llm服务框架特性总结
Categories: Framework_analysis
一 llm 服务引擎特性比较
这里我给出各大 llm 服务引擎的主要特性总结,大家都有的常规或者体现不出差距的特性则忽略。
1.1 vllm
vllm 一些区别于其他框架或者自身做的好的特性:
- 从吞吐量角度看,作者称
vllm在大部分模型和 GPU 上都是实现了 SOTA。 - 在
llm推理层面的优化算法和模型量化上,支持的比较全和快。如支持最新的:Prefix Caching:提升多论对话场景的问答效果和速度;Speculative Decoding:在系统负载较低时,利用预测解码可以减少延迟。Chunked prefill: 将超长 prompt 拆分成多个块并和内存密集型的 decode 请求一起处理。
- 支持
weight-only的低比特量化 AWQ 及其他量化算法。 - 首次提出
PagedAttentionkv cache 管理、分配算法,并已被广大 llm 推理服务框架应用! - 支持种类极多的大语言文本模型和多模态模型。
PagedAttention 的运行机制如下图所示:
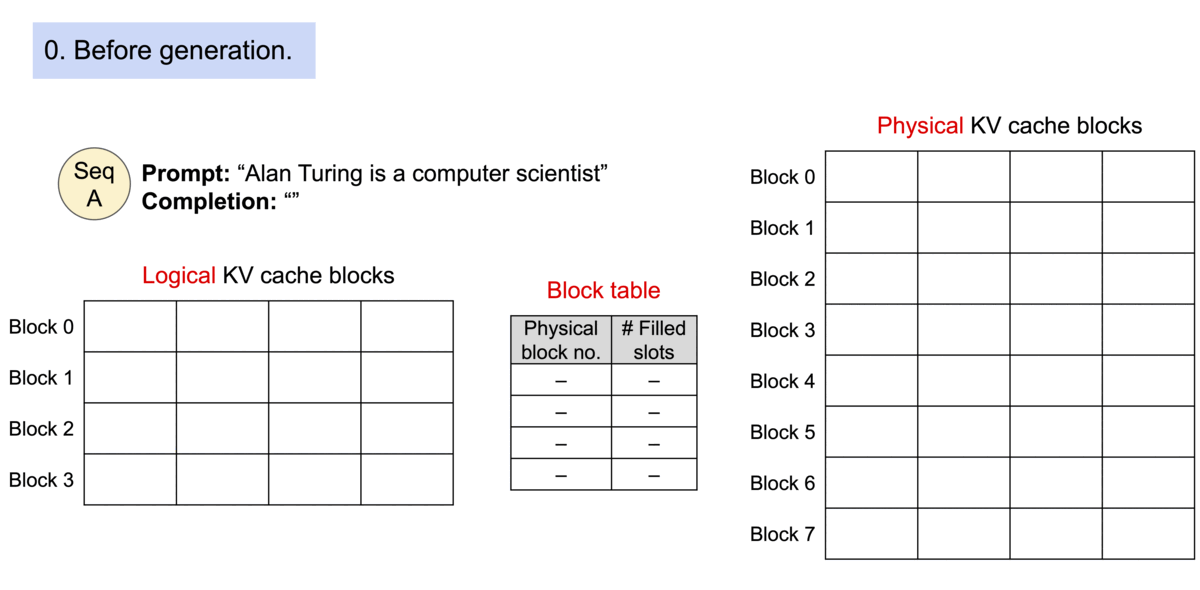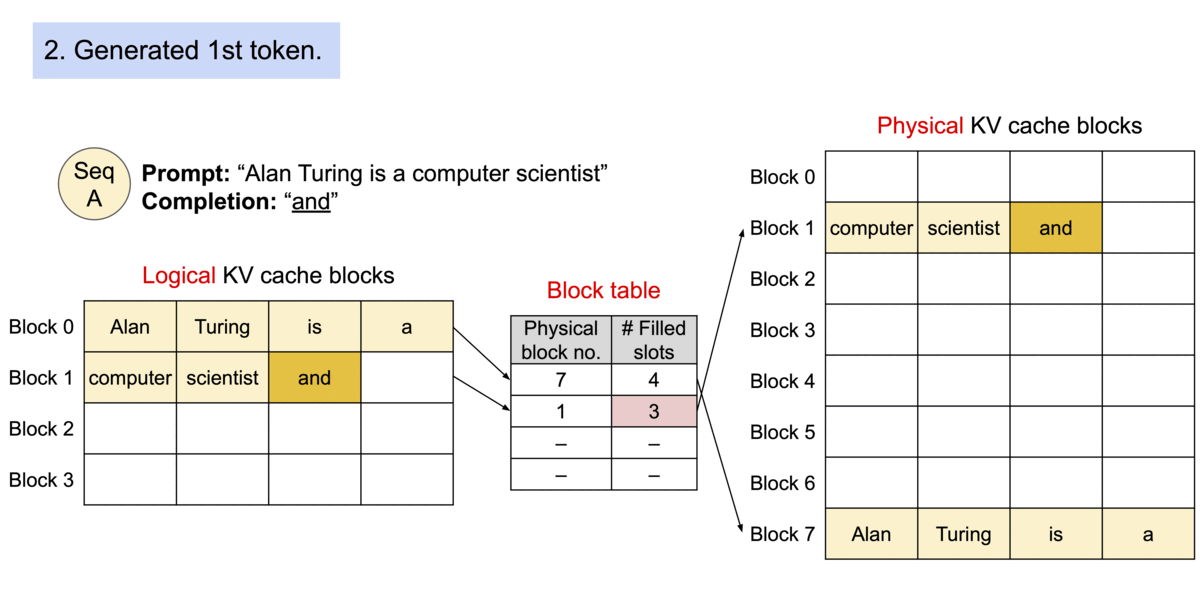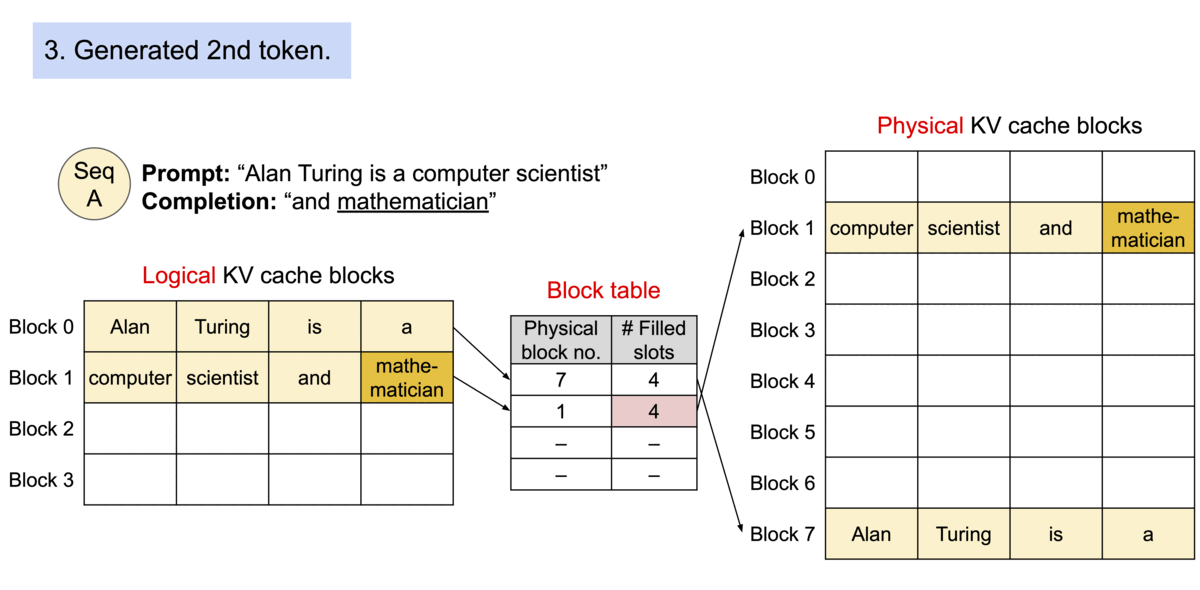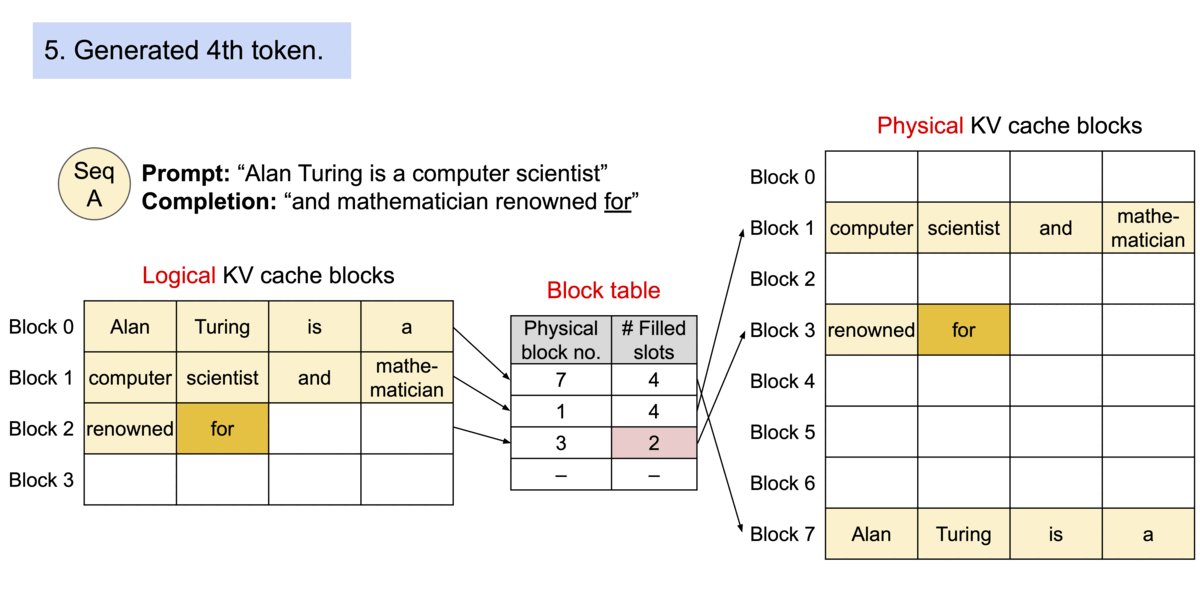
1.2 TGI
TGI 一些区别于其他框架或者自身做的好的特性:
- 性能监测工具好用且优雅;
- 目前我看到的最优服务调度策略,基于 rust 编写(高性能);
- 原生完美支持 transformers 库(毕竟出自一家公司抱抱脸);
- 框架扩展性强,推理层可定制大模型推理逻辑(你可以把推理层换成 lightllm,就可以复用 tgi 的高效服务调度模块)
- 同样支持
AWQ、GPTQ等量化算法。
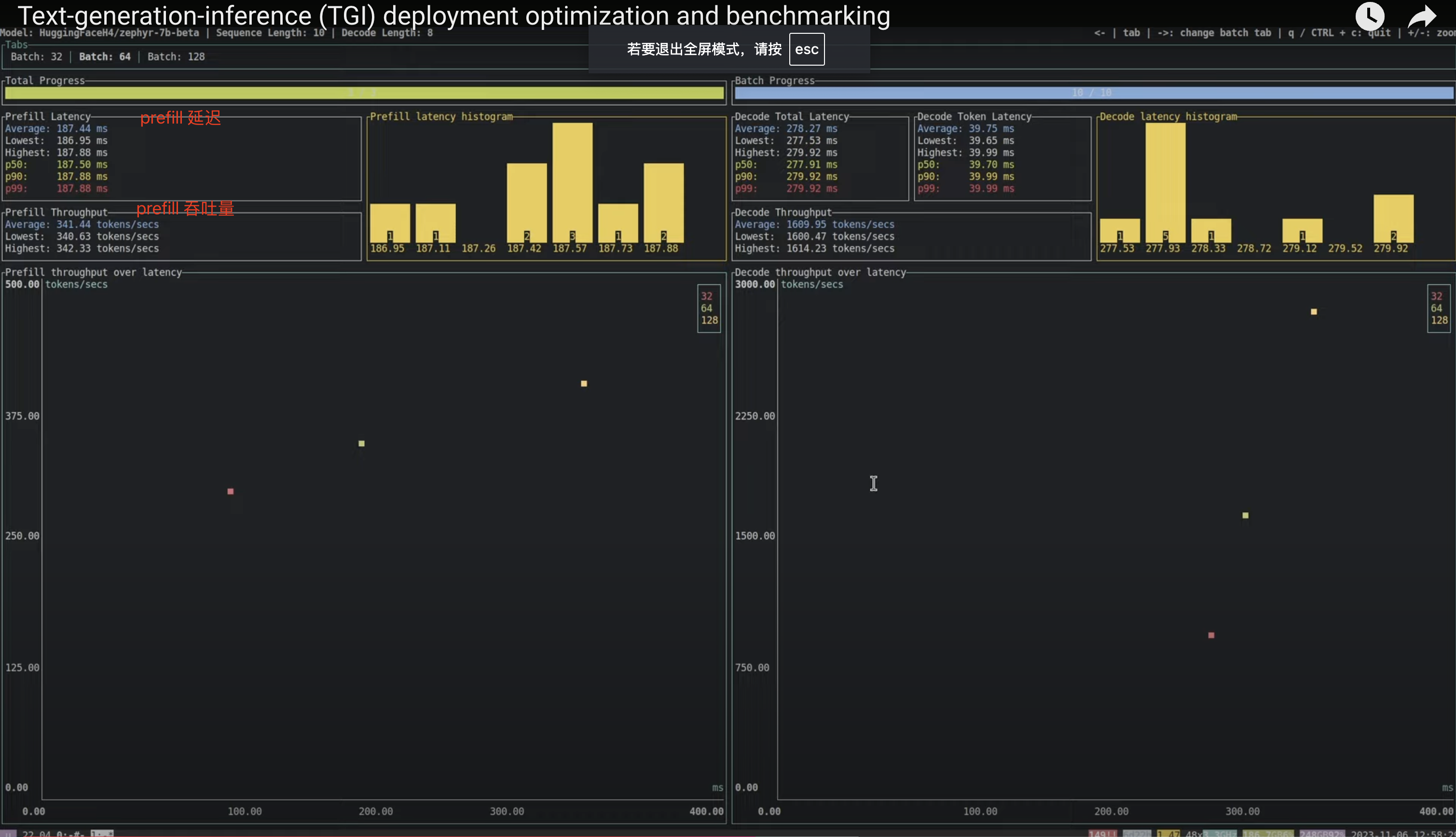
动态(在线)性能测试工具:
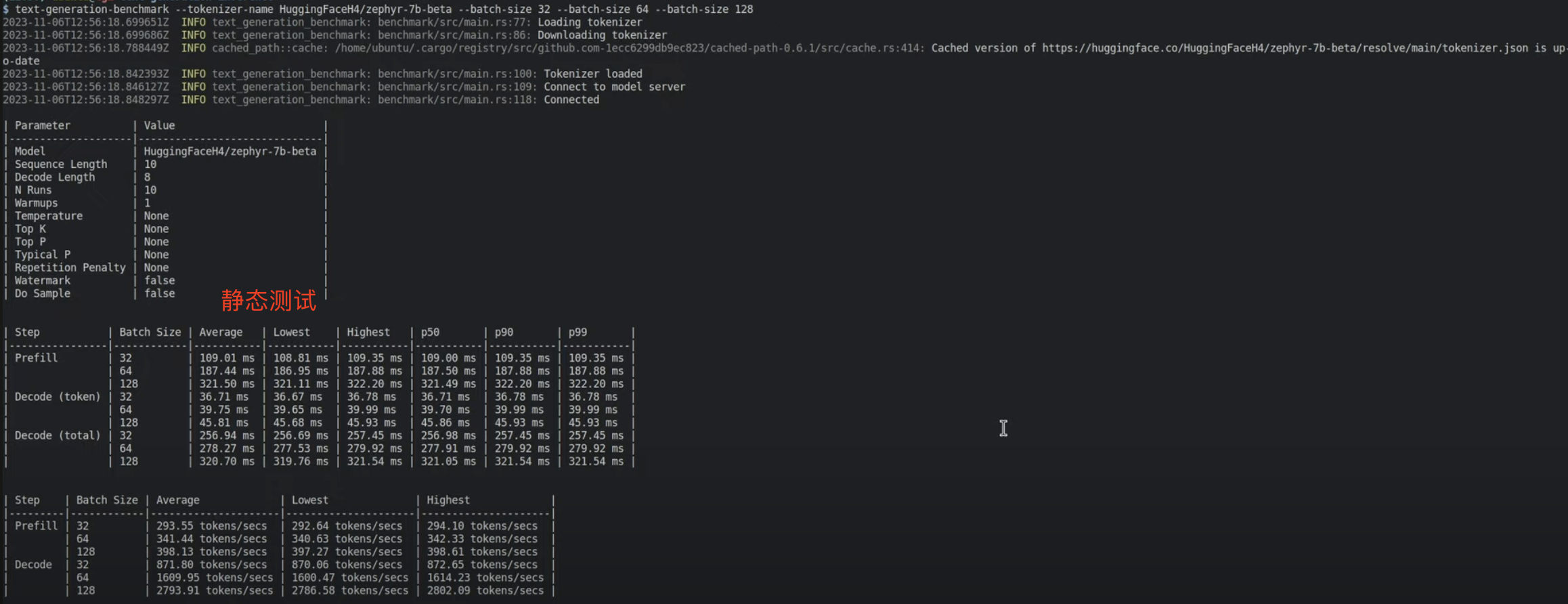
静态(离线)性能测试工具
1.3 TensorRT-LLM
仓库地址:TensorRT-LLM,官方文档地址: TensorRT-LLM-guide,一些区别于其他框架或者自身做的好的特性:
- 极致的 kernel 优化带来了 SOTA 的 latency 指标(毕竟在 cuda 内核优化上,英伟达自家舍我其谁),具体来说:
attention层:decode(generate)阶段的 attention 操作是 gemv,因为 seq_len = 1 的 MQA/GQA 无法充分发挥 tensor core 算力,提出一个新的XQAkernel 用于做 logical shape 的变换 ([bs,1,num q head,head dim]x[bs,k len,num kv head,head dim] => [bs, num kv head, num q head/num kv head, head dim]x[bs,num kv head,k len, head dim])。本质上是将batch gemv转换成batch gemm操作,以充分发挥 tensor core 算力。FFN层: 基于cutlass和cublas库实现了极致的gemm性能。
- 貌似是最全的量化算法支持,如
SQ(SmoothQuant)、GPTQ、AWQ,以及支持FP8(w8a8)、AWQ(w4a16)、AWQ(w4a8)、SQ(w8a8)、GPTQ(w4a16)。 - 新的批处理策略-
in-flight batching:基于 ORCA 论文里提出的continuous batching实现,代码闭源,在代码里是被称作Batch Manager的组件。功能都是允许在每次 token 生成循环迭代中动态添加新请求,并返回新完成的请求。据说性能更好。 - 图优化技术:通过
Module Rewriting和Graph Rewriting技术实现,相比 vllm 使用 torch 自带的 cuda graph 优化,TensorRT-LLM 原生支持图优化,并提供图优化技术,应该效率更高,具体说:- 模块重写:在执行 forward 方法前,调整 Module 实例的成员(即构建 TensorRT 图的过程)。它在网络表示的最高层级上操作,便于修改一系列操作(例如为 SmoothQuant 调整 GEMM + 激活函数的组合)。
- 图重写:在执行 forward 方法后,基于 TensorRT 的
INetworkDefinition进行操作。它以更细致的ILayer层次进行操作,能够跨多个 Module 实例调整结构,通常用于层融合操作。
TensorRT-LLM 量化方法
TensorRT-LLM 量化方法主要包括三个核心部分:
- 权重的精度格式
- 激活的精度格式
- 校准算法(基于校准集)
在小批量推理(批量大小 ≤ 4)场景中,内存带宽是主要考量,因此更倾向于仅对权重量化的方式。而在大批量推理场景(如服务场景,批量大小 ≥ 16)中,内存带宽和计算密度同样重要。因此,推荐选择对权重和激活都进行量化的方法。对于批量大小 ≥ 16 的场景,量化方法的选择可以依据具体模型进行调整。建议优先尝试 FP8,因为通常其性能和准确性最佳。如果结果无法满足特定需求,可以进一步尝试 Int8 SmoothQuant(Int8 SQ),然后是 AWQ 和/或 GPTQ。更多详情请参考官方文档。
在相同的延迟预算下,使用 XQA 优化后,Llama-70B 在 H200 上的吞吐量提升可达 2.4 倍。
| Model | GPUs | Input Length | Output Length | Throughput w/o XQA (tok/s/GPU) | Throughput w/ XQA (tok/s/GPU) | Speedup |
|---|---|---|---|---|---|---|
| Llama-70B | 1 | 128 | 2048 | 1,227 | 2,941 | 2.4x |
| 8 | 128 | 2048 | 13,232 | 25,300 | 1.9x |
1.4 lightllm
lightllm 一些区别于其他框架或者自身做的好的特性:
- 首次提出
tokenattention,本质上是粒度为token级别的pagedattention优化,最大的特点是内存几乎零浪费。 - 多进程协同:
tokenization、模型推理、detokenization等工作异步进行,大幅提高 GPU 利用率,减少 gpu 空泡现象。
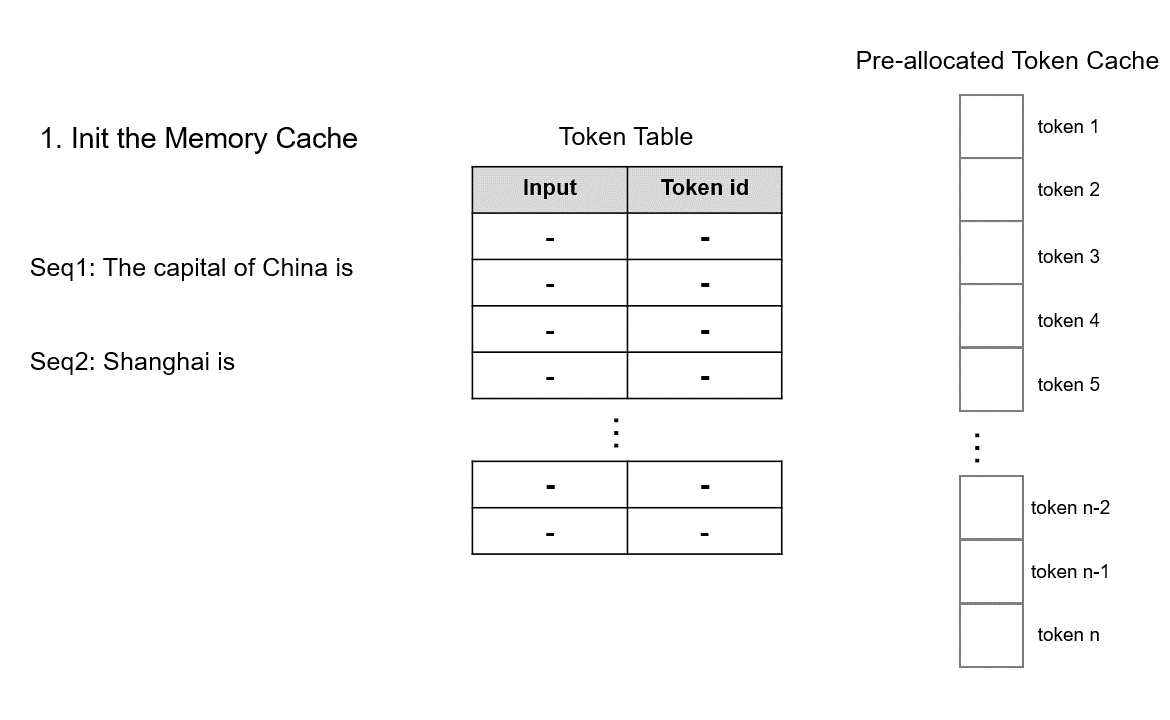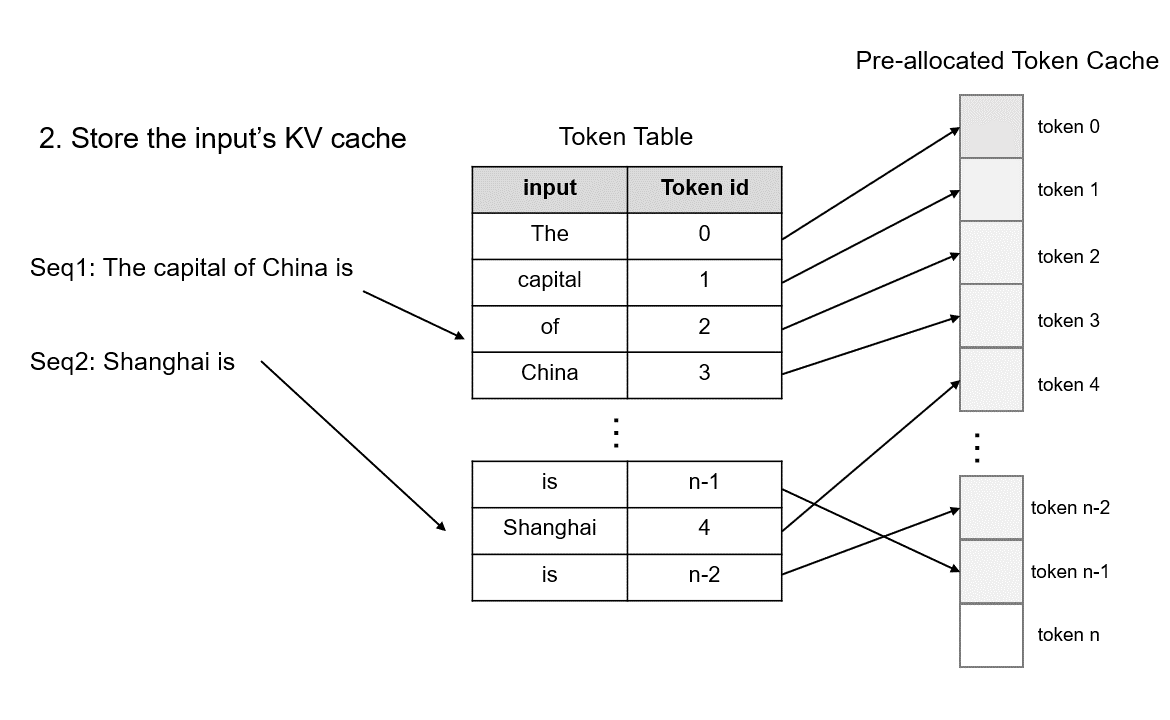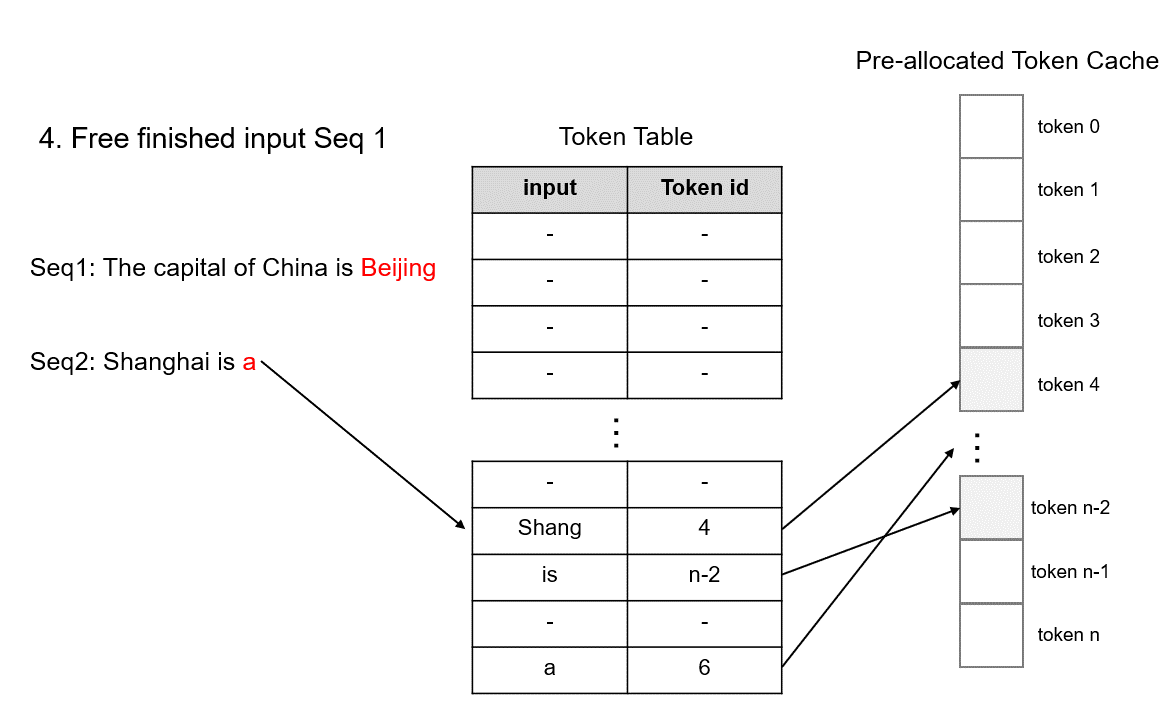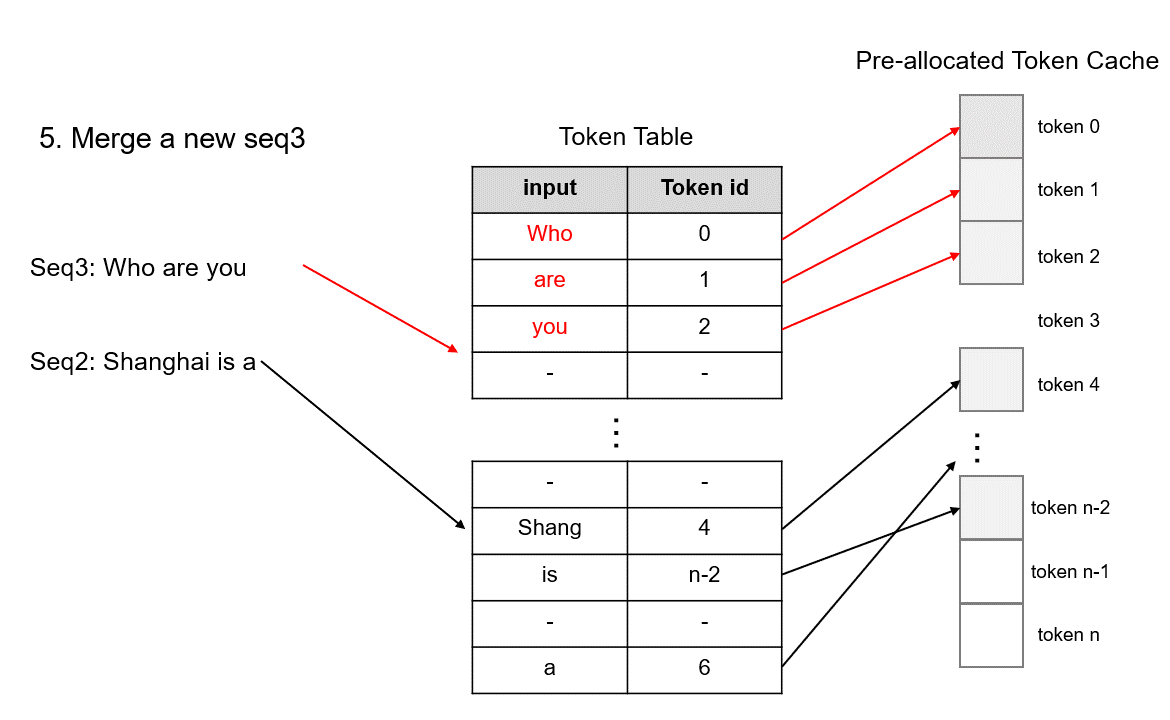
TokenAttention 的运行机制如下图所示,具体原理描述请参考 lightllm 官方文档。
1.5 SGLang
SGLang 一些区别于其他框架或者自身做的好的特性:
- 采用了编译器方式的设计。
- 提出
RadixAttention共享KVCache Prefix。 - 使用
torch.compile技术优化 Latency,在基准测试中产生高达 1.5 倍的加速效果。 - 支持
LLaVA-OneVision模型,和 hf 推理相比,SGLang 实现了高达 4.5 倍的速度提升。 - 针对
DeepSeek团队提出的多头潜在注意力(MLA一种新的注意力机制),做了权重吸收、分组解码内核、FP8 批量矩阵乘法(MatMul)、以及 FP8 键值缓存量化等优化工作,测试结果显示比基准系统提高了 3 到 7 倍。
SGLang的整体架构,模块上分为前端和后端,整体功能上有 4 个大的功能分别为前端 SGLang 语言、RadixAttention、fast constrained decoding 和 API Speculative Execution。
性能对比:
和 vllm 相比,SGLang 在 Llama-70B 模型上的吞吐量实现了3.1x 倍的提升。Llama-70B 模型在 8xA100 上推理的吞吐量测试结果。

更多性能基准测试请查阅官方博客。我仔细看了下,SGLang 团队宣称的吞吐量、latency 提升是在输入 tokens > 1024 和输出 tokens > 512 的情况,即同时处于 Prefill-heavy 和 Decode-heay 的数据集情况下的的性能测试结果。在日常聊天场景下的基准性能测试结果我在博客上没看到。
个人推测在大 seq_len 和 output_len 上的提升可能是来源于
kernel针对这种场景做了定制化优化,具体的话得去看 kernel 源码,并做消除实验对比,后面有时间再研究下。