llama1-3 模型结构详解
Categories: Transformer
本文主要从模型推理角度去总结 llama1-3 模型论文和报告,因此没有涉及到数据集处理、模型训练及试验报告的细节,更多的是介绍了 LLaMA 模型的主要思想以及模型结构的细节。
一 llama1 模型
LLaMA(Large Language Model Meta AI)是 由 Meta AI 发布的一个开放且高效的大型基础语言模型,共有 7B、13B、33B、65B(650 亿)四种版本。其数据集来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现,整个训练数据集在 token 化之后大约包含 1.4T 的 token。
关于模型性能,LLaMA 的性能非常优异:具有 130 亿参数的 LLaMA 模型「在大多数基准上」可以胜过 GPT-3( 参数量达 1750 亿),而且可以在单块 V100 GPU 上运行;而最大的 650 亿参数的 LLaMA 模型可以媲美谷歌的 Chinchilla-70B 和 PaLM-540B。
关于训练集,其来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现。整个训练数据集在 token 化之后大约包含 1.4T 的 token。其中,LLaMA-65B 和 LLaMA-33B 是在 1.4万亿个 token 上训练的,而最小的模型 LLaMA-7B 是在 1万亿个 token 上训练的。
Hoffmann 等人(2022)最近的工作表明了,在给定的计算预算下,最佳性能不是由最大的模型实现的,而是基于更多数据上的训练较小模型实现的。
和之前的工作相比,llama 论文的重点是基于更多 tokens 的训练集,在各种推理预算下,训练出性能最佳的一系列语言模型,称为 LLaMA,参数范围从 7B 到 65B 不等,与现有最佳 LLM 相比,其性能是有竞争力的。比如,LLaMA-13B 在大多数基准测试中优于 GPT-3,尽管其尺寸只有 GPT-3 的十分之一。作者相信,LLaMA 将有助于使 LLM 的使用和研究平民化,因为它可以在单个 GPU 上运行!在规模较大的情况下,LLaMA-65B 也具有与最佳大型语言模型(如 Chinchilla 或 PaLM-540B)相竞争的能力。
LLaMA 优势在于其只使用公开可用的数据,这可以保证论文的工作与开源兼容和可复现。之前的大模型要么使用了不公开的数据集去训练从而达到了 state-of-the-art,如 Chinchilla、PaLM 或 GPT-3;要么使用了公开数据集,但模型效果不是最佳无法和 PaLM-62B 或 Chinchilla 相竞争,如 OPT、GPT-NeoX、BLOOM 和 GLM。
1.1 模型整体结构
和 GPT 系列一样,LLaMA 模型也是 Decoder-only 架构,但结合前人的工作做了一些改进,比如:
Pre-normalization[GPT3]. 为了提高训练稳定性,LLaMA 对每个 transformer 子层的输入进行归一化,使用RMSNorm归一化函数,Pre-normalization 由Zhang和Sennrich(2019)引入。使用RMSNorm的好处是不用计算样本的均值,速度提升了40%FFN_SWiGLU[PaLM]。结构上使用门控线性单元,且为了保持 FFN 层参数量不变,将隐藏单元的数量调整为 $\frac{2}{3}4d$ 而不是 PaLM 论文中的 4d,同时将 ReLU 替换为SiLU[Shazeer,2020]激活,引入以提高性能。Rotary Embeddings[GPTNeo]。模型的输入不再使用positional embeddings,而是在网络的每一层添加了 positional embeddings (RoPE),RoPE 方法由Su等人(2021)引入。
完整的模型结构图如下图所示:
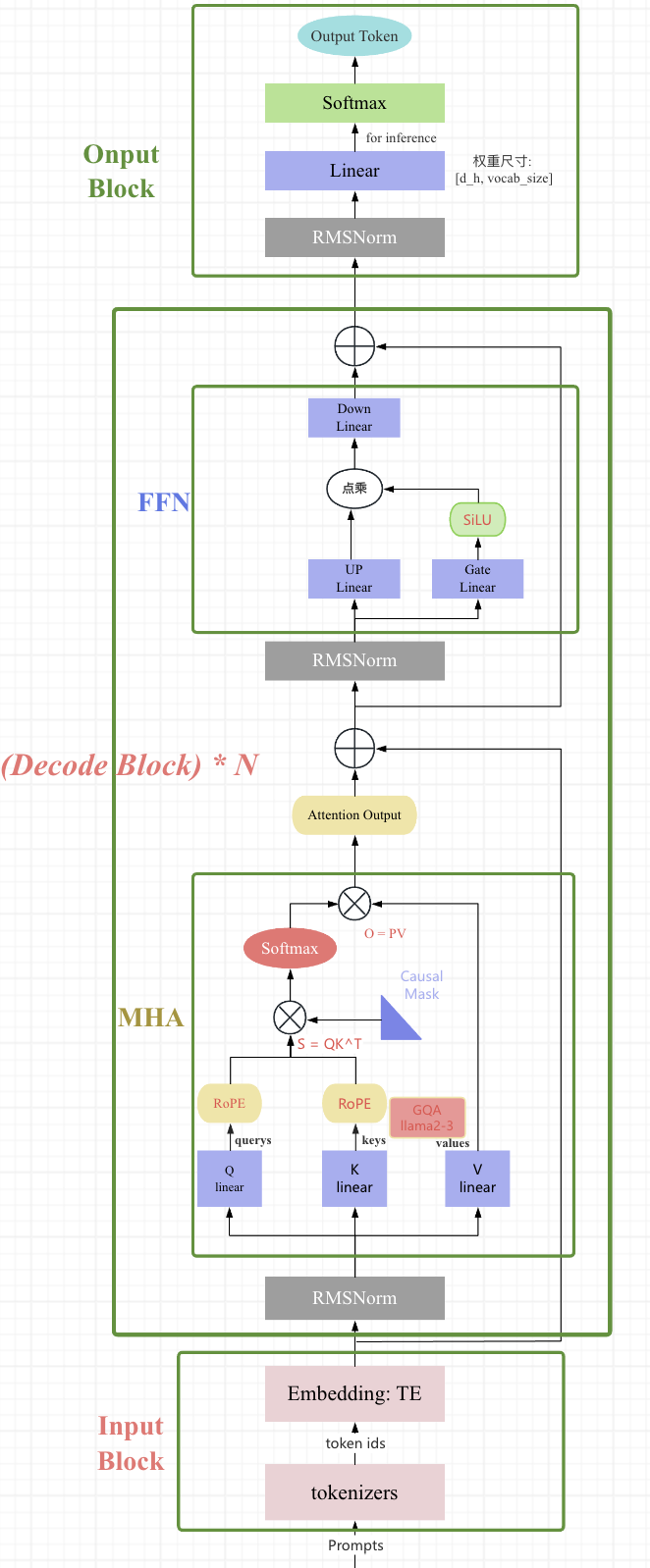
llama 模型系列的超参数详细信息在表 2 中给出。

1.2 RMSNorm
LayerNorm:
LayerNorm 通过对输入和权重矩进行重新中心化和重新缩放(re-centering 和re-scaling,即减均值和除方差,也称平移不变性和缩放不变性),来帮助稳定训练并加速模型收敛。
LayerNorm(LN) 主要用于 NLP 领域,它对每个 token 的特征向量进行归一化计算。设某个 token 的特征向量为 $x \in \mathbb{R}^d$,LN 运算如下:
\[\text{LN}(x): \hat{x}_i = \gamma \odot \frac{x_i - \hat{\mu}}{\hat{\sigma}} + \beta\]其中 $\odot$ 表示按位置乘,$\gamma, \beta \in \mathbb{R}^d$ 是缩放参数(scale)和偏移参数(shift),代表着把第 $i$ 个特征的 batch 分布的均值和方差移动到 $beta^i, \gamma^i$。$\gamma$ 和 $\beta$ 是需要与其他模型参数一起学习的参数。 $\hat{\mu}$ 和 $\hat{\sigma}$ 表示特征向量所有元素的均值和方差,计算如下:
\[\hat{\mu} = \frac{1}{d} \sum_{x_i \in \textrm{x}} x_i\] \[\hat{\sigma} = \sqrt{\frac{1}{d} \sum_{x_i \in \textrm{x}} (x_i - \hat{\mu})^2 + \epsilon}\]注意我们在方差估计值中添加一个小的常量 $\epsilon$,以确保我们永远不会尝试除以零。
RMSNorm:
RMSNorm(Root Mean Square Layer Normalization)论文假设 LayerNorm 中的重新中心化不再是必须的(平移不变性不重要),并提出了一种新的归一化方法:均方根层归一化(RMSNorm)。RMSNorm 通过均方根(RMS)对每一层神经元的输入进行归一化,使模型具备重新缩放不变性和隐式学习率调整的能力。相比 LayerNorm,RMSNorm 计算更为简洁,大约可以节省 7% 到 64% 的运算。
LayerNorm 和 RMSNorm 都主要用于 NLP 领域,它对每个 token 的特征向量(即嵌入维度)进行归一化计算。设某个 token 的特征向量为 $\textrm{x}\in \mathbb{R}$,RMSNorm 的计算如下:
其中,$\gamma$ 是可学习的缩放参数,$\text{eps}$ 的作用是为了保持数值稳定性。$d$ 输入 tokens 的数量,大小为 batch_size * seq_len。
以下是 RMSNorm 在 PyTorch 中的简单实现,使用了 RMS(均方根)来对输入进行归一化处理。
import torch
import torch.nn as nn
class LlamaRMSNorm(nn.Module):
"""nlp 领域"""
def __init__(self, dim, eps=1e-6):
"""
:param dim: 输入的维度
"""
super(RMSNorm, self).__init__()
self.weight = nn.Parameter(torch.ones(dim)) # 可学习的缩放参数 scale, 通常 1 个维度, 初始化为全1。
self.variance_epsilon = eps
def forward(self, hidden_states):
# hidden_states 的形状为 [batch_size, seq_len, dim]
input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(torch.float32)
variance = torch.mean(x ** 2, dim=-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return self.weight * hidden_states.to(input_dtype)
# 测试 RMSNorm
batch_size, seq_len, dim = 2, 4, 8
x = torch.randn(batch_size, seq_len, dim)
rmsnorm = RMSNorm(dim)
output = rmsnorm(x)
# nn.RMSNorm 如果传入的是单个整数,则会将其视为一个单元素列表,
# 模块会对最后一个维度进行归一化,并且该维度的大小应该符合这个指定值。
rmsnorm_pytorch = nn.RMSNorm(dim)
output_pytorch = rmsnorm_pytorch(x)
print("输入和输出的形状: ", x.shape, output.shape)
if torch.allclose(output, output_pytorch, atol=1e-6):
print("结果验证通过: 自己实的 RMSNorm 和 pytorch nn.RMSNorm 结果一致!")
else:
print("结果验证失败: 自己实的 RMSNorm 和 pytorch nn.RMSNorm 结果不一致。")
代码运行后输出结果如下所示:
输入和输出的形状: torch.Size([2, 4, 8]) torch.Size([2, 4, 8]) 结果验证通过: 自己实的 RMSNorm 和 pytorch nn.RMSNorm 结果一致!
1.3 FFN_SwiGLU
FFN 发展史
FFN:
FFN 层全称是 Position-wise Feed-Forward Networks(FFN),FFN 接收一个张量 x(序列中特定位置的隐藏表示),并将其通过两个可学习的线性变换(由矩阵 W1 和 W2 以及偏置向量 b1 和 b2 表示)进行处理,在两个线性变换之间应用修正线性(ReLU)Glorot et al.,2011激活。FFN 层(去掉了 dropout)结构如下图所示:

FFN 计算过程用数学公式可表达为:
在 T5 模型的实现中,使用的是没有偏置 bias 的版本,数学公式表达如下:
$\text{Swish}$ 激活: 后续的研究提出了用其他非线性激活函数替换 ReLU,如高斯误差线性单元 (Gaussian Error Linear Units),$\text{GELU}(x) = x\Phi (x)$ 和自门控(Self-Gated)激活函数 $\text{Swish}_{\beta}(x) = x\sigma(\beta x)$ Ramachandran et al., 2017,其中 $\sigma$ 为 $\text{Sigmoid}$ 激活函数。
\[\text{FFN}_{\text{GELU}}(x, W_1, W_2) = \text{GELU}(xW_1)W_2 \\ \text{FFN}_{\text{Swish}}(x, W_1, W_2) = \text{Swish}(xW_1)W_2\]其中激活函数 $\text{Swish}(x) = x⋅ \text{Sigmoid}(\beta x) = \frac{x}{1 + e^{-\beta x}}$,Sigmoid 函数: $\sigma(x) = \frac{1}{1 + e^{-x}}$。
$\beta$ 可以是常数或可训练参数。下图展示了不同 $\beta$ 值下的 Swish 曲线。
- 如果 $\beta$ = 1,Swish 等价于 Elfwing 等人(2017)为强化学习提出的 Sigmoid 加权线性单元(
SiLU)。 - 当 $\beta = 0$ 时,Swish 变为缩放线性函数 $f(x) = x/2$。
- 随着 $\beta$ 趋近于无穷大,sigmoid 分量接近 0-1 函数,因此 Swish 变得与 ReLU 函数相似。这表明 Swish 可以被看作是一个平滑的函数,在线性函数和 ReLU 之间进行非线性插值。如果将 $\beta$ 设置为可训练参数,模型可以调控这种插值的程度。

门控线性单元 GLU:
Dauphin et al., 2016 提出了门控线性单元( Gated Linear Units, GLU),定义为输入的两个线性变换的逐元素乘积,其中一个经过了 sigmoid 激活。另外,他们还建议省略激活函数,称之为“双线性”(bilinear)层。
当然,也使用其他激活函数定义 GLU 变体,如下所示:
\[\text{ReGLU}(x, W, V,b, c) = \text{max}(0, xW+b)\otimes (xV+c) \\ \text{GEGLU}(x, W, V,b, c) = \text{GELU}(xW+b)\otimes (xV+c) \\ \text{SwiGLU}(x, W, V,b, c) = \text{Swish}(xW+b)\otimes (xV+c)\]FFN 变体之 $\text{FFN}_\text{SwiGLU}$:
基于门控线性单元 $\text{GLU}$ 和 $\text{Swish}$ 激活,Noam Shazeer 发表了论文GLU Variants Improve Transformer, 2020,论文中提出了很多 Transformer FFN 层的变体,这些变体用 GLU 或其变体之一来替代原来的第一层线性变换和激活函数,和 FFN 一样,也省略了偏置项,这些 FFN 变体数学表达式如下所示:

FFN_SwiGLU
llama 对 FFN 的改进结构-$\text{FFN}_{\text{SwiGLU}}$,正是来源于论文:GLU Variants Improve Transformer。和 FFN_SwiGLU 原版实现使用 Swish 稍有不同,LLaMA 官方提供的代码使用 F.silu() 激活函数,$\text{SiLU}(x) = x⋅ \text{Sigmoid}(x)$。SwiGLU 数学表达式如下:
$\text{FPN}_{\text{SwiGLU}}$ 层结构如下图所示:

原始的的 $\text{FPN}$ 层只有两个权重矩阵,但变体 $\text{FPN}_{\text{SwiGLU}}$ 有三个线性层权重矩阵:$W_1$、$W_3$、$W_2$。为了保持参数数量和计算量的恒定,需要将隐藏单元的数量 d_ff(权重矩阵 $W_1$ 和 $W_3$ 的第二个维度以及 $W_2$ 的第一个维度)缩小 2/3。
Pytorch 实现代码如下所示:
# -*- coding : utf-8 -*-
# Author: honggao.zhang
import torch
import torch.nn as nn
import torch.nn.functional as F
class FFNSwiGLU(nn.Module):
def __init__(self, input_dim: int, hidden_dim: int):
super().__init__()
hidden_dim = int(2 * hidden_dim / 3)
self.fc1 = nn.Linear(input_dim, hidden_dim, bias=False)
self.fc2 = nn.Linear(hidden_dim, input_dim, bias=False)
self.fc3 = nn.Linear(input_dim, hidden_dim, bias=False)
def forward(self, x):
# LLaMA 官方提供的代码是使用 F.silu() 激活函数
return self.fc2(F.silu(self.fc1(x)) * self.fc3(x)))
layer = FFNSwiGLU(128, 256)
x = torch.randn(1, 128)
out = layer(x)
print(out.shape) # torch.Size([1, 128])
1.4 RoPE 旋转位置编码
之所以必须使用位置编码,是因为纯粹的 Attention 模块是无法捕捉输入顺序的,即无法理解不同位置的 token 代表的意义不同。比如,输入文本为“我爱苹果”或“苹果爱我”,模型会将这两句话视为相同的内容,因为嵌入中并没有明确的顺序信息让模型去学习。
RoPE(Rotary Position Embedding)旋转位置编码,由模型 RoFormer: Enhanced Transformer with Rotary Position Embedding 提出。RoPE 的核心思想是将位置编码与词向量通过旋转矩阵相乘,使得词向量不仅包含词汇的语义信息,还融入了位置信息,其具有以下优点:
- 相对位置感知:RoPE 能够自然地捕捉词汇之间的相对位置关系。
- 无需额外的计算:位置编码与词向量的结合在计算上是高效的。
- 适应不同长度的序列:RoPE 可以灵活处理不同长度的输入序列。
总结结合 RoPE 的 self-attention 操作的流程如下:
- 首先,对于
token序列中的每个词嵌入向量,都计算其对应的 query 和 key 向量; - 然后在得到 query 和 key 向量的基础上,应用公式(7)和(8)对每个
token位置都计算对应的旋转位置编码; - 接着对每个
token位置的 query 和 key 向量的元素按照两两一组应用旋转变换; - 最后再计算
query和key之间的内积得到 self-attention 的计算结果。
RoPE 代码实现
最后,如果你直接看 pytorch 代码,其实很难理解 rope 是如何应用相对位置信息的,这个只能通过前面的公式推导才能理解。
结合 llama 官方实现代码,下述是我修改优化和添加注释后的代码,更容易看懂:
def compute_theta(dim: int, base: float = 10000.0, device: torch.device = torch.device('cpu')) -> torch.Tensor:
"""
计算旋转位置编码中的 Theta 角度值。
参数:
- d (int): 嵌入向量的维度(必须为偶数)。
- base (float): 基础频率参数, 默认为10000.0。
- device (torch.device): 计算设备, 默认为CPU。
返回:
- torch.Tensor: 包含Theta值的1D张量, 形状为 [d/2]。
"""
if dim % 2 != 0:
print("嵌入维度 dim 必须为偶数")
i = torch.arange(1, (dim//2) + 1, dtype=torch.float32, device=device)
theta_i = base ** (-2*(i - 1) / dim)
return theta_i
def precompute_freqs_cis(dim: int, seq_len: int, base: float = 10000.0, device: torch.device = torch.device('cpu')):
theta = compute_theta(dim, base, device) # theta 角度值序列,向量, 大小为 dim // 2
m = torch.arange(seq_len, device=device) # # token 位置值序列,向量,大小为 seq_len
m_theta = torch.outer(m, theta) # 所有 token 位置的所有 Theta 值范围, 矩阵,尺寸为 [seq_len, dim // 2]
freqs_cis = torch.polar(torch.ones_like(m_theta), m_theta) # e^{i*m*\theta},本质上是旋转矩阵
return freqs_cis
def reshape_for_broadcast(freqs_cis, x):
ndim = x.ndim
assert ndim >= 2
assert freqs_cis.shape == (x.shape[1],x.shape[-1]), "the last two dimension of freqs_cis, x must match"
shape = [d if i==1 or i==ndim-1 else 1 for i,d in enumerate(x.shape)]
return freqs_cis.view(*shape)
def apply_rotary_emb(xq: torch.Tensor, xk: torch.Tensor, freqs_cis: torch.Tensor, device: torch.device = torch.device('cpu')):
"""
参数:
- x_q(torch.Tensor): 实际上是权重 W_q * 词嵌入向量值, 来自上一个线性层的输出, 形状为 [batch_size, seq_len, n_heads, head_dim]
- x_k(torch.Tensor): 实际上是权重 W_k * 词嵌入向量值, 来自上一个线性层的输出, 形状为 [batch_size, seq_len, n_heads, head_dim]
- freqs_cis (torch.Tensor): 频率复数张量, 形状为 [max_seq_len, head_dim]
返回:
- Tuple[torch.Tensor, torch.Tensor]: 旋转编码后的查询和键张量
"""
# 实数域张量转为复数域张量
xq_reshape = xq.reshape(*xq.shape[:-1], -1, 2) # [batch_size, seq_len, dim] -> [batch_size, seq_len, dim//2, 2]
xk_reshape = xk.reshape(*xk.shape[:-1], -1, 2) # [batch_size, seq_len, dim] -> [batch_size, seq_len, dim//2, 2]
xq_complex = torch.view_as_complex(xq_reshape) # 复数形式张量
xk_complex = torch.view_as_complex(xk_reshape) # 复数形式张量
# 旋转矩阵(freqs_cis)的维度在序列长度(seq_len,维度 1)和头部维度(head_dim,维度 3)上需要与嵌入的维度一致。
# 此外,freqs_cis 的形状必须与 xq 和 xk 相匹配,因此我们需要将 freqs_cis 的形状从 [max_seq_len, head_dim] 调整为 [1, max_seq_len, 1, head_dim]。
freqs_cis = reshape_for_broadcast(freqs_cis, xq_complex) # [max_seq_len, 1, 1, dim // 2]
# 应用旋转操作,并将结果转回实数域
xq_out = torch.view_as_real(xq_complex * freqs_cis).flatten(3) # flatten(2) 将后面两个维度压成一个维度
xk_out = torch.view_as_real(xk_complex * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
1.5 基于开源 LLaMA 1 微调的模型
以下这些项目都可以算是 Meta 发布的 LLaMA(驼马)模型的子子孙孙。
1,Alpaca
Alpaca 是斯坦福在 LLaMA 上对 52000 条指令跟随演示进行了精细调优的模型,是后续很多中文 LLM 的基础。
对应的中文版是 Chinese-LLaMA-Alpaca。该项目在原版 LLaMA 的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,在中文LLaMA 的基础上,本项目使用了中文指令数据进行指令精调,显著提升了模型对指令的理解和执行能力。
值得注意的是,该项目开源的不是完整模型而是 LoRA 权重,理解为原 LLaMA 模型上的一个“补丁”,两者进行合并即可获得完整版权重。提醒:仓库中的中文 LLaMA/Alpaca LoRA 模型无法单独使用,需要搭配原版 LLaMA 模型[1]。可以参考本项目给出的合并模型步骤重构模型。
- repo: https://github.com/ymcui/Chinese-LLaMA-Alpaca/
2,Vicuna
Vicuna 是一款从 LLaMA 模型中对用户分享的对话进行了精细调优的聊天助手,根据的评估,这款聊天助手在 LLaMA 子孙模型中表现最佳,能达到 ChatGPT 90% 的效果。

3,Koala(考拉)
一款从 LLaMA 模型中对用户分享的对话和开源数据集进行了精细调优的聊天机器人,其表现与Vicuna 类似。
- blog: Koala: A Dialogue Model for Academic Research
- demo: FastChat
- repo: https://github.com/young-geng/EasyLM
4,Baize (白泽)
- 论文:https://arxiv.org/pdf/2304.01196.pdf
- demo: Baize Lora 7B - a Hugging Face Space by project-baize
- repo: https://github.com/project-baize/baize
5,Luotuo (骆驼,Chinese)
- repo: https://github.com/LC1332/Luotuo-Chinese-LLM
另外,中文 LLM 的有影响力的模型还有 ChatGLM,通常指 ChatGLM-6B, 一个由清华团队开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署 ChatGLM(INT4 量化级别下最低只需 6GB 显存)。
整体使用下来,其基本任务没问题,但是涌现能力还是有限的,且会有事实性/数学逻辑错误,另外,Close QA 问题也很一般。GLM 模型架构与 BERT、T5 等预训练模型模型架构不同,它采用了一种自回归的空白填充方法,。
二 llama2 模型
2.1 llama2 概述
llama2 相比于 llama1 其训练数据提升了 40%,有 7B、13B、34B、70B 四个大小,其中 34B 的没有开放,另外三个都可下载。llama2 总共使用 2T 的 token 进行训练,上下文长度升级到了 4096,是 llama1 的两倍。从其 model card 中可知,llama2 的预训练是在 A100-80GB 上运行了 3.3M GPU hours。
和 LLaMA1 对比,Tokenizer 配置与 llama1 完全相同,分词使用 sentencePiece 库实现的 BPE 算法,vocabulary size 为 32k。
llama2 模型架构和 llama1 一模一样,但模型推理的 decode 阶段的 kv cache 优化上做了改变。具体来说,在 llama2-34B 和 llama2-70B 参数模型上使用了 GQA 优化技术,7B 和 13B 模型依然使用 MQA。
kv cache 内存计算公式为:$\text{memory_kv-cache} = 22nhb(s+o) = 4nhb(s+o)$。
2.2 kv cache 优化-GQA
MQA,全称 Multi Query Attention, GQA 由 google 提出的 MQA 变种,全称 Group-Query Attention,都是多头注意力(MHA)的变体,本质上是一种共用 KV cache 的优化方法。
kv cache 优化三种方案:MHA、 MQA 和 GQA 的原理及区别如下:
- 最原始的 MHA(Multi-Head Attention),QKV 三部分有相同数量的头(head),且一一对应。每次做 Attention,head1 的 QKV 就做好自己运算就可以,最后输出时将各个头的
self-attention output相拼接。 - MQA 则是让 Q 仍然保持原来的头数,但 K 和 V 只有一个头,相当于所有的 Q 头共享一个 K 和 V 头,所以叫做 Multi-Query 了。这直接让 KV cache 内存减少了 head_num 倍。
GQA是MHA和MQA的折中,将 Q 分成 8 组,每组共享相同的一个 kv 头,假设 Q 有 64 个头,则使用GQA技术后,kv 头数 = $64/8 = 8$。这直接让 KV cache 内存减少了 8 倍。
LLaMA2-70b 的模型配置如下图所示:

MHA、 MQA 和 GQA 原理的可视化对比如下图所示:

LLaMA2 官方实现的 GQA(包含了 kv cahce)代码如下所示(经过简化):
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
"""torch.repeat_interleave(x, dim=2, repeats=n_rep)"""
bs, slen, n_kv_heads, head_dim = x.shape
# 根据n_rep,拓展KV
if n_rep == 1:
return x
return (x[:, :, :, None, :].expand(bs, slen, n_kv_heads, n_rep, head_dim).reshape(bs, slen, n_kv_heads * n_rep, head_dim))
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
...
self.n_local_heads = args.n_heads // model_parallel_size #Q的头数
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size #KV的头数
self.n_rep = self.n_local_heads // self.n_local_kv_heads
...
self.wq = ColumnParallelLinear(args.dim,args.n_heads * self.head_dim, # Q的头数* head_dim
...)
self.wk = ColumnParallelLinear(args.dim,self.n_kv_heads * self.head_dim, # K的头数* head_dim
...)
self.wv = ColumnParallelLinear(args.dim,self.n_kv_heads * self.head_dim,# V的头数* head_dim
...)
self.wo = RowParallelLinear(args.n_heads * self.head_dim,args.dim,... )
self.cache_k = torch.zeros((args.max_batch_size,args.max_seq_len,self.n_local_kv_heads, #KV的头数
self.head_dim,)).cuda()
self.cache_v = torch.zeros((args.max_batch_size,args.max_seq_len,self.n_local_kv_heads,#KV的头数
self.head_dim,)).cuda()
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis) #嵌入RoPE位置编码
...
# 按此时序列的句子长度把kv添加到cache中
# 初始在prompt阶段seqlen>=1, 后续生成过程中seqlen==1
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
# 读取新进来的token所计算得到的k和v
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
# repeat k/v heads if n_kv_heads < n_heads
keys = repeat_kv(keys, self.n_rep) # (bs, seqlen, n_local_heads, head_dim)
values = repeat_kv(values, self.n_rep) # (bs, seqlen, n_local_heads, head_dim)
xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
#计算q*k
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
#加入mask,使得前面的token在于后面的token计算attention时得分为0,mask掉
scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
return self.wo(output)
三 llama3 模型
和 Llama 2 相比,Llama 3 最大的变化是采用了新的 Tokenizer,将词汇表大小扩展至 128k(前版本为 32k Token)。
3.1 llam3 概述
llama3 技术推理角度的总结:
- 模型结构: Llama 3 中依然选择了相对标准的纯解码器 decoder-only transformer 架构,模型结构上和 Llama 2 相比几乎没变化。在 Llama 2 中只有 34B,70B 使用了分组查询注意 (GQA),为了提高模型的推理效率,Llama 3 所有模型都采用了
GQA。 - 分词器:和 Llama 2 不同的是,Llama 3 将 tokenizer 由sentencepiece 换成
tiktoken, 词汇量从32K增加到128K,增加了 4 倍。更大的词汇库能够更高效地编码文本,增加编码效率,可以实现更好的下游性能。不过这也会导致嵌入层的输入和输出矩阵尺寸增大,模型参数量也会增大。 - 序列长度:在长度为
8,192的 token 序列上训练(之前是 4K),即模型输入上下文长度从4096(Llama 2)和2048(Llama 1)增加到8192(8k),但相对于 GPT-4 的 128K 来说还是相当小。
3.2 llam3.1 概述
首次发布了 405B 模型,和当下最强的 GPT-4 / Claude 3.5 旗鼓相当。全新升级了 Llama-3 的 8B 和 70B 版本,升级版不仅支持多语言功能,而且其上下文长度延展到了 128K,具有最先进的工具使用能力,推理能力也显著提升。
llam3.1 系列模型于 2024 年 7 月发布,有 3 个可用版本:8B、70B、405B。
3.3 llam3.2 概述
2024 年 9 月又发布了 Llama 3.2,包括小型和中型视觉语言模型(11B 和 90B),以及轻量级的文本模型(1B 和 3B),这些模型可以在边缘设备和移动设备上运行,同时提供预训练和指令调优的版本。
- Llama 3.2 中的 1B 和 3B 模型支持 128K tokens 的上下文长度,并且是同类中性能领先的,用于设备端的摘要生成、指令执行和文本重写任务。这些模型在发布时就已适配 Qualcomm 和 MediaTek 的硬件,并针对 Arm 处理器进行了优化。
- 在视觉任务上,Llama 3.2 的 11B 和 90B 模型在图像理解方面优于封闭模型如 Claude 3 Haiku,可以直接作为对应文本模型的替代品。这些模型既有预训练版本,也有对齐版本,可以使用 torchtune 微调,并通过 torchchat 部署到本地。此外,用户还可以通过我们的智能助手 Meta AI 直接试用这些模型。
- 首次发布了 Llama Stack 分发版本,这将大大简化开发者在不同环境中使用 Llama 模型的流程,包括单节点部署、本地部署、云端部署,以及设备端部署,从而实现 RAG(检索增强生成)和工具集成应用的快速部署。
轻量级模型 1B 和 3B
在 Llama 3.1 中已经讨论过,借助强大的教师模型可以打造更小、更高效的模型。META 在 1B 和 3B 模型上采用了剪枝和知识蒸馏这两种技术,使得这些模型成为了首批适用于设备的高性能轻量级 Llama 模型。
通过剪枝技术,我们能够减小 Llama 系列现有模型的规模,同时尽可能多地保留其知识和性能。对于 1B 和 3B 模型,我们使用了从 Llama 3.1 8B 进行一次性结构化剪枝的方法,即系统性地移除网络中的部分组件,并调整权重和梯度大小,最终生成一个更小巧且高效的模型,但仍保留了原始模型的性能表现。
知识蒸馏通过让小模型从大模型中学习,使小模型在训练时能够获得更好的性能表现。对于 Llama 3.2 的 1B 和 3B 模型,我们在预训练阶段引入了 Llama 3.1 8B 和 70B 模型的对数几率(logits),并将这些较大模型的输出作为训练目标。在剪枝后,使用知识蒸馏技术进一步恢复模型的性能。
在后训练阶段(post-training),我们沿用了 Llama 3.1 的训练方案,通过多轮的对齐步骤生成最终的聊天模型。每一轮的对齐包括监督微调(SFT)、拒绝采样(RS)和直接偏好优化(DPO)。在这个阶段,我们将模型的上下文长度扩展到了 128K tokens,同时确保模型的质量与预训练模型保持一致。此外,我们还使用合成数据进行训练,经过严格的数据处理和筛选,以确保数据质量。我们通过精心组合这些数据,优化了模型在摘要生成、文本重写、指令执行、语言推理以及工具使用等方面的能力。
Llama 3.2 发布的模型权重采用 BFloat16 数字格式。
参考资料
- Hendrycks and Gimpel, 2016
- GLU Variants Improve Transformer
- llama2介绍(模型结构+参数计算)
- 知乎-Llama 2详解
- 详解三种常用标准化 Batch Norm & Layer Norm & RMSNorm
- open-llm-components
- Build Your Own Llama 3 Architecture from Scratch Using PyTorch
- LLaMA: Open and Efficient Foundation Language Models
- Llama 2: Open Foundation and Fine-Tuned Chat Models
- https://github.com/meta-llama/llama/blob/main/llama/model.py