法,该方法将 Softmax 函数的内存访问次数减少了 $1.33 (4/3 = 1.33)$倍
- 证明了可以分块计算归一化常数,这个方法可以发挥 GPU 多线程的特性。
这里针对上面两个创新,我分别给出 online softmax 算法的 python 代码实现以及 global memory 的访存量 MAC。
import numpy as np
import torch.nn.functional as F
import torch
def online_softmax_update(m0, d0, m1, d1):
# x 1
m = max(m0, m1) # flops: 1
d = d0 * np.exp(m0 - m) + d1 * np.exp(m1-m) # flops: 5
return m, d
# [N, N] -> [N, N], 每个元素进行 3 次内存访问:2 次读取和一次写入.
# mac = 3N^2, flops = 8N^2
def online_softmax(x):
s, s = x.shape
output = np.array(x)
for r in range(s):
m = x[r][0]
d = 1
for j in range(1, s):
m, d = online_softmax_update(m, d, x[r][j], 1) # flops 为 6
for i in range(s):
output[r][i] = np.exp(x[r][i] - m) / d # flops 为 2
return output
# [N, N] -> [N, N], 每个元素进行 3 次内存访问:2 次读取和一次写入.
# mac = 3N^2, flops = 8N^2,分块计算,可发挥并行计算优势
def block_online_softmax(x, block_size=256):
assert x.shape[1] % block_size == 0
s, s = x.shape
output = np.array(x)
for r in range(s):
m = x[r][0]
d = 0
# 可使用多线程并行计算,实际 mac 为 N^2
for b in range(0, s // block_size):
# Calculate m,d of single block
m_block = x[r][b*block_size]
d_block = 0
for j in range(0, block_size):
m_block, d_block = online_softmax_update(m_block, d_block, x[r][b*block_size + j], 1)
# Merge all block's result to total
m, d = online_softmax_update(m, d, m_block, d_block)
for i in range(s):
output[r][i] = np.exp(x[r][i] - m) / d
return output
if __name__ == "__main__":
x = np.random.randn(1024, 1024)
# 对每一行执行 softmax 操作
pytorch_softmax_out = F.softmax(torch.tensor(x), dim=1) # dim=0表示按列计算;dim=1表示按行计算。
native_softmax_out = native_softmax(x)
safe_softmax_out = safe_softmax(x)
online_softmax_out = online_softmax(x)
block_online_softmax_out = block_online_softmax(x, 256)
if torch.allclose(pytorch_softmax_out, torch.tensor(native_softmax_out), atol=1e-4):
print("naive softmax 与 PyTorch softmax 结果一致!")
else:
print("naive softmax safe_softmax 与 PyTorch softmax 结果不一致!")
if torch.allclose(pytorch_softmax_out, torch.tensor(safe_softmax_out), atol=1e-4):
print("safe softmax 与 PyTorch softmax 结果一致!")
else:
print("safe softmax 与 PyTorch softmax 结果不一致!")
if torch.allclose(pytorch_softmax_out, torch.tensor(online_softmax_out), atol=1e-4):
print("online softmax 与 PyTorch softmax 结果一致!")
else:
print("online softmax 与 PyTorch softmax 结果不一致!")
if torch.allclose(pytorch_softmax_out, torch.tensor(block_online_softmax_out), atol=1e-4):
print("block online softmax 与 PyTorch softmax 结果一致!")
else:
print("block online softmax 与 PyTorch softmax 结果不一致!")
程序运行后输出结果如下所示:
naive softmax 与 PyTorch softmax 结果一致! safe softmax 与 PyTorch softmax 结果一致! online softmax 与 PyTorch softmax 结果一致! block online softmax 与 PyTorch softmax 结果一致!
2. FlashAttention-v1
2.1 标准注意力
给定输入二维矩阵 $Q, K, V \in \mathbb{R}^{N\times d}$,其中 $N$ 是输入序列的长度,$d$ 是自注意力机制头的长度,Softmax 是按行应用的,注意力输出矩阵 $O \in \mathbb{R}^{N\times d}$ 的计算公式如下:
\[\text{S = QK}^\text{T} \in \mathbb{R}^{N\times N},\quad \text{P = softmax(S)} \in \mathbb{R}^{N\times N},\quad \text{O = PV}\in \mathbb{R}^{N\times d}\]
标准的 Attention 运算大致可以描述为以下三个步骤:
- 将 $Q, K$ 矩阵以块的形式从
HBM中加载到SRAM中,计算 $S=QK^T$,将 $S$ 写入到HBM中。 - 将 $S$ 矩阵从
HBM中加载到SRAM中,计算 $P = Softmax(S)$,将 $P$写入到 HBM 中。 - 将 $P, V$ 矩阵以块的形式从 HBM 中加载到 SRAM 中,计算 $O=PV$, 将 $O$ 写入到 HBM 中。
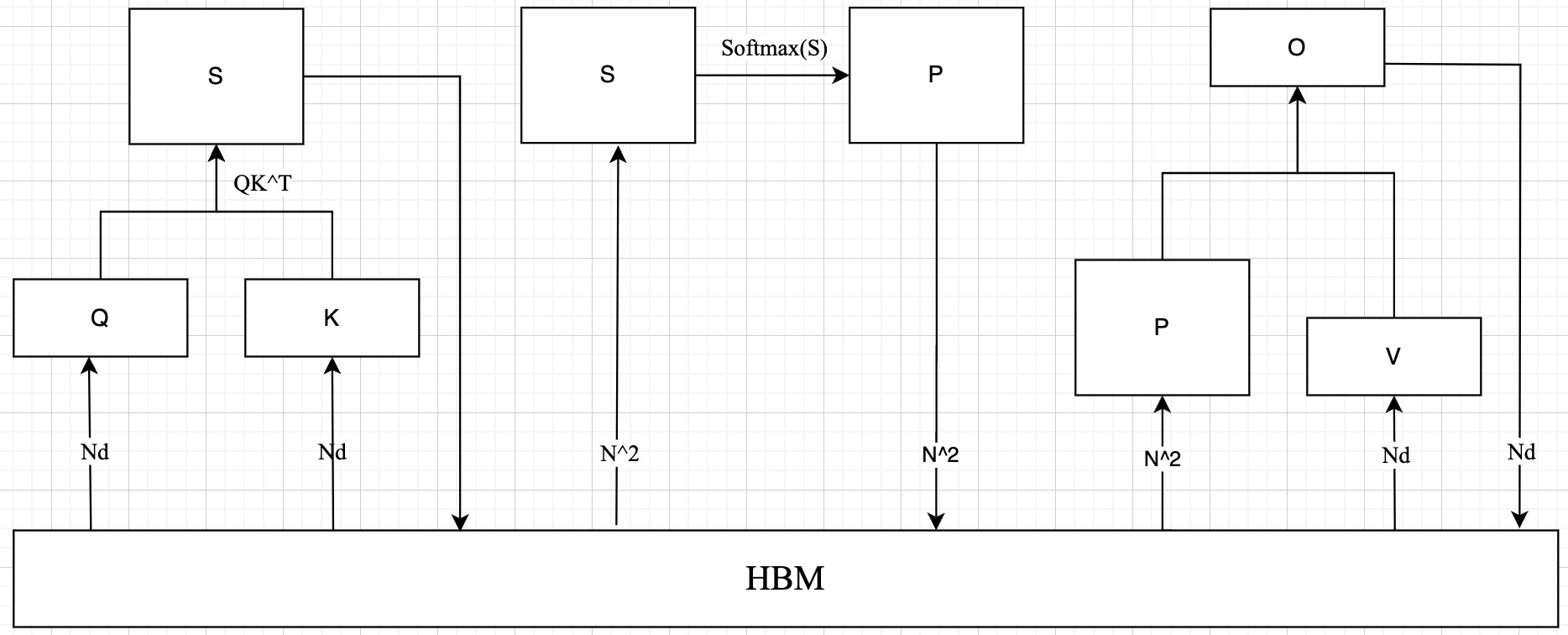
self-attention 算子涉及到的和 HBM 数据传输过程如上图所示,很明显需要从HBM 中读取 5次,写入 HBM 3 次,HBM 访存量 $MAC = 4N^2 + 3Nd$,很明显标准注意力的 HBM 访问代价(MAC)随序列长度增加呈二次方增长。
而 self-attention 的计算量为 $4N^2d$,标准注意力算子的操作强度 = $\frac{4N^2d}{4N^2 + 3Nd}$。公式可看出,标准注意力算子是一个很明显的内存受限型算子。一个实际模型的 self-attention 算子的内存访问代价和计算量分析如下图所示,从下图也可以看出 self-attention 算子操作强度近乎为 1,明显是内存受限的。

2.2 Roofline
Roofline 性能分析模型是一种用于衡量和分析计算性能的工具,通过将应用程序的实际计算性能与硬件的理论峰值性能进行对比,以揭示应用是受到计算性能的限制还是受到内存带宽的限制,这里的内存带宽是指芯片外内存带宽。
Roofline 模型的有两个关键指标:操作强度和性能上限。操作强度定义:每字节内存数据传输所对应的操作次数,即每字节 flops,单位一般为 GFlops/sec。Roofline 模型将浮点运算性能、操作强度和内存性能整合在一个二维图中。浮点运算的峰值性能可以通过硬件规格或微基准测试得出。
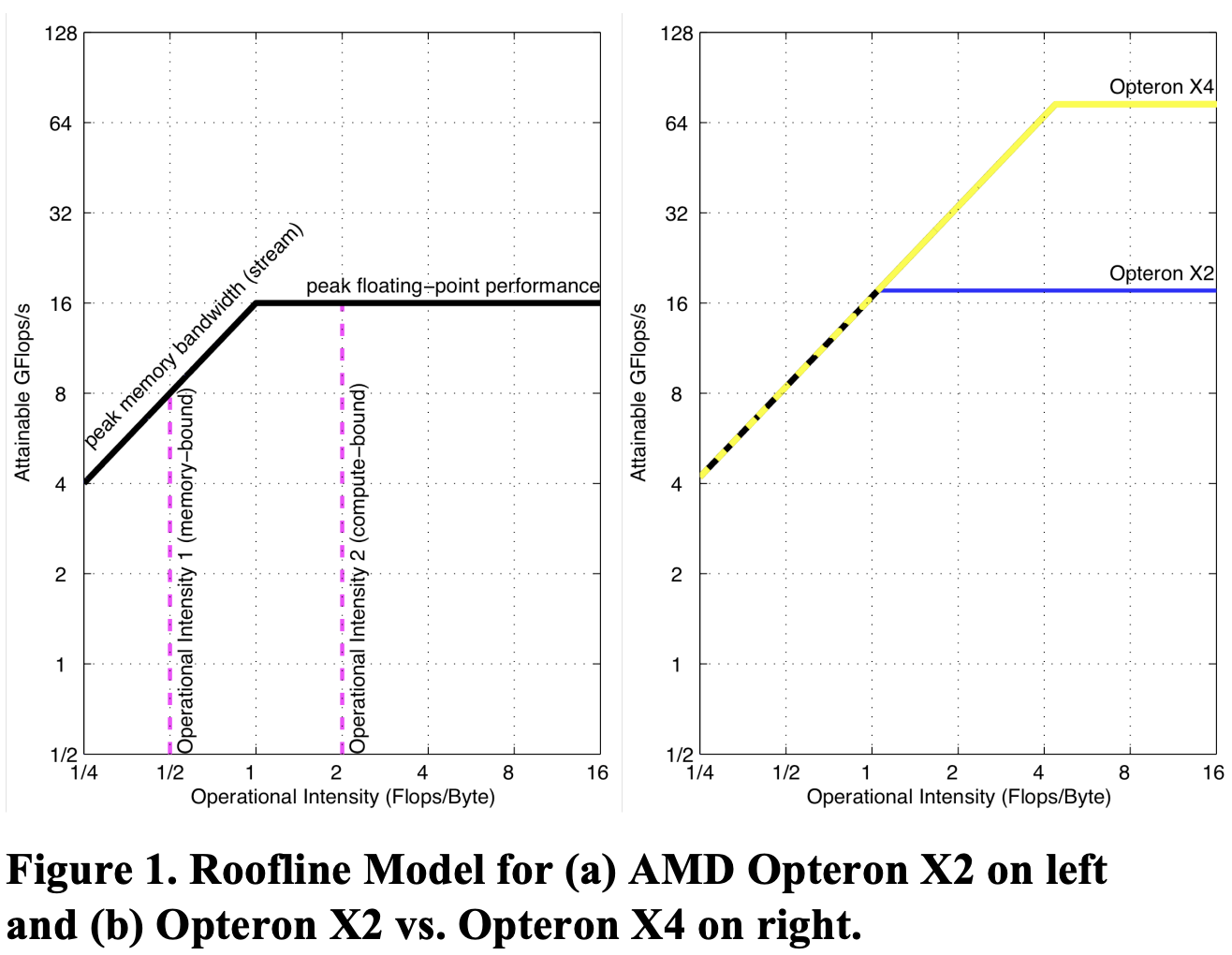
图表采用对数-对数刻度,Y 轴为可实现的浮点性能,X 轴为操作强度,范围从每 1/4
Flops/DRAM 字节到 16Flops/DRAM 字节。Operational Intensity, OI, 也称算术强度 Arithmetic Intensity。
计算机内存系统在不同操作强度下支持的最大浮点性能的计算公式:
\[\text{可实现的 GFlops/sec} = \text{Min(峰值浮点性能,峰值内存带宽 x 操作强度)}\]Roofline 模型有两个作用:
- 上限分析:为浮点程序性能设定了一个上限(水平线)。
- 瓶颈分析:比较浮点程序的操作强度硬件的操作强度,判断程序是处于内存还是计算受限。
FlashAttention 论文就是基于 Roofline 模型分析了 self-attention 层处于内存受限状态,从而得到了减少 HBM 访问次数的思路。
2.3 SRAM
FlashAttention 论文中说的 SRAM 是指哪种 GPU 内存类型?
1,可以从 cuda 编程和算法角度理解 SRAM 是 L1 Cache (数据缓冲)。
FlashAttention 核心是分块计算注意力,可以简单理解为就是将输入张量划分成很多块,每个数据块放到 sm 里面去计算(cuda/triton 编程的核心就是在于如何将数据分块),sm 里面 L1 cache/共享内存的大小基本就决定了 这个数据块的上限空间大小,所以论文里面说的 SRAM 大小其实值的是 L1 Cache 大小,L2 Cache 是所有 SM 能共同访问的,明显不是论文里指的 SRAM。
2,可以从 GPU 内存层次角度直接看出 SRAM 是 L1 Cache (数据缓冲)。
论文 2.1 节明确都说了 A100 的 SRAM 大小是 192 KB,而英伟达官网给出的 A100 白皮书也明确说了 A100 的 L1 cache 大小是 192KB( 组合共享内存和 L1 数据缓存),所以论文的 SRAM 肯定指的是 L1 cache 了。值得注意的是,从 A100 开始 L1 Cahce 和 shared memory 合并了, 即 Flash attention 中 SRAM 指的就是 L1 cache/shared memory。
“As an example, the A100 GPU has 40-80GB of high bandwidth memory (HBM) with bandwidth 1.5-2.0TB/s and 192KB of on-chip SRAM per each of 108 streaming multiprocessors with bandwidth estimated around 19TB/s [44, 45].”
3, 当硬件开始计算时,会先从显存(HBM)中把数据加载到片上(SRAM),在片上(SRAM)进行计算,然后将计算结果再写回显存中。
2.4 Tiling
computations block by block。
Online Softmax 实现在一个 for 循环中计算 $m_i$ 和 $d_i$,FlashAttention-v1 基于它的思想更进一步,实现在一个 for 循环中计算 $m_i$、$d_i$ 和注意力输出 $O_i$,也就是说,在一个 kernel 中实现 attention 的所有操作。再通过分块 Tiling 技术,将输入的 Q、K、V 矩阵拆分为多个块,将其从较慢的 HBM 加载到更快的 SRAM 中,从而大大减少了 HBM 访问次数(内存读/写的次数),然后分别计算这些块的注意力输出,最后,将每个块的输出按正确的归一化因子缩放之后相加后可得到精确的注意力输出。
注意力输出 $O_i$ 的迭代更新公式在算法 1 第 12 行,公式的推导证明在附录 C 中。
\[O_i \leftarrow \text{diag}(\ell_i^{\text{new}})^{-1} (\text{diag}(\ell_i) e^{m_{i} - m_i^{\text{new}}}O_i + e^{\tilde{m}_{ij} - m_i^{\text{new}}} \tilde{P}_{ij} V_j)\]这里原论文给出的推导不是很容易看懂,我参考文章给出了推导证明,其证明了 $O_i$ 的计算也是可以同时满足交换律和结合律,任意分块分别计算 $M$、$D$ 和 $O$ 之后,将所有子块结果重新聚合在数学上完全等价,从而实现在一个 $i = (0,N)$ 的循环中计算 $M_i$、$D_i$ 和 $O_i$。
回到一开始的标准 attention,将 online-softmax 算法套进去,这里的 Softmax 是对 $QK^T \in [N, N]$ 结果中的每一行做一维的 softmax;用大写 $M、D$ 表示最大、归一化项,它们的长度都为 $N$;$O\in [N,d]$ 表示注意力输出。计算公式如下:
\[\begin{aligned} S_{r, i} &= \sum^{d}_{j=0}Q_{r,j}K_{j,i}\\ M_{r, i} &= \max(M_{r, i-1}, S_{r, i}), \quad D_{r, i}' = D_{r, i-1}' * e^{M_{r, i-1} - M_{r, i}} + e^{S_{r, i}-M_{r, i}}, \\ P_{r, i} &= \frac{e^{S_{r, i} - M_{r, N}}}{D_{r, N}'}, \\ O_{r, c} &= \sum^N_{i=0}(P_{r, i} * V_{i, c}) \end{aligned}\]对应代码如下:
def online_softmax_update(m0, d0, m1, d1):
# x 1
m = max(m0, m1) # flops: 1
d = d0 * np.exp(m0 - m) + d1 * np.exp(m1-m) # flops: 5
return m, d
def flashattn_0(Q, K, V):
N, Dim = Q.shape
# 1, Load Q K and write S. and Compute S[r][i] by matrix multiply
S = np.zeros([N, N], "float32")
for r in range(0, N):
for i in range(0, N):
for j in range(0, Dim):
S[r][i] += Q[r][j] * K[i][j] # K^T 的列就是 K 的行
# 2, Load S and write O. Compute softmax[i] and O[r][c]
O = np.zeros([N, Dim], "float32")
for r in range(0, N):
m = S[r][0]
d = 1
for i in range(1, N):
m, d = online_softmax_update(m, d, S[r][i], 1) # flops 为 6
softmax = np.zeros([N], "float32")
for i in range(0, N):
softmax[i] = np.exp(S[r][i] - m) / d
for c in range(0, Dim):
for i in range(0, N):
O[r][c] += softmax[i] * V[i][c] # V[i][c] 的加载不连续
return O
将 online softmax 应用到标准 attention 后,Softmax 的 HBM 访存减少了,但还能不能继续优化,在一个 for 循环内完成注意力 O[r][c] 的计算呢?就像 online-softmax 那样,实际是可以的。
$O_{r,c}$ 的计算是一个累加过程,拆开来看:
\[\begin{aligned} O_{r,c, i} &= O_{r,c, i-1} + Softmax_{r, i} * V[i, c] \\ &= O_{r,c, i-1} + \frac{e^{S_{r, i} - M_{r,N}}}{D'_{r,N}} * V[i, c] \\ &= \sum_{j=1}^i \frac{e^{S_{r, j} - M_{r,N}}}{D'_{r,N}} * V[j, c] \end{aligned}\]可以发现 $O_{r, c, i}$ 依赖于 $M_{r, L}$ 和 $D_{r, L}’$,类比 Online Softmax 求解归一化项的技巧,我们使用迭代的方式求解 $O_{r,c,i}$,可以用数学归纳法证明:
\[\begin{aligned} O'_{r,c, i} &= \sum_{j=1}^i \frac{e^{S_{r, j} - M_{r, i}}}{D'_{r, i}} * V[j, c] \\ &= \sum_{j=1}^{i-1} \frac{e^{S_{r, j} - M_{r, i}}}{D'_{r,i}} * V[j, c] + \frac{e^{S_{r, i} - M_{r, i}}}{D'_{r,i}} * V[i, c] \\ &= \sum_{j=1}^{i-1} \frac{e^{S_{r, j} - M_{r, i-1}}}{D'_{r, i-1}} * V[j, c] * \frac{D'_{r, i-1} * e^{M_{r,i-1} - M_{r,i}}}{D'_{r, i}} + \frac{e^{S_{r, i} - M_{r, i}}}{D'_{r,i}} * V[i, c] \\ &= O'_{r,c, i-1} * \frac{e^{M_{r,i-1} - M_{r,i}} * D'_{r, i-1}}{D'_{r, i}} + \frac{e^{S_{r, i} - M_{r, i}}}{D'_{r,i}} * V[i, c] \end{aligned}\]
最终,我们想要的注意力输出结果为:
\[O_{r,c} = O_{r,c,N}'\]【定理 1】 算法 1 注意力输出矩阵 $O = softmax(QK^T)V$ 要求 $O(N^2d)$ 的 FLOPs,并且除了输入和输出内存之外,需要额外的 $O(N)$ 内存【证明见附录 B】。
上述就是 FlashAttention 算法的等效计算公式,对应的伪代码可以写为:
for (r = 1 to N)
for (i = 1 to N)
// [N, Dim] * [Dim, N] -> [N, N]
for (j = 1 to Dim)
S[r, i] += Q[r, j] * K[j, i]
// [N, N]
M[r, i] = max(M[r, i-1], S[r, i])
// [N, N]
D'[r, i] = D'[r, i-1] * exp(M[r, i-1] - M[r, i]) + exp(S[r, i] - M[r, i])
// [N, Dim]
for (c = 0 to Dim)
for i in range(0, N):
o += o * e(...) * D'[r, i-1] / D'[r, i] + e(...) / D'[r, i] * V[i, c]
O[r][c] = o
再用 python 实现如下所示:
def online_softmax_update(m0, d0, m1, d1):
# x 1
m = max(m0, m1) # flops: 1
d = d0 * np.exp(m0 - m) + d1 * np.exp(m1-m) # flops: 5
return m, d
def flashattn_update(m, d, m0, d0, o0, m1, d1, o1):
# | | | | | |
# | | | x v 1
# Init value: MIN_M 0 0
o = o0 * np.exp(m0 - m) * d0 / d + o1 * np.exp(m1 - m) * d1 / d
return o
def flashattn_1(Q, K, V):
N, Dim = Q.shape
# 1, Load Q K and write S. and Compute S[r][i] by matrix multiply
S = np.zeros([N, N], "float32")
O = np.zeros([N, Dim], "float32")
m = np.zeros([N], "float32")
d = np.zeros([N], "float32")
for r in range(0, N):
# 计算 QK^T 的第 i 行结果 S[r][i]
for i in range(0, N):
# QK^T
for j in range(0, Dim):
S[r][i] += Q[r][j] * K[i][j] # K^T 的列就是 K 的行
# softmax: [N,N] -> [N,N]
if i == 0:
mm = S[r][0]
dd = 0
mm, dd = online_softmax_update(mm, dd, S[r][i], 1) # flops 为 6
m[i] = mm
d[i] = dd
# PV: [N, N] * [N, Dim] -> [N, dim]
for c in range(0, Dim):
o = 0
for i in range(0, N):
# 迭代更新注意力计算输出
o = flashattn_update(
m[i],
d[i],
m[i-1] if i > 0 else MIN_M,
d[i-1] if i > 0 else 0,
o,
S[r][i],
V[i][c],
1
)
O[r][c] = o
return O
继续优化,上面的公式和代码只是实现了在一个 for 循环中计算 $o(r, c)$,但是没有分块计算,与 Online softmax 的 $D_{r,i}$一样,$ O’_{r,c, i}$ 也满足也具有分块满足交换律和结合律的特性:
\(\begin{aligned} D_{r, xy}' &= D_{r, x}' * e^{M_{r, x} - M_{r, xy}} + D_{r, y}' * e^{M_{r, y} - M_{r, xy}}\\ O_{r,c,xy}' &= O_{r,c,x}' * \frac{e^{M_{r, x}-M_{r, xy}}D_{r, x}'}{D_{r, xy}'} + O_{r,c,y}' * \frac{e^{M_{r, y}-M_{r, xy}}D_{r, y}'}{D_{r, xy}'}\\ \end{aligned}\)
有问题,需要更新。
因此,FlashAttention-1 的分块计算 python 代码如下。
def block_flashattn(Q, K, V, block_size=32):
N, Dim = Q.shape
# 1, Load Q K and write S. and Compute S[r][i] by matrix multiply
S = np.zeros([N, N], "float32")
O = np.zeros([N, Dim], "float32")
for r in range(0, N):
for i in range(0, N):
# QK^T
for j in range(0, Dim):
S[r][i] += Q[r][j] * K[i][j]
for r in range(0, N):
# Softmax
mm = np.zeros([N], "float32")
dd = np.zeros([N], "float32")
m = np.zeros([N // block_size], "float32")
d = np.zeros([N // block_size], "float32")
for b in range(0, N // block_size):
# Calculate m,d of single block
for i in range(0, block_size):
mm[b*block_size + i], dd[b*block_size + i] = online_softmax_update(
mm[b*block_size + i-1] if i > 0 else MIN_M,
dd[b*block_size + i-1] if j > 0 else 0,
S[r, b*block_size + i],
1,
)
# Merge all block's result to total
m[b], d[b] = online_softmax_update(
m[b-1] if b > 0 else MIN_M,
d[b-1] if b > 0 else 0,
mm[(b + 1) * block_size - 1], # 当前块的 mm 和 dd
dd[(b + 1) * block_size - 1])
# PV: [N, N] * [N, Dim] -> [N, dim]
for c in range(0, Dim):
o = 0
for b in range(0, N //block_size):
# Calculate single block
oo = 0
for i in range(0, block_size):
oo = flashattn_update(
mm[b * block_size + i], # 当前迭代位置的 m
dd[b * block_size + i], # 当前迭代位置的 d
mm[b * block_size + i-1] if i > 0 else MIN_M,
dd[b * block_size + i-1] if i > 0 else 0,
oo,
S[r, b * block_size + i], # 当前迭代位置的 s[r,i]
V[b * block_size + i, c],
1
)
# Merge all blocks to total
o = flashattn_update(
m[b],
d[b],
m[b - 1] if b > 0 else MIN_M,
d[b - 1] if b > 0 else 0,
o,
mm[(b + 1) * block_size - 1],
dd[(b + 1) * block_size - 1],
oo,
)
O[r][c] = o
return O
注意,前面内容的 FlashAttention 的 numpy 实现都是参考这里,但是这种实现和 FlashAttention 论文的公式和算法实现有些不同!仅供参考。
2.5 FlashAttention
FlashAttention-v1 其实并没有提出新的算法和网络结构上的优化,但是其在算法上综合了过往的两个创新点:分块和重计算,并将其应用于 Attention 结构,给出了详尽的数学计算、证明和 IO 复杂度分析(论文长达 34 页大头都是公式),可以说是过往 transformer 模型在 gpu 上优化的集大成者,而且最重要的是提供了非常易用的前向传播和反向传播的代码库,这使得其广为引用和应用于工业界。
可见,优秀的代码功底、扎实的理论基础、底层硬件和框架的熟悉对于科研工作非常重要,即使你没有提出新的算法,但是你的工作依然可以广为传播和应用。
总的来说,FlashAttention 在算法层面通过重排注意力计算,并利用经典技术(分块和重计算)显著加速了注意力计算,将内存占用从二次方降低到线性。使得在 sequence length 偏长和 attention 计算处于内存密集型的情况下有着明显的加速效果。并直接带来了相对于优化基准 2-4 倍的实际运行时间加速,以及高达 10-20 倍的内存节省,并且计算结果是精确而非近似的。
核心思想总结:flash attention 本质上是通过分块方法和 online_softmax 思想的减少内存读写次数/内存带宽时间,具体讲就是减少了 hbm -> sram 的内存搬运数据量,也就提高了 self-attention 操作强度。
本文主要分析其在模型推理阶段的优化,因此重计算方法的分析就略过了。
论文总结的一些定理:
【定理 1】 算法 1 注意力输出矩阵 $O = softmax(QK^T)V$ 要求 $O(N^2d)$ 的 FLOPs,并且除了输入和输出内存之外,需要额外的 $O(N)$ 内存【证明见附录 B】。
【定理 2】假设 $N$ 是输入序列的长度,$d$ 是注意力头的维度,$M$ 是 SRAM 大小,且 $d \leq M\leq Nd$。标准 attention 的 HBM 访问次数是 $O(Nd+N^2)$,而 FlashAttention [算法 1] 只需要 $O(N^2d^2M^{-1})$。
【命题 3】设 $N$ 为序列长度,$d$ 为头部维度,$M$ 为 SRAM 的大小,且 $d \leq M \leq Nd$。不存在一个算法可以在所有范围内的 $M$(即 $[d, N d]$)使用少于 $O(N^2 d^2 M^{-1})$ 次 HBM 访问来计算精确的注意力。
【定理 4】假设 $N$ 是输入序列的长度,$d$ 是注意力头的维度,$M$ 是 SRAM 大小,且 $d \leq M\leq Nd$。块-稀疏的 FlashAttention (算法 5) 的 HBM 访问次数是 $O(Nd + N^2d^2M^{−1}s)$。(其中 $s$ 是块稀疏掩码中非零块的比例)
【定理 5】设 $N$ 为序列长度,$d$ 为头部维度,$M$ 为 SRAM 的大小,且 $d \leq M \leq Nd$。标准注意力(算法 0)的反向传播需要 $\Theta(N d + N^2)$ 次 HBM 访问,而 FlashAttention 的反向传播(算法 4)只需要 $\Theta(N^2 d^2 M^{-1})$ 次 HBM 访问。
FlashAttention 算法实现步骤如下所示。

上面的是纯 python 代码,下面我们继续优化,利用 triton 框架写出极度优化的 FlashAttention-1 内核代码。
@triton.jit
def flash_attention_v1_kernel(
q_ptr,
k_ptr,
v_ptr,
o_ptr,
q_batch_stride,
q_heads_stride,
q_seq_stride,
q_dim_stride,
k_batch_stride,
k_heads_stride,
k_seq_stride,
k_dim_stride, # matrix Q stride for columns, [seq_len, head_dim]
v_batch_stride,
v_heads_stride,
v_seq_stride,
v_dim_stride,
out_batch_stride,
out_heads_stride,
out_seq_stride,
out_dim_stride,
n_heads, # number of heads
m_size,
n_size, # sequence length of k, also be rows of K matrix
BLOCK_DHEAD_SIZE: tl.constexpr, # head_dim dimension
BLOCK_M_SIZE: tl.constexpr, # BLOCK size of m_size dimension,即 Q 矩阵行数分成了m_size // BLOCK_M_SIZE 块,块大小是 BLOCK_M_SIZE
BLOCK_N_SIZE: tl.constexpr, # n_size dimension
sm_scale,
):
"""
针对 prefill 阶段的 attention, 所以忽略了添加 mask 过程
"""
block_m_idx = tl.program_id(0)
head_idx = tl.program_id(1)
cur_batch_idx = head_idx // n_heads
cur_head_idx = head_idx % n_heads
m_range_offs = tl.arange(0, BLOCK_M_SIZE)
n_range_offs = tl.arange(0, BLOCK_N_SIZE)
dhead_range_offs = tl.arange(0, BLOCK_DHEAD_SIZE)
m_offs = block_m_idx * BLOCK_M_SIZE + m_range_offs
# Compute offsets for the first block on matrix Q K V Output
q_offs = (
cur_batch_idx * q_batch_stride
+ cur_head_idx * q_heads_stride
+ (m_offs[:, None] * q_seq_stride + dhead_range_offs[None,:] * q_dim_stride))
k_offs = (
cur_batch_idx * k_batch_stride
+ cur_head_idx * k_heads_stride
+ (n_range_offs[:,None] * k_seq_stride + dhead_range_offs[None,:] * k_dim_stride))
v_offs = (
cur_batch_idx * v_batch_stride
+ cur_head_idx * v_heads_stride
+ (n_range_offs[:,None] * v_seq_stride + dhead_range_offs[None,:] * v_dim_stride))
o_offs = (
cur_batch_idx * out_batch_stride
+ cur_head_idx * out_heads_stride
+ (m_offs[:,None] * out_seq_stride + dhead_range_offs[None,:] * out_dim_stride))
q_ptrs = q_ptr + q_offs
k_ptrs = k_ptr + k_offs
v_ptrs = v_ptr + v_offs
out_ptrs = o_ptr + o_offs
# 初始化用于计算 softmax 归一化项的 m 和 d, 意义见 online-softmax, 这里
# 初始化用于计算 softmax 归一化项的 m 和 d, 意义见 online-softmax, 这里
m_i = tl.zeros((BLOCK_M_SIZE,), dtype=tl.float32) - float("inf")
d_i = tl.zeros((BLOCK_M_SIZE,), dtype=tl.float32)
o_i = tl.zeros((BLOCK_M_SIZE, BLOCK_DHEAD_SIZE), dtype=tl.float32)
q_mask = m_offs[:, None] < m_size
q = tl.load(q_ptrs, mask=q_mask, other=0.0)
for block_n_start_idx in range(0, n_size, BLOCK_N_SIZE):
block_n_offs = block_n_start_idx + n_range_offs
k_mask = block_n_offs[:, None] < n_size
k = tl.load(k_ptrs + block_n_start_idx * k_seq_stride, mask=k_mask, other=0.0
# qk^t 初始化赋值 0
qk = tl.zeros((BLOCK_M_SIZE, BLOCK_N_SIZE), dtype=tl.float32)
qk = tl.dot(q, tl.trans(k))
qk *= scale # scale 是 \sqrt{d_k}
m_j = tl.max(qk, 1)
n_j = tl.exp(qk - m_j[:, None]) # 计算 softmax 的分子项
d_j = tl.sum(n_j, 1) # 计算 softmax 的分母项,即归一化项
m_new = tl.maximum(m_j, m_i) # 更新 qk^t 最大值
alpha = tl.exp(m_i - m_new)
beta = tl.exp(m_j - m_new)
d_new = alpha * d_i + beta * d_j
scale1 = d_i / d_new * alpha
o_i = o_i * scale[:, None]
p_scale = beta / d_new
qk_softmax = n_j * p_scale[:, None]
V = tl.load(v_ptrs + block_n_start_idx * v_k_stride, mask=v_ptr_mask, other=0.0)
o_i += tl.dot(qk_softmax, V)
# 更新 m_i、d_i、o_i 用于下一轮计算
m_i = m_new
d_i = d_new
out_mask = m_offs[:, None] < m_size
tl.store(out_ptrs, o_i, mask=out_mask)
@torch.no_grad()
@custom_fwd(cast_inputs=torch.float16)
def flash_attention_v1(
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
sm_scale,
attention_mask: Optional[torch.Tensor] = None,
):
"""Compute Flash-attention, can't support fp32 input
参数:
q: Query tensor, shape: [bs, n_heads, m_size, head_dim], decode 阶段, q 的 seq_len 和 k v 不一致, 其值为 1
k: Key tensor, shape: [bs, n_heads, n_size, head_dim].
v: Value tensor, shape is consistent with k.
output: Attention ouput tensor, shape is consistent with q.
attention_mask: Attention mask matrix broadcastable to (batch, head_size, m_size, n_size).
"""
output = torch.empty_like(q)
assert q.shape[-1] == k.shape[-1] == v.shape[-1]
assert (
q.dtype == k.dtype == v.dtype == output.dtype
), f"All tensors must have the same dtype: {q.dtype}, {k.dtype}, {v.dtype}, {output.dtype}"
# sequence length of q, also be rows of Q matrix
bs, n_heads, m_size, head_dim = q.size()
n_size = k.shape[2]
# sm_scale = 1 / math.sqrt(head_dim)
# BLOCK_M_SIZE = 128
grid = lambda meta: (triton.cdiv(m_size, meta["BLOCK_M_SIZE"]), bs*n_heads, 1) # 二维 grid
flash_attention_v1_kernel[grid](
q,
k,
v,
output,
*q.stride(), # (batch, heads, m_size, head_dim)
*k.stride(), # (batch, heads, n_size, head_dim)
*v.stride(), # (batch, heads, n_size, head_dim)
*output.stride(), # (batch, heads, m_size, n_size)
n_heads,
m_size,
n_size,
head_dim,
64, # BLOCK_M_SIZE
64, # BLOCK_N_SIZE
sm_scale
)
return output
3. FlashAttention-2
FlashAttention-2 主要是在 cuda 工程上进行极致优化,算法上的改动很小,$O_{r,c,i}$ 的迭代计算过程中需要反复除以 $D_{r,i}’$,总共需要除以 $N^2d$ 次,这大大增加了计算量,可以考虑简化下述递推公式。
\[O'_{r,c, i} =O_{r,c,i-1}'*\frac{e^{M_{r, i-1} - M_{r, i}}D_{r,i-1}'}{D_{r,i}'} + \frac{e^{S_{r, i} - M_{r, i}}}{D_{r, i}'}V[i, c]\]先将原递推公式简写成: \(O[i] = O[i-1] * E * D[i-1]/D[i] + E*V/D[i]\)
将等式两边同时乘以 $D[i]$ 得:
\[O[i]*D[i] = O[i-1] * E * D[i-1] + E*V\]再记 $O[i]*D[i] == OD[i]$,则:
\[\begin{align} OD[i] &= OD[i-1] * E + E*V \nonumber \\ O[i] &= OD[i] / D[i] \nonumber \end{align}\]这样公式就大大简化了,减少了 FlashAttention 的计算量。
4. FlashAttention-3
FlashAttention-2 的缺陷是对训练提速较多,对推理加速不大:主要是因为推理阶段查询的长度通常是 1,这意味着如果批量大小小于 GPU 上流处理器(SM)的数量(A100 GPU 上有 108 个 SM),那么 atttention 操作只能使用一小部分 GPU!尤其是在使用较长的上下文时,由于需要更小的批量大小以适应 GPU 内存,批量大小为 1 的情况下,FlashAttention 的 GPU 利用率不到 1%。
为了提高 attention 在推理阶段的计算速度,提出了 FlashAttention-3。
Flash-Decoding 在前作对 batch size 和 query length 并行的基础上增加了一个新的并行化维度:keys/values 的序列长度,代价是最后一个小的归约步骤。
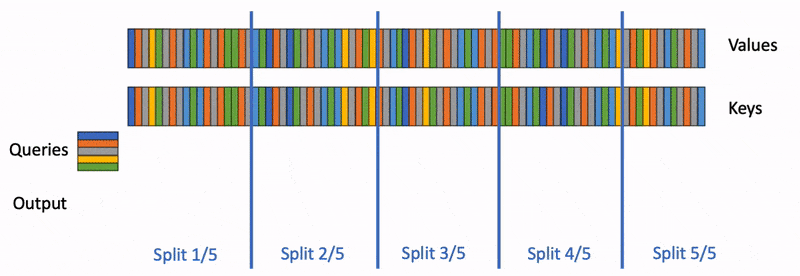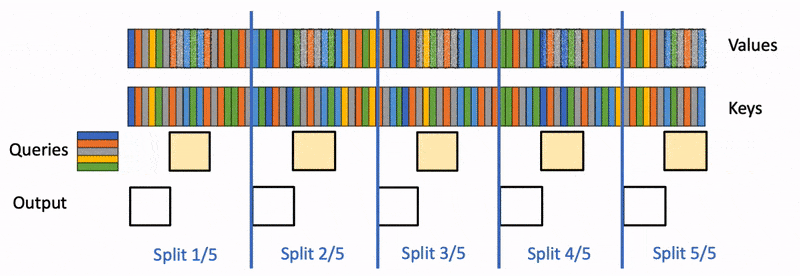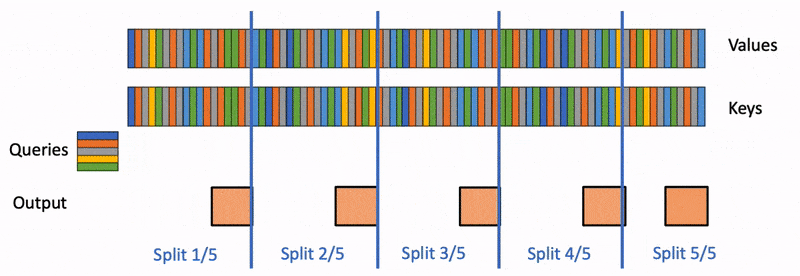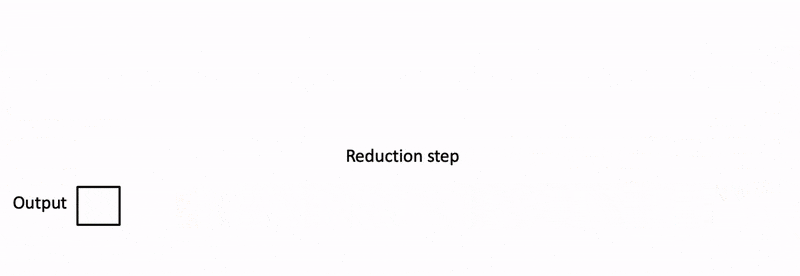
Flash-Decoding 的工作流程分为三个步骤:
- 首先,将键/值拆分成更小的块。
- 然后,使用 FlashAttention 并行计算查询与每个拆分块的注意力值,同时为每行和每个块记录一个额外的标量:注意力值的 log-sum-exp。
- 最后,通过对所有拆分块进行归约,结合 log-sum-exp 调整各个块的贡献,计算出最终的结果。
上述步骤之所以可行,是因为注意力/softmax 可以迭代计算(前作的贡献)。在 Flash-Decoding 中,它在两个层次上使用:在拆分内(类似于 FlashAttention)和跨拆分来执行最终归约。
实际上,步骤 (1) 不涉及任何 GPU 操作,因为键/值块是完整键/值张量的视图。接下来,我们有两个独立的内核分别执行步骤 (2) 和 (3)。
总结: Flash-Decoding 主要是针对 llm 推理的加速,在 batch_size 较小和序列长度较大时有着明显的加速效果,且性能对序列长度的增加并不敏感。
参考资料
- Online normalizer calculation for softmax
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- FlashAttention-2:Faster Attention with Better Parallelism and Work Partitioning
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- Chenfan Blog-FlashAttentions
- FlashAttentions 原理及代码实现
- Self Attention 固定激活值显存分析与优化及PyTorch实现
- 榨干 GPU 效能的 Flash Attention 3
- 图解大模型计算加速系列:FlashAttention V1,从硬件到计算逻辑
- FlashAttention 实现算子融合原理的可视化
- FlashAttention: Fast and Memory-Efficient Exact Attention With IO-Awareness