vllm 优化之 PagedAttention 源码解读
Categories: LLM_Infer
PagedAttention 算法的原理可以参考我前面写的文章vllm优化技术速览。从源码的角度来看 PagedAttention,其实可以分为两部分:
- PagedAttention Kernel 的实现,这里 v1 算法计算逻辑部分和标准 attention 差不多(v2 计算逻辑和 flashattentionv2 一致),但是 kv cache 的分配和管理使用了 kv cache 动态管理、存取优化技术。
- PagedAttention 的对 kv cache 的内存分配管理技术(KV cache manager),之前的 kv cache 在
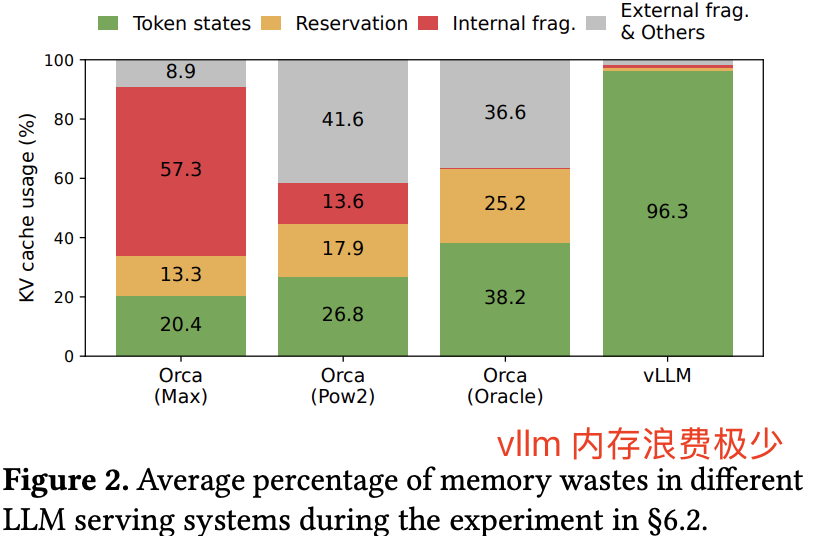
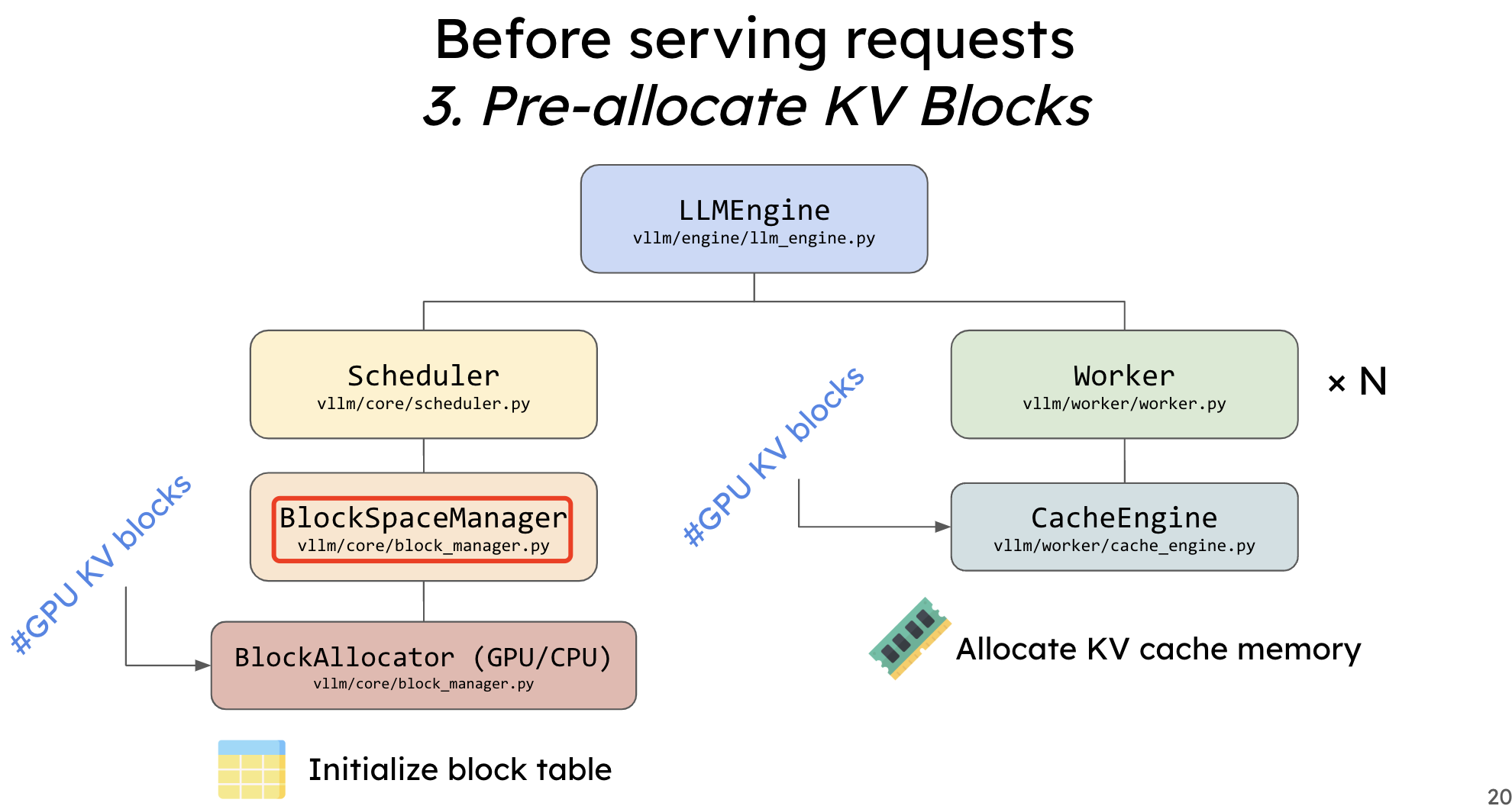
seq这个维度都是固定为最大输入尺寸的max_seq_len, 但实际单个请求可能消耗这么多内存,且在请求推理结束后也没有释放对应内存的功能,这必然会造成大量的内存浪费和碎片化。由此 PagedAttention 算法基于操作系统的page table思想构建了block table来动态分配管理 kv cache 内存,下图很好的展示了相比早前的其他推理框架,LLM 在显存利用率上极高。这种 kv cache 内存管理分配的算法(思想)是可以应用到其他 llm 推理服务框架中。
一 PagedAttention 内核
1.1 主要函数
看一个文件代码之前,先快速过一下这个文件有哪些主要(模板)类或者函数,vllm 中 pagedattention 内核的实现 csrc/attention/attention_kernels.cu 文件中,其主要有以下模板函数。
template <typename scalar_t, typename cache_t, int HEAD_SIZE, int BLOCK_SIZE,
int NUM_THREADS, vllm::Fp8KVCacheDataType KV_DTYPE,
bool IS_BLOCK_SPARSE,
int PARTITION_SIZE = 0> // Zero means no partitioning.
__device__ void paged_attention_kernel()
// v2 内核的算法实现逻辑对应的就是 Flashattentionv1
// Grid: (num_heads, num_seqs, 1).
template <typename scalar_t, typename cache_t, int HEAD_SIZE, int BLOCK_SIZE,
int NUM_THREADS, vllm::Fp8KVCacheDataType KV_DTYPE,
bool IS_BLOCK_SPARSE>
__global__ void paged_attention_v1_kernel()
// v2 内核的算法实现逻辑对应的就是 Flashattentionv2, 因此并行度多了一个 kv cache seq!并行数量为 max_num_partitions.
// Grid: (num_heads, num_seqs, max_num_partitions).
template <typename scalar_t, typename cache_t, int HEAD_SIZE, int BLOCK_SIZE,
int NUM_THREADS, vllm::Fp8KVCacheDataType KV_DTYPE,
bool IS_BLOCK_SPARSE,
int PARTITION_SIZE>
__global__ void paged_attention_v2_kernel()
// paged_attention_v1 内核的包装函数
template <typename T, typename CACHE_T, int BLOCK_SIZE,
vllm::Fp8KVCacheDataType KV_DTYPE, bool IS_BLOCK_SPARSE,
int NUM_THREADS = 128>
void paged_attention_v1_launcher()
// paged_attention_v2 内核的包装函数
template <typename T, typename CACHE_T, int BLOCK_SIZE,
vllm::Fp8KVCacheDataType KV_DTYPE, bool IS_BLOCK_SPARSE,
int NUM_THREADS = 128, int PARTITION_SIZE = 512>
void paged_attention_v2_launcher()
// paged_attention_v1 对外提供的接口函数,也是生成 python 调用接口的函数形式,部分参数我省略了
void paged_attention_v1(
torch::Tensor& out, // [num_seqs, num_heads, head_size]
torch::Tensor& query, // [num_seqs, num_heads, head_size]
torch::Tensor& key_cache, // [num_blocks, num_heads, head_size/x, block_size, x]
torch::Tensor& value_cache, // [num_blocks, num_heads, head_size, block_size]
int64_t num_kv_heads, // [num_heads]
double scale,
torch::Tensor& block_tables, // [num_seqs, max_num_blocks_per_seq]
torch::Tensor& seq_lens, // [num_seqs]
int64_t block_size, int64_t max_seq_len,
)
// paged_attention_v2 对外提供的接口函数,参数和 v1 类似
void paged_attention_v2()
PagedAttention 本质上是集合了 kv cache 动态管理技术的优化版 flashattention。PagedAttention 的内核实现有两个版本 paged_attention_v1_kernel 和 paged_attention_v2_kernel,v1 改编自FasterTransformers 的 MHA 实现,适合长度小于 8192 或者 num_seqs * num_heads > 512 的情况,v2 是参考 FlashDecoding 方式进行实现,对 sequence 维度进行切分以增加并行粒度。
这两个版本的内核都是基于 paged_attention_kernel 内核通过输入不同参数来实现,v2 内核版本多了一个 kv cache seq 维度分区数量的参数,并行度层面多了 kv cache seq 分区的并行度!
flashattention 两种算法实现集成在一个内核里,这还是很考验作者工程功底的!
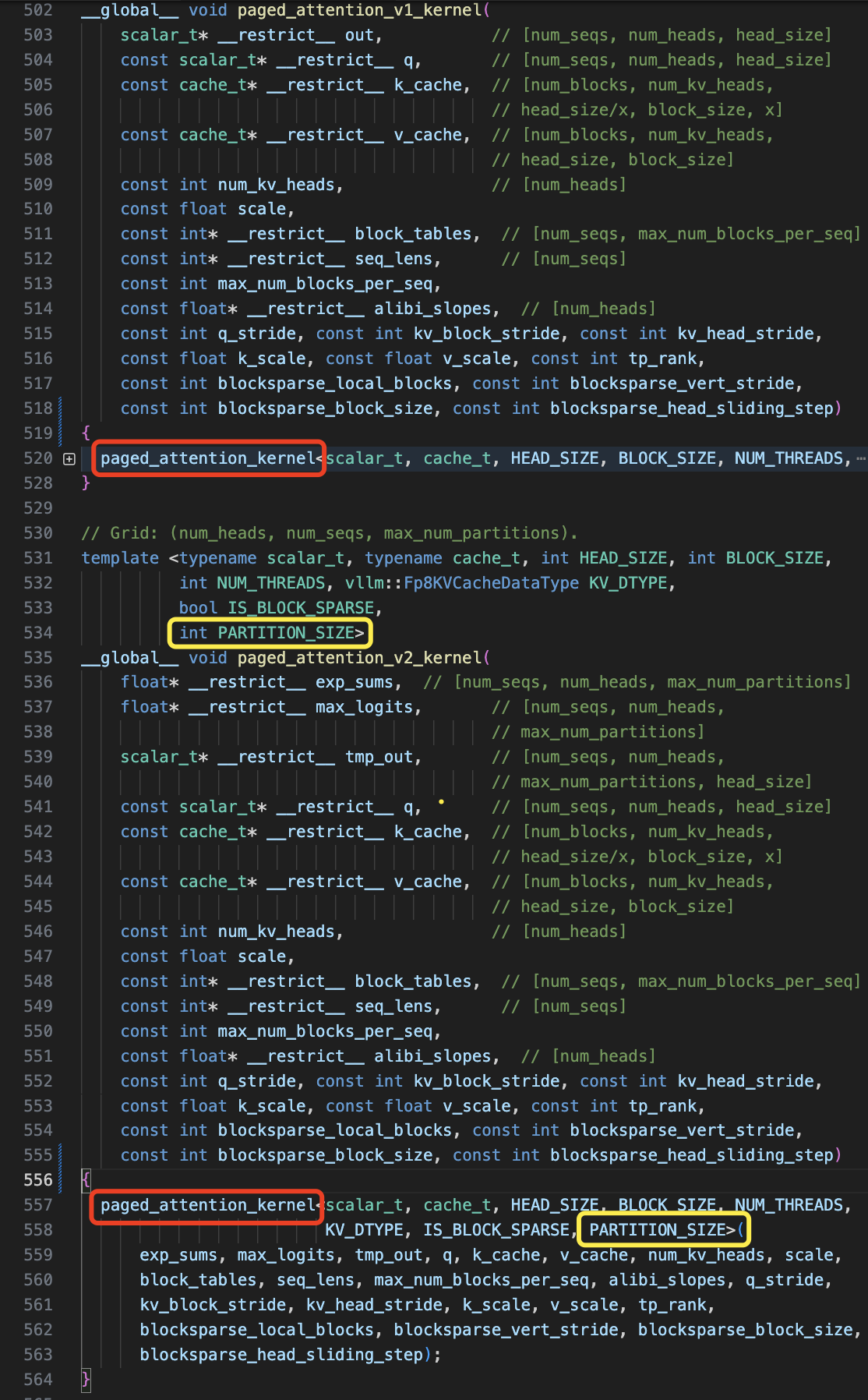
PagedAttention 内核的实现函数和常规 Attention 的实现相比最明显的就是多了 blocks 相关参数,以及 k_cache 的尺寸变成了 [num_blocks, num_kv_heads, head_size/x, block_size, x],很明显了多了 num_blocks 和 block_size 维度(v_cache 变量也是),用于表示一个 seq 用多少个 blocks 存储,以及每个 block 存储多少个 tokens。
PagedAttention kernel 模板函数签名如下所示:
// Grid: (num_heads, num_seqs, 1).
// 这里为了方便阅读我删除了块稀疏的参数
template <typename scalar_t, typename cache_t, int HEAD_SIZE, int BLOCK_SIZE, int NUM_THREADS>
__global__ void paged_attention_v1_kernel(
scalar_t* __restrict__ out, // [num_seqs, num_heads, head_size]
const scalar_t* __restrict__ q, // [num_seqs, num_heads, head_size]
const cache_t* __restrict__ k_cache, // [num_blocks, num_kv_heads, head_size/x, block_size, x], 最后一个x 是 vectorize,一个thread fetch一个vector
const cache_t* __restrict__ v_cache, // [num_blocks, num_kv_heads, head_size, block_size]
const int num_kv_heads, // [num_heads]
const float scale,
const int* __restrict__ block_tables, // [num_seqs, max_num_blocks_per_seq]
const int* __restrict__ seq_lens, // [num_seqs]
const int max_num_blocks_per_seq,
const float* __restrict__ alibi_slopes, // [num_heads]
const int q_stride, const int kv_block_stride, const int kv_head_stride,
const float k_scale, const float v_scale)
1.2 内核配置定义
先阅读 paged_attention_v1_kernel() 内核的调用(包装)函数 paged_attention_v1_launcher() 的 内容来看 kernel 的配置如何。
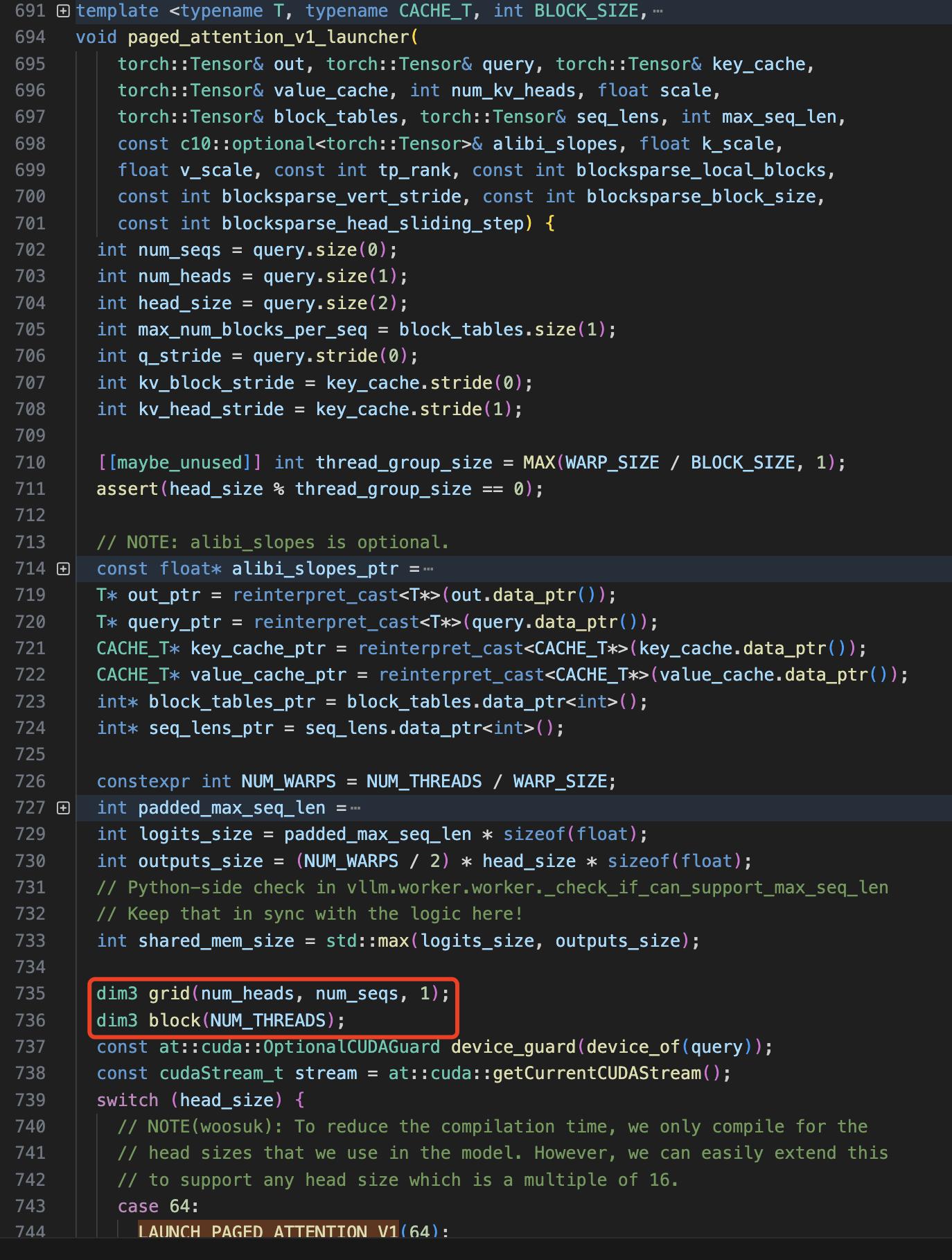
可以看出 kernel 的 grid 和 block 配置如下所示,即分别定义了二维 grid 和一维 block 配置,其中每个 BLOCKS_X 处理一个 head,每个 BLOCKS_Y 处理一个 seq,每个 thread 处理最后一个维度 hidden_size 的计算。
dim3 grid(num_heads, num_seqs); // dim3 grid(BLOCKS_X, BLOCKS_Y)
dim3 block(NUM_THREADS);
知道了 kernel 的配置,我们再回过头去看 kernel 源码-paged_attention_kernel() 模板函数,按照 kernel 编写惯例,开头的代码依然是先计算全局线程 id 和偏移,只保留 v1 内核相关且注释后的代码如下所示:
// 用于对整数除法结果进行向上取整。
#define DIVIDE_ROUND_UP(a, b) (((a) + (b) - 1) / (b))
void paged_attention_kernel()
{
/****** seq 维度的线程索引和 blocks 数量计算 ********/
// 获取当前请求序列 seq 的索引,基于网格的 y 维度
const int seq_idx = blockIdx.y;
// 获取当前请求的实际长度,即 tokens 数量
const int seq_len = seq_lens[seq_idx];
// 计算序列被分割成多少个块,每块大小为 BLOCK_SIZE
const int num_seq_blocks = DIVIDE_ROUND_UP(seq_len, BLOCK_SIZE);
// 未启用分区处理(USE_PARTITIONING 为 false),起始块索引为 0。
const int num_blocks = num_seq_blocks
// 计算当前 block 块的起始和结束索引
const start_block_idx = 0
const end_block_idx = num_blocks
// 计算当前 block 处理的令牌(token)范围
const int start_token_idx = start_block_idx * BLOCK_SIZE
const int end_token_idx = end_block_idx * BLOCK_SIZE
// 计算 warp 数量
constexpr int NUM_WARPS = NUM_THREADS / WARP_SIZE;
// 获取当前线程在块内的索引
const int thread_idx = threadIdx.x;
// 计算当前线程所在的 warp 索引
const int warp_idx = thread_idx / WARP_SIZE;
// 计算当前线程在 warp 内的 lane 索引
const int lane = thread_idx % WARP_SIZE;
/****** num_heads 维度的 kv head 索引计算 ********/
// 兼容了 GQA 技术的 kv head 地址计算
// 获取当前查询头的索引,基于网格的 x 维度
const int head_idx = blockIdx.x;
const int num_heads = gridim.x;
// 计算每个 Key/Value 头对应的查询头数, 看到没,GQA 是可以集成到 attention 内核里面的!
const int num_queries_per_kv = num_heads / num_kv_heads;
// 计算当前 Key/Value 头的索引
const int kv_head_idx = head_idx / num_queries_per_kv
/****** thread group 向量化load&store 相关代码, 不太理解 *****/
// 定义线程组大小和数量
constexpr int THREAD_GROUP_SIZE = MAX(WARP_SIZE / BLOCK_SIZE, 1);
constexpr int NUM_THREAD_GROUPS =
NUM_THREADS / THREAD_GROUP_SIZE; // 确保 THREAD_GROUP_SIZE 能整除 NUM_THREADS
assert(NUM_THREADS % THREAD_GROUP_SIZE == 0);
// 定义向量类型,用于存储部分 Key 或 Query
// 向量大小配置为线程组中的线程数 * 向量大小保证16字节对齐
constexpr int VEC_SIZE = MAX(16 / (THREAD_GROUP_SIZE * sizeof(scalar_t)), 1);
using K_vec = typename Vec<scalar_t, VEC_SIZE>::Type;
using Q_vec = typename Vec<scalar_t, VEC_SIZE>::Type;
using Quant_vec = typename Vec<cache_t, VEC_SIZE>::Type;
// 每个线程处理的元素数
constexpr int NUM_ELEMS_PER_THREAD = HEAD_SIZE / THREAD_GROUP_SIZE;
// 每个线程处理的向量数
constexpr int NUM_VECS_PER_THREAD = NUM_ELEMS_PER_THREAD / VEC_SIZE;
// 计算线程组索引和偏移
const int thread_group_idx = thread_idx / THREAD_GROUP_SIZE;
const int thread_group_offset = thread_idx % THREAD_GROUP_SIZE;
// 查询地址计算
const scalar_t* q_ptr = q + seq_idx * q_stride + head_idx * HEAD_SIZE;
}
通过注释我们可以发现最前面代码的核心就是计算 seq、num_heads 维度的索引以及线程组索引和偏移。
1.3 基于 block_tables 读取 kv cache
这部分代码是真正属于 pagedattention 原创性的设计,即如何基于 block_tables 去 token 的 offset。
- 首先就是:获取当前序列 (seq_idx) 的块表。
block_tables是一个二维数组,每个序列有最多max_num_blocks_per_seq个块。通过 seq_idx * max_num_blocks_per_seq 计算当前序列的块表起始地址。 - 遍历 Key 块。
- 获取物理块号:
block_table[block_idx]。 - 循环加载 Key 向量、计算点积和更新 qk_max。
- 最外层循环: 每个 warp 负责计算一个 block key,而每个 block key shape 为
[block_size, num_head, head_size] - 第二层循环: 每个thread_group取一个key,即num_head个元素,计算QK dot
- 最外层循环: 每个 warp 负责计算一个 block key,而每个 block key shape 为
// x == THREAD_GROUP_SIZE * VEC_SIZE
// Each thread group fetches x elements from the key at a time.
constexpr int x = 16 / sizeof(cache_t);
// 获取当前序列的块表,确定要迭代的 Key 块。
// block_tables 是函数参数,形状为 [num_seqs, max_num_blocks_per_seq] 的二维数组,每个序列有最多 max_num_blocks_per_seq 个块。
// 通过 seq_idx * max_num_blocks_per_seq 计算当前序列的块表起始地址。
const int* block_table = block_tables + seq_idx * max_num_blocks_per_seq;
// 每个 warp 负责 blocksize * headsize 个元素
for (int block_idx = start_block_idx + warp_idx; block_idx < end_block_idx; block_idx += NUM_WARPS) {
// 获取当前块的物理块号,并将其转换为 int64_t 以避免溢出。
const int64_t physical_block_number = static_cast<int64_t>(block_table[block_idx]);
// 加载一个 Key 向量到寄存器。
// 每个线程组中的每个线程处理 Key 的不同部分。
// 例如,如果线程组大小为 4,则组中的第一个线程处理 0, 4, 8,... 向量,第二个线程处理 1, 5, 9,... 向量,依此类推。
for (int i = 0; i < NUM_TOKENS_PER_THREAD_GROUP; i++) {
// 在当前 physical block 中找到当前 thread group 负责的局部 token id
const int physical_block_offset =
(thread_group_idx + i * WARP_SIZE) % BLOCK_SIZE;
// 计算 token 在当前 seq 的所有 block 中的全局索引。
const int token_idx = block_idx * BLOCK_SIZE + physical_block_offset;
// 声明一个用于存储多个 Key 向量的数组。
K_vec k_vecs[NUM_VECS_PER_THREAD];
// 遍历每个向量,加载 Key 向量到 k_vecs 数组。
// 根据上述 shape 算出当前 seq 的具体 k cache 的 block size 这一维度的 offset
for (int j = 0; j < NUM_VECS_PER_THREAD; j++) {
// k_cache.shape=[num_blocks, num_kv_heads, head_size/x, block_size, x]
const cache_t* k_ptr =
k_cache + physical_block_number * kv_block_stride +
kv_head_idx * kv_head_stride + physical_block_offset * x;
// 因为是向量化 LOAD,还需要计算出 vec 的全局id,和 vec 内元素的局部 offset
const int vec_idx = thread_group_offset + j * THREAD_GROUP_SIZE;
const int offset1 = (vec_idx * VEC_SIZE) / x;
const int offset2 = (vec_idx * VEC_SIZE) % x;
// 根据 Key 缓存的数据类型,加载并转换 Key 向量。
if constexpr (KV_DTYPE == Fp8KVCacheDataType::kAuto) {
// 直接加载 Key 向量。
k_vecs[j] = *reinterpret_cast<const K_vec*>(
k_ptr + offset1 * BLOCK_SIZE * x + offset2);
} else {
// 从量化向量转换为 Key 向量。
Quant_vec k_vec_quant = *reinterpret_cast<const Quant_vec*>(
k_ptr + offset1 * BLOCK_SIZE * x + offset2);
k_vecs[j] = fp8::scaled_convert<K_vec, Quant_vec, KV_DTYPE>(
k_vec_quant, k_scale);
}
}
// 计算查询与 Key 的点积。
// 这包括线程组内的归约操作。
float qk = scale * Qk_dot<scalar_t, THREAD_GROUP_SIZE>::dot(
q_vecs[thread_group_offset], k_vecs);
// 如果提供了 ALiBi 斜率,则添加偏置。
qk += (alibi_slope != 0) ? alibi_slope * (token_idx - seq_len + 1) : 0;
// 如果当前线程组偏移量为 0,则进行以下操作:
if (thread_group_offset == 0) {
// 计算当前令牌是否超出序列长度,用于掩码。
const bool mask = token_idx >= seq_len;
// 如果掩码为真,则将 logits 设为 0;否则,设为计算的 qk。
logits[token_idx - start_token_idx] = mask ? 0.f : qk;
// 更新查询与 Key 的最大值,用于后续的 softmax 计算。
qk_max = mask ? qk_max : fmaxf(qk_max, qk);
}
}
}
后续的代码就是去更新 softmax 和姨同样的操作去加载 v, 然后再做 gemv(softmax(qk^t) * v),最终得到 attention 输出,这里不再分析具体算法逻辑。
二 Paged(页表)原理分析
这里的算法分析重点在于分析如何创建 block table、实现逻辑 table 和物理 table 的映射,以及如何针对每个 seq 动态分配相应数量的 block 用于存储 kv cache。
这块代码的实现是在 vllm 的请求调度层模块里,请求调度模块的作用是将服务接收到的请求进行状态管理,包括入队出队操作,并且将请求解析成推理引擎的输入,由 Worker 模块完成模型推理。
请求调度的核心源码在:vllm/core/scheduler.py 文件中。核心实现在 Scheduler 类中,这个类中的 _schedule 函数调用内部的相关完成具体的请求调度。另外,调度器中的下发 batch 请求到 Worker 模块中的相关函数,如 _schedule_prefills 函数会先调用 block_manager.can_allocate 函数判断是否有足够内存分配。而在初始化方法 __init__ 函数有 kv cache 显存块状态管理器的初始化。具体代码如下所示:
def __init__(
self,
scheduler_config: SchedulerConfig,
cache_config: CacheConfig,
lora_config: Optional[LoRAConfig],
pipeline_parallel_size: int = 1,
output_proc_callback: Optional[Callable] = None,
) -> None:
self.scheduler_config = scheduler_config
self.cache_config = cache_config
# Note for LoRA scheduling: the current policy is extremely
# simple and NOT fair. It can lead to starvation of some
# LoRAs. This should be improved in the future.
self.lora_config = lora_config
version = "selfattn"
if (self.scheduler_config.task == "embedding"
or self.cache_config.is_attention_free):
version = "placeholder"
BlockSpaceManagerImpl = BlockSpaceManager.get_block_space_manager_class(
version)
# Create the block space manager.
self.block_manager = BlockSpaceManagerImpl(
block_size=self.cache_config.block_size,
num_gpu_blocks=cache_config.num_gpu_blocks,
num_cpu_blocks=cache_config.num_cpu_blocks,
sliding_window=self.cache_config.sliding_window,
enable_caching=self.cache_config.enable_prefix_caching)
初始化函数中定义的块管理器 block_manager 就是我们关心的,它是 KVCache 显存块状态管理器。用于分配、释放 KVCache 显存块以及状态更新,分配显存块时会返回显存块 id,用于 PagedAttention 计算时获取 KVCache 块显存地址。
值得注意的是,BlockManager(和调度器)实际上只负责管理页表(即管理逻辑块和每个 seq 到物理块的映射关系),实际的物理块中的数据不由它管理。这个实际上和 os 中的页表也差不多,BlockManager中的一个物理块就相当于页表中的一个PTE,而不是真实存放数据的物理块,实际进行内存分配的是 CacheEngine。
2.1 Block 管理相关类
BlockManager 相关类的包装关系对应文件: block_manager.py -> block_table.py -> naive_block.py
BlockTable
block_table.py 文件的 BlockTable 类将 tokens 序列映射到块列表 blocks 中,其中每个 block 代表序列一部分的连续内存分配。这些块由 DeviceAwareBlockAllocator 管理,它负责分配和释放这些逻辑块。
其中 SelfAttnBlockSpaceManager 类继承自
BlockSpaceManager,父类只负责定义接口,子类才负责具体的实现。
BlockTable 类最主要的函数是 allocate 用于将 tokens 序列映射相应物理内存块列表 blocks 中,具体物理内存块的分配是通过设备内存分配器的分配函数 ` self._allocator.allocate_immutable_blocks` 实现的。
class BlockTable:
"""管理特定序列的内存块的类。
BlockTable 将一系列令牌映射到一组块中,每个块代表序列的一部分连续内存分配。这些块由 DeviceAwareBlockAllocator 管理,负责块的分配和释放。
参数:
block_size (int): 每个内存块可以存储的最大令牌数量。
block_allocator (DeviceAwareBlockAllocator): 用于管理物理块内存的分配器。
_blocks (Optional[List[Block]], optional): 可选的现有块列表,用于初始化 BlockTable。如果未提供,则创建一个空的 BlockTable。
max_block_sliding_window (Optional[int], optional): 每个序列需要保留的最大块数。如果为 None,则保留所有块(例如,当不使用滑动窗口时)。至少应满足模型的滑动窗口大小。
属性:
_block_size (int): 每个内存块可以存储的最大令牌数量。
_allocator (DeviceAwareBlockAllocator): 用于管理物理块内存的分配器。
_blocks (Optional[List[Block]]): 由此 BlockTable 管理的逻辑块列表。
_num_full_slots (int): 当前存储在块中的令牌数量。
"""
def __init__(
self,
block_size: int,
block_allocator: DeviceAwareBlockAllocator,
_blocks: Optional[List[Block]] = None,
max_block_sliding_window: Optional[int] = None,
):
self._block_size = block_size # 设置每个块的大小
self._allocator = block_allocator # 设置内存分配器
if _blocks is None:
_blocks = []
self._blocks: BlockList = BlockList(_blocks) # 初始化块列表
self._max_block_sliding_window = max_block_sliding_window # 设置滑动窗口的最大块数
self._num_full_slots = self._get_num_token_ids() # 获取当前存储的令牌数量
def allocate(self,
token_ids: List[int],
device: Device = Device.GPU) -> None:
"""为给定的令牌序列分配内存块。
此方法分配所需数量的块以存储给定的令牌序列。
参数:
token_ids (List[int]): 要存储的令牌 ID 序列。
device (Device, optional): 要分配块的设备。默认为 GPU。
"""
assert not self._is_allocated # 确保尚未分配块
assert token_ids # 确保有令牌需要分配
blocks = self._allocate_blocks_for_token_ids(prev_block=None,
token_ids=token_ids,
device=device) # 分配块
self.update(blocks) # 更新块表
self._num_full_slots = len(token_ids) # 更新存储的令牌数量
def _allocate_blocks_for_token_ids(self, prev_block: Optional[Block],
token_ids: List[int],
device: Device) -> List[Block]:
"""为给定的令牌 ID 分配内存块。
参数:
prev_block (Optional[Block]): 前一个块。如果没有,则为 None。
token_ids (List[int]): 要存储的令牌 ID 列表。
device (Device): 要分配块的设备。
返回:
List[Block]: 分配的块列表。
"""
blocks: List[Block] = []
block_token_ids = []
tail_token_ids = []
for cur_token_ids in chunk_list(token_ids, self._block_size):
if len(cur_token_ids) == self._block_size:
block_token_ids.append(cur_token_ids)
else:
tail_token_ids.append(cur_token_ids)
if block_token_ids:
blocks.extend(
self._allocator.allocate_immutable_blocks(
prev_block, block_token_ids=block_token_ids,
device=device)) # 分配不可变块
prev_block = blocks[-1]
if tail_token_ids:
assert len(tail_token_ids) == 1 # 仅有一个尾块
cur_token_ids = tail_token_ids[0]
block = self._allocator.allocate_mutable_block(
prev_block=prev_block, device=device) # 分配可变块
block.append_token_ids(cur_token_ids) # 追加令牌 ID
blocks.append(block)
return blocks
def update(self, blocks: List[Block]) -> None:
"""重置块表为新提供的块(包括其对应的块 ID)。
参数:
blocks (List[Block]): 新分配的块列表。
"""
self._blocks.update(blocks)
_allocate_blocks_for_token_ids 函数会据块大小 (block_size) 将令牌序列分割成多个块,并使用 DeviceAwareBlockAllocator 来分配这些块。具体函数流程总结如下:
- 创建空块列表:
blocks: List[Block] = [],也是函数返回的结果 - 分配逻辑块列表,通过分割 token ids 实现,每个子逻辑 block 包含的内容实际是 token ids。
- 分配实际物理块列表: 调用 _ allocator.allocate_immutable_blocks 函数返回实际块列表,并拓展到逻辑块列表
blocks中。 - 返回分配的块列表
blocks。
下述是一个测试示例,展示如何使用 _allocate_blocks_for_token_ids 方法:
def test_allocate_blocks_for_token_ids():
# 初始化分配器和 BlockTable
allocator = DeviceAwareBlockAllocator()
block_size = 4
block_table = BlockTable(block_size=block_size, block_allocator=allocator)
# 定义测试令牌 ID
token_ids = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# 分配块
allocated_blocks = block_table._allocate_blocks_for_token_ids(
prev_block=None,
token_ids=token_ids,
device=Device.GPU
)
# 更新块表
block_table._blocks.update(allocated_blocks)
block_table._num_full_slots = len(token_ids)
# 打印分配结果
print("分配的块数量:", len(allocated_blocks))
for i, block in enumerate(allocated_blocks):
print(f"块 {i}: Token IDs = {block.token_ids}, Mutable = {block.mutable}")
# 预期:
# - 前两个块完全填满(4个令牌)
# - 最后一个块不完全填满(1个令牌,5)
# 所以应有 3 个块
assert len(allocated_blocks) == 3, "应分配 3 个块"
assert allocated_blocks[0].token_ids == [1, 2, 3, 4], "第一个块令牌 ID 错误"
assert allocated_blocks[1].token_ids == [5, 6, 7, 8], "第二个块令牌 ID 错误"
assert allocated_blocks[2].token_ids == [9], "第三个块令牌 ID 错误"
assert not allocated_blocks[0].mutable, "第一个块应为不可变块"
assert not allocated_blocks[1].mutable, "第二个块应为不可变块"
assert allocated_blocks[2].mutable, "第三个块应为可变块"
print("测试通过!")
if __name__ == "__main__":
test_allocate_blocks_for_token_ids()
运行上述测试代码,结果如下所示:
分配的块数量: 3
块 0: Token IDs = [1, 2, 3, 4], Mutable = False
块 1: Token IDs = [5, 6, 7, 8], Mutable = False
块 2: Token IDs = [9], Mutable = True
测试通过!
CpuGpuBlockAllocator 类
前面的分析内容我们知道,请求到逻辑表的分配是通过 CpuGpuBlockAllocator 类实现的。CpuGpuBlockAllocator 类是一个内存块分配器,能够在 CPU 和 GPU 内存中分配和管理内存块。它实现了 DeviceAwareBlockAllocator 基类的接口,提供了在多个设备(如 CPU 和 GPU)之间分配、释放、分叉(forking)和交换(swapping)内存块的功能。
class CpuGpuBlockAllocator(DeviceAwareBlockAllocator):
"""一个能够在 CPU 和 GPU 内存中分配块的块分配器。
该类实现了 `DeviceAwareBlockAllocator` 接口,提供了在 CPU 和 GPU 设备上分配和管理内存块的功能。
`CpuGpuBlockAllocator` 维护了独立的 CPU 和 GPU 内存块池,并允许在这些内存池之间进行分配、释放、分叉和交换操作。
"""
@staticmethod
def create(
allocator_type: str,
num_gpu_blocks: int,
num_cpu_blocks: int,
block_size: int,
) -> DeviceAwareBlockAllocator:
"""创建一个具有指定配置的 CpuGpuBlockAllocator 实例。
这个静态方法根据提供的参数创建并返回一个 CpuGpuBlockAllocator 实例。它初始化了 CPU 和 GPU 块分配器,指定块的数量、块大小和分配器类型。
参数:
allocator_type (str): 用于 CPU 和 GPU 块的块分配器类型。目前支持的值为 "naive" 和 "prefix_caching"。
num_gpu_blocks (int): 要为 GPU 内存分配的块数量。
num_cpu_blocks (int): 要为 CPU 内存分配的块数量。
block_size (int): 每个块的大小,以令牌数量表示。
返回:
DeviceAwareBlockAllocator: 一个具有指定配置的 CpuGpuBlockAllocator 实例。
注意:
- 块 ID 是连续分配的,GPU 块 ID 在前,CPU 块 ID 在后。
"""
# 对于 HPU,块 ID 0 仅用于填充
reserved_blocks = 1 if current_platform.is_hpu() else 0
block_ids = list(
range(reserved_blocks, num_gpu_blocks + num_cpu_blocks))
num_gpu_blocks -= reserved_blocks
gpu_block_ids = block_ids[:num_gpu_blocks]
cpu_block_ids = block_ids[num_gpu_blocks:]
# 根据 allocator_type 创建不同类型的块分配器
if allocator_type == "naive":
gpu_allocator: BlockAllocator = NaiveBlockAllocator(
create_block=NaiveBlock, # 创建不可变块的函数
num_blocks=num_gpu_blocks,
block_size=block_size,
block_ids=gpu_block_ids,
)
cpu_allocator: BlockAllocator = NaiveBlockAllocator(
create_block=NaiveBlock, # 创建不可变块的函数
num_blocks=num_cpu_blocks,
block_size=block_size,
block_ids=cpu_block_ids,
)
elif allocator_type == "prefix_caching":
gpu_allocator = PrefixCachingBlockAllocator(
num_blocks=num_gpu_blocks,
block_size=block_size,
block_ids=gpu_block_ids,
)
cpu_allocator = PrefixCachingBlockAllocator(
num_blocks=num_cpu_blocks,
block_size=block_size,
block_ids=cpu_block_ids,
)
else:
raise ValueError(f"未知的分配器类型 {allocator_type=}")
return CpuGpuBlockAllocator(
cpu_block_allocator=cpu_allocator,
gpu_block_allocator=gpu_allocator,
)
def __init__(self, cpu_block_allocator: BlockAllocator,
gpu_block_allocator: BlockAllocator):
"""初始化 CpuGpuBlockAllocator 实例。
参数:
cpu_block_allocator (BlockAllocator): 用于管理 CPU 内存块的分配器。
gpu_block_allocator (BlockAllocator): 用于管理 GPU 内存块的分配器。
"""
# 确保 CPU 和 GPU 分配器的块 ID 没有交集
assert not (
cpu_block_allocator.all_block_ids
& gpu_block_allocator.all_block_ids
), "CPU 和 GPU 块分配器的块 ID 不能有交集"
# 将 CPU 和 GPU 分配器存储在字典中
self._allocators = {
Device.CPU: cpu_block_allocator,
Device.GPU: gpu_block_allocator,
}
self._swap_mapping: Dict[int, int] = {} # 记录交换操作的块 ID 映射
self._null_block: Optional[Block] = None # 用于存储空块
# 记录每个块 ID 对应的分配器
self._block_ids_to_allocator: Dict[int, BlockAllocator] = {}
for _, allocator in self._allocators.items():
for block_id in allocator.all_block_ids:
self._block_ids_to_allocator[block_id] = allocator
def allocate_mutable_block(self, prev_block: Optional[Block],
device: Device) -> Block:
"""在指定设备上分配一个新的可变块。
参数:
prev_block (Optional[Block]): 序列中的前一个块。用于前缀哈希。
device (Device): 要分配新块的设备。
返回:
Block: 新分配的可变块。
"""
return self._allocators[device].allocate_mutable_block(prev_block)
def allocate_immutable_blocks(self, prev_block: Optional[Block],
block_token_ids: List[List[int]],
device: Device) -> List[Block]:
"""在指定设备上分配一组包含提供的块令牌 ID 的不可变块。
参数:
prev_block (Optional[Block]): 序列中的前一个块。用于前缀哈希。
block_token_ids (List[int]): 要存储在新块中的块令牌 ID 列表。
device (Device): 要分配新块的设备。
返回:
List[Block]: 新分配的包含提供的块令牌 ID 的不可变块列表。
"""
return self._allocators[device].allocate_immutable_blocks(
prev_block, block_token_ids)
NaiveBlockAllocator
上述类其实也还是一层包装,在看针对不同场景的类,以简单的 NaiveBlockAllocator 类为例分析。
class NaiveBlockAllocator(BlockAllocator):
"""一个简单的块分配器,不支持前缀缓存。
该类实现了 `BlockAllocator` 接口,提供了基本的内存块分配和释放功能。
参数:
create_block (Block.Factory): 用于创建新块的工厂函数。当 NaiveBlockAllocator 被前缀缓存分配器组合使用时,必须能够创建前缀缓存块(但不应了解其余细节)。
num_blocks (int): 要管理的块的总数量。
block_size (int): 每个块的大小,以令牌数量表示。
block_ids (Optional[Iterable[int]], optional): 可选的块 ID 可迭代对象。如果未提供,块 ID 将从 0 到 `num_blocks - 1` 顺序分配。
"""
def __init__(
self,
create_block,
num_blocks: int,
block_size: int,
block_ids: Optional[Iterable[int]] = None,
block_pool: Optional[BlockPool] = None,
):
if block_ids is None:
block_ids = range(num_blocks) # 如果未提供块 ID,则顺序分配
self._free_block_indices: deque = deque(block_ids) # 初始化自由块队列
self._all_block_indices = frozenset(block_ids) # 所有块 ID 的集合
assert len(self._all_block_indices) == num_blocks, "块 ID 数量应与 num_blocks 相等"
self._refcounter = RefCounter(
all_block_indices=self._free_block_indices)
self._block_size = block_size
self._cow_tracker = CopyOnWriteTracker(
refcounter=self._refcounter)
if block_pool is None:
extra_factor = 4
# 预分配 "num_blocks * extra_factor" 个块对象。
# "* extra_factor" 是为了允许分配比物理块更多的块对象
self._block_pool = BlockPool(self._block_size, create_block, self,
num_blocks * extra_factor)
else:
# 在这种情况下,块池由调用者提供,意味着可能需要在分配器之间共享块池
self._block_pool = block_pool
def allocate_immutable_blocks(
self,
prev_block: Optional[Block],
block_token_ids: List[List[int]],
device: Optional[str] = None) -> List[Block]:
"""分配一组新的不可变块,包含提供的块令牌 ID,并链接到前一个块。
参数:
prev_block (Optional[Block]): 序列中的前一个块。如果为 None,则分配的块为序列中的第一个块。
block_token_ids (List[List[int]]): 要存储在新块中的块令牌 ID 列表。
device (Optional[str], optional): 分配块的设备。对于 NaiveBlockAllocator,通常为 None。
返回:
List[Block]: 新分配的不可变块列表。
"""
assert device is None, "NaiveBlockAllocator 不支持设备参数"
num_blocks = len(block_token_ids) # 需要分配的块数量
block_ids = []
for i in range(num_blocks):
block_ids.append(self._allocate_block_id()) # 分配块 ID
blocks = []
for i in range(num_blocks):
# 初始化块,设置前一个块、令牌 ID、块大小和物理块 ID
prev_block = self._block_pool.init_block(
prev_block=prev_block,
token_ids=block_token_ids[i],
block_size=self._block_size,
physical_block_id=block_ids[i])
blocks.append(prev_block)
return blocks
def allocate_mutable_block(self,
prev_block: Optional[Block],
device: Optional[str] = None) -> Block:
"""分配一个新的可变块,并链接到前一个块。
参数:
prev_block (Optional[Block]): 序列中的前一个块。如果为 None,则分配的块为序列中的第一个块。
device (Optional[str], optional): 分配块的设备。对于 NaiveBlockAllocator,通常为 None。
返回:
Block: 新分配的可变块。
"""
assert device is None, "NaiveBlockAllocator 不支持设备参数"
block_id = self._allocate_block_id() # 分配一个块 ID
block = self._block_pool.init_block(prev_block=prev_block,
token_ids=[], # 初始化为空令牌 ID
block_size=self._block_size,
physical_block_id=block_id)
block.mutable = True # 设置为可变块
return block
NaiveBlockAllocator 类的块函数也是调用 self._block_pool.init_block 接口,再跳转到 vllm/core/block/common.py 文件 BlockPool 类的 init_block 函数,其是通过 create_block: Block.Factory 类的相关接口来实现的。
也就是说 NaiveBlockAllocator、CpuGpuBlockAllocator 和 PrefixCachingBlockAllocator 三个 block 分配器类是为了适应不同设备和场景(简单场景和 PrefixCaching)而设计出来的,但真正的 block 定义类是通过块工厂创建函数 Block.Factory 创建得到。
BlockList 类
BlockList 类通过维护块及其对应的 ID 列表,优化对物理块 ID 的访问。提供方法来更新列表、向块添加令牌 ID,以及检索块或其 ID,避免在每次迭代块管理器时重新构建块 ID 列表。
class BlockList:
"""This class is an optimization to allow fast-access to physical
block ids. It maintains a block id list that is updated with the
block list and this avoids the need to reconstruct the block id
list on every iteration of the block manager
"""
def __init__(self, blocks: List[Block]):
self._blocks: List[Block] = []
self._block_ids: List[int] = []
self.update(blocks)
def _add_block_id(self, block_id: Optional[BlockId]) -> None:
assert block_id is not None
self._block_ids.append(block_id)
def _update_block_id(self, block_index: int,
new_block_id: Optional[BlockId]) -> None:
assert new_block_id is not None
self._block_ids[block_index] = new_block_id
#####省略代码######
逻辑 block 管理类-SelfAttnBlockSpaceManager
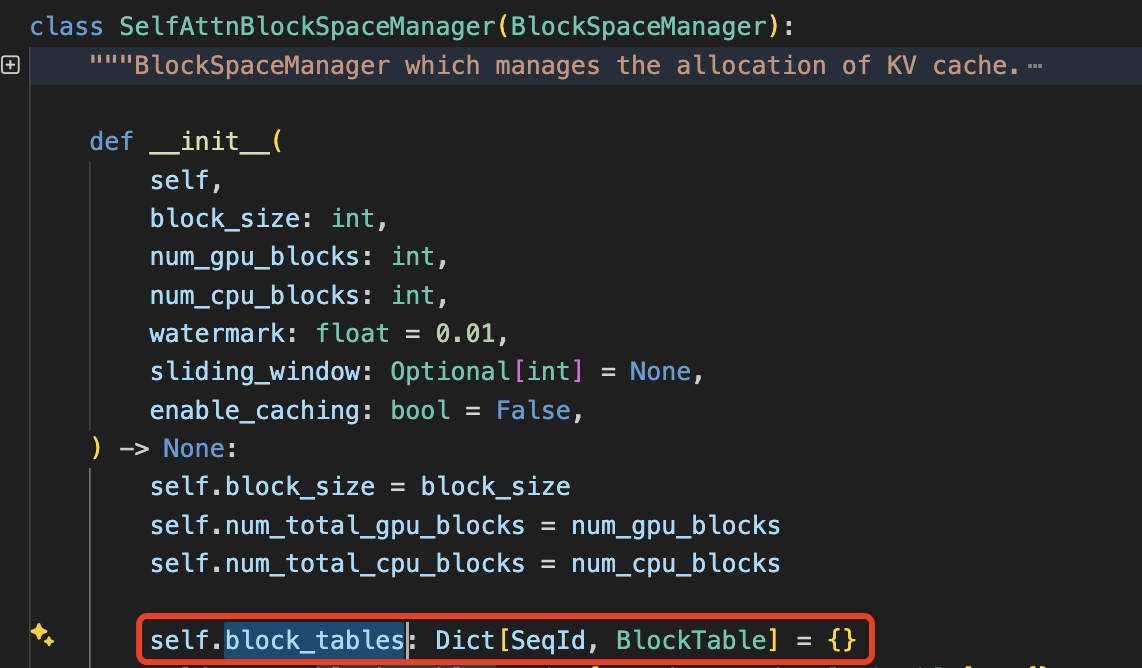
SelfAttnBlockSpaceManager 类用于管理注意力机制中 KV(Key-Value)缓存块,主要负责逻辑内存块的分配、交换、以及其他高级功能如前缀缓存(即请求共享前缀systemp prompt)、分叉/写时复制(Forking/Copy-on-Write)和滑动窗口内存分配。
和前面几个是 block 模块内部类不同,它是对外部模块提供的类,但 BlockManager(和调度器)实际上只负责管理页表(即管理每个 seq 到物理块的映射关系),实际的物理块中的数据不由它管理。
先看构造函数 __init__(),函数中维护了一个逻辑 block_tables,它是一个字典,形式如 block_tables: Dict[SeqId, BlockTable] = {},这个字典维护着整个 vllm 系统中每个 Sequence 实例到它的 block_table 之间的映射关系,方便快速查找到当前文本序列(Sequence) 对应的 PhysicalTokenBlock。构造函数的输入参数比较多,这里重点看三个参数的意义:
block_size: 每个内存块的大小,表示可以存储多少个令牌的 KV 数据。num_gpu_blocks: 分配在 GPU 上的内存块数量。num_cpu_blocks: 分配在 CPU 上的内存块数量。
__init__() 的部分代码如下所示:
SelfAttnBlockSpaceManager 类中内存块分配相关有 allocate 和 _allocate_sequence 函数,分别用于为给定的序列组分配所需的内存块和为单个序列分配块表。
块的分配策略由 CpuGpuBlockAllocator 来实现,分配策略有 naive 和 prefix_caching 两种。CpuGpuBlockAllocator 是一个管理 CPU 和 GPU 内存块的分配器类,继承自 DeviceAwareBlockAllocator,提供了在 CPU 和 GPU 设备上分配和管理内存块的功能。
块的分配策略类涉及到 4 个类,它们的类图关系如下所示:
classDiagram
DeviceAwareBlockAllocator <-- CpuGpuBlockAllocator
BlockAllocator <-- NaiveBlockAllocator
class DeviceAwareBlockAllocator {
+allocate_mutable_block()
+allocate_immutable_block()
+free()
}
class BlockAllocator {
+allocate_mutable_block()
+allocate_immutable_block()
+free()
}
class CpuGpuBlockAllocator {
-_allocators: Dict
+create()
+swap()
}
class NaiveBlockAllocator {
-_free_blocks: List
+allocate_block()
+free()
}
类的关系说明:
- DeviceAwareBlockAllocator
- 顶层接口
- 定义设备相关的内存块分配方法
- CpuGpuBlockAllocator 实现此接口
- BlockAllocator
- 基础抽象类
- 定义基本的内存块分配操作
- NaiveBlockAllocator 继承此类
- CpuGpuBlockAllocator
- 实现 DeviceAwareBlockAllocator 接口
- 内部使用 BlockAllocator 的具体实现(如 NaiveBlockAllocator)
- 管理 CPU 和 GPU 两种设备上的内存块
- NaiveBlockAllocator
- BlockAllocator 的简单实现
- 被 CpuGpuBlockAllocator 使用来管理具体设备上的内存块
2.2 slot mapping
上一节讲的 block_tables 是逻辑层面的,而传给实际计算 kernel 的 block_tables 是形状为 [batch_size, max_blocks_per_seq] 的 torch.Tensor 表示每个序列的块地址列表,第一维表示序列 ID,第二维是物理块列表。
- 例如,[0, 1, 2] 表示 tokens 存储在 kv cache 的第 0、1 和 2 个块中。
- 每个块最多可容纳 block_size 个 tokens。
- 如果启用了 cuda-graph 捕获,则第二维将填充至 max_blocks_per_seq 的大小。
block_tables: Optional[torch.Tensor]
另外 vllm/attention/backends/utils.py 文件中提供了一些函数用于计算“槽映射”(slot mapping),并将序列中的 token 索引映射到内存块中的槽索引。
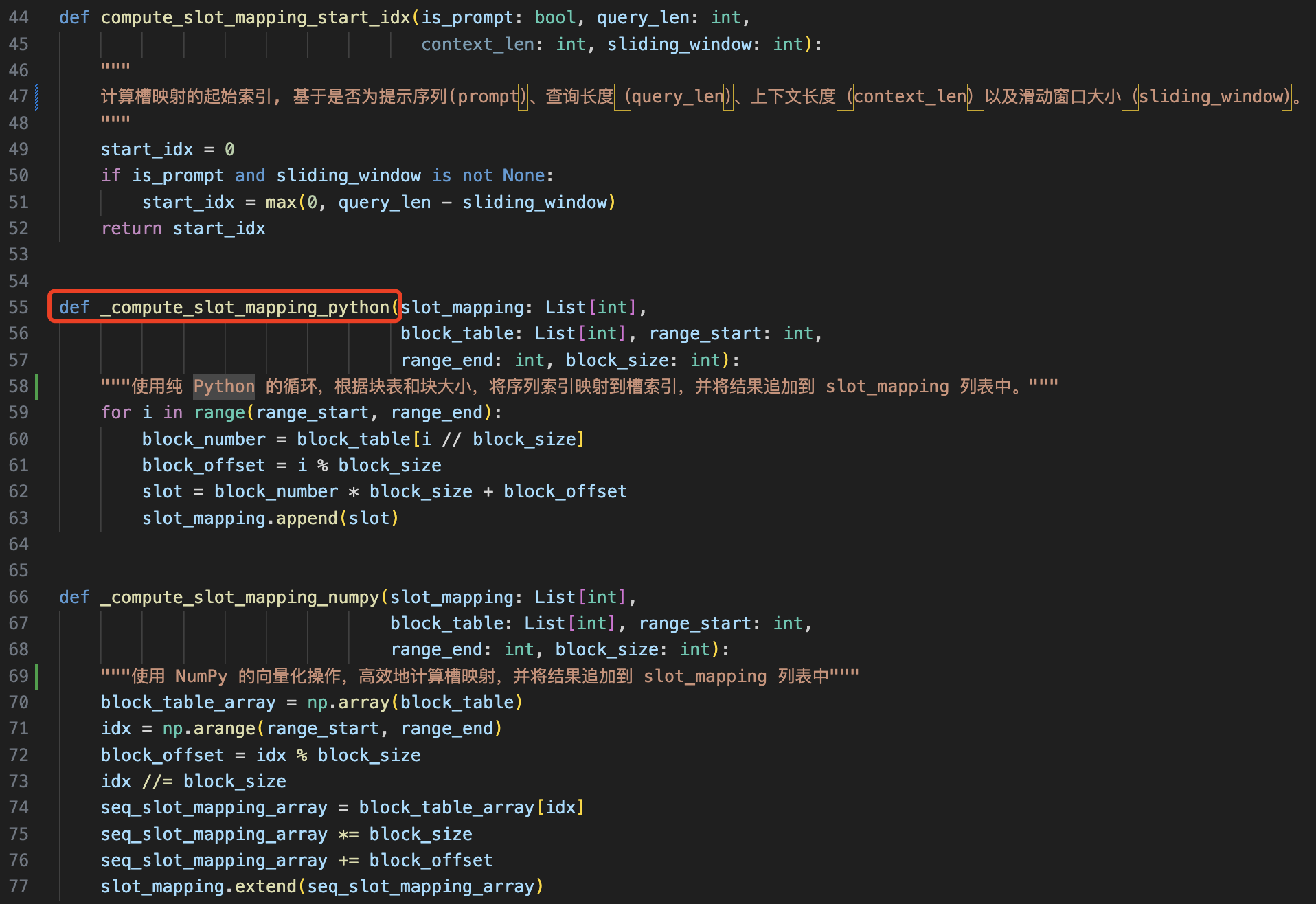
主函数 compute_slot_mapping,根据是否进行性能分析、是否需要填充以及使用哪种实现方式(Python 或 NumPy),计算序列的槽映射。
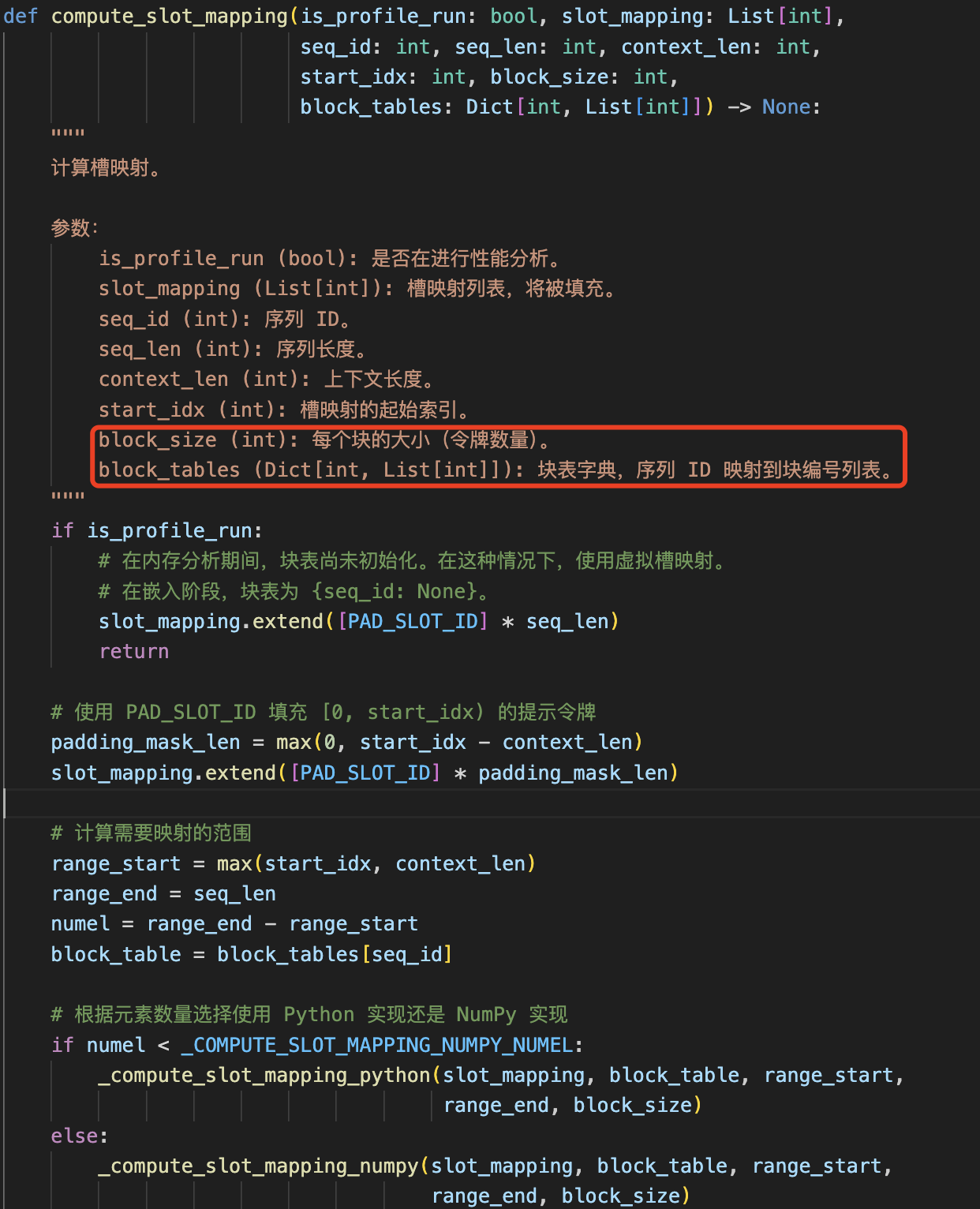
在模型 forward 过程中调用 flash_attention 做注意力分值计算时会按照 slot_mapping 指引位置将本层的 kv cache 存储到 vllm 初始化过程中分配的全零张量中,这在 cuda 函数中实现。
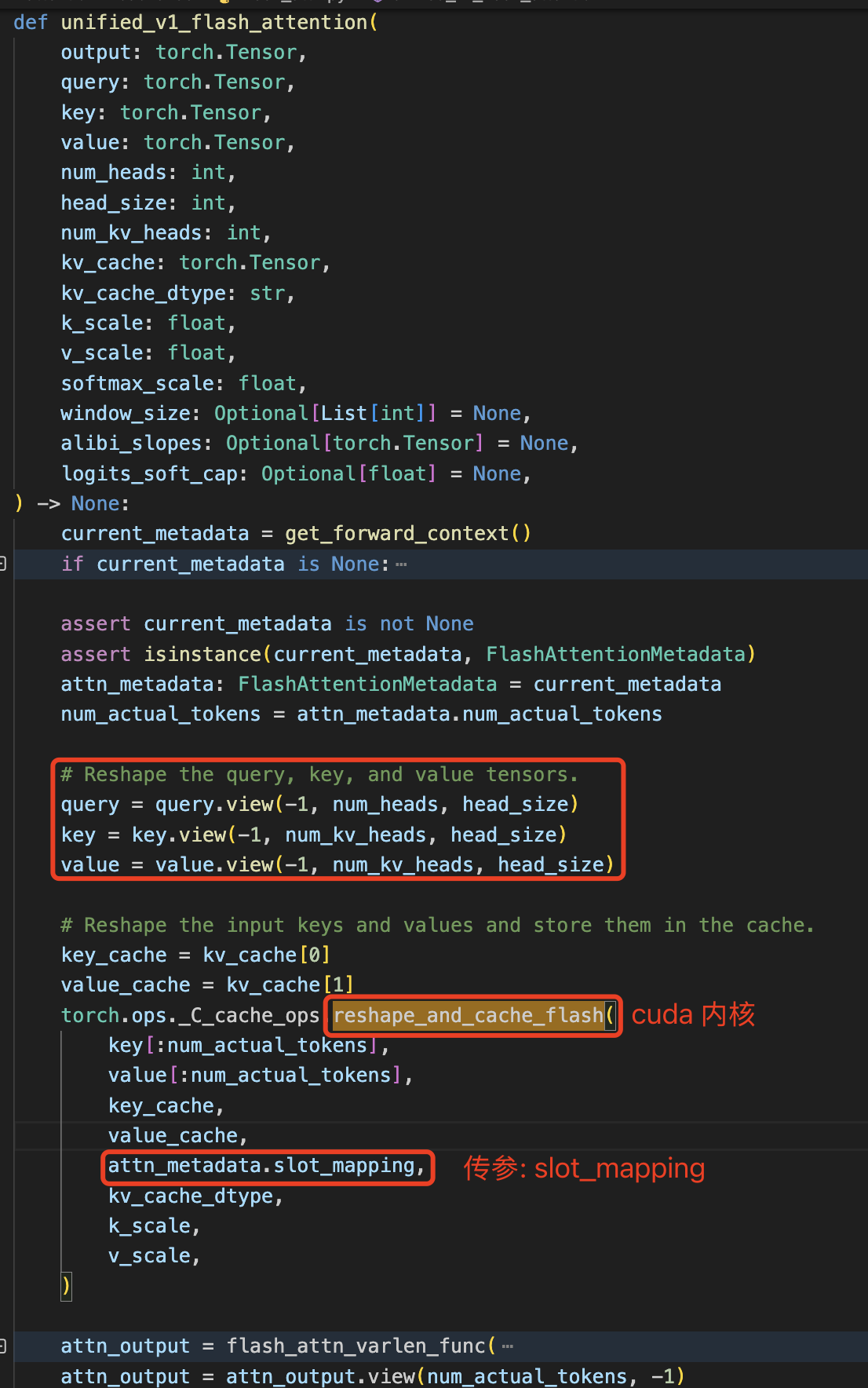
FlashAttentionMetadata 数据类的定义如下:
@dataclass
class FlashAttentionMetadata:
# NOTE(sang): Definition of context_len, query_len, and seq_len.
# |---------- N-1 iteration --------|
# |---------------- N iteration ---------------------|
# |- tokenA -|......................|-- newTokens ---|
# |---------- context_len ----------|
# |-------------------- seq_len ---------------------|
# |-- query_len ---|
num_actual_tokens: int # Number of tokens excluding padding.
max_query_len: int
query_start_loc: torch.Tensor
max_seq_len: int
seq_start_loc: torch.Tensor
block_table: torch.Tensor
slot_mapping: torch.Tensor
2.3 物理 block 分配类-CacheEngine
CacheEngine 给GPU分配空间的方式,本质上通过 pytorch 的接口在 gpu 上分配 num_blocks 大小的零 tensor 来作为物理块的空间的,而不是直接使用 cudaMalloc 进行操作的。
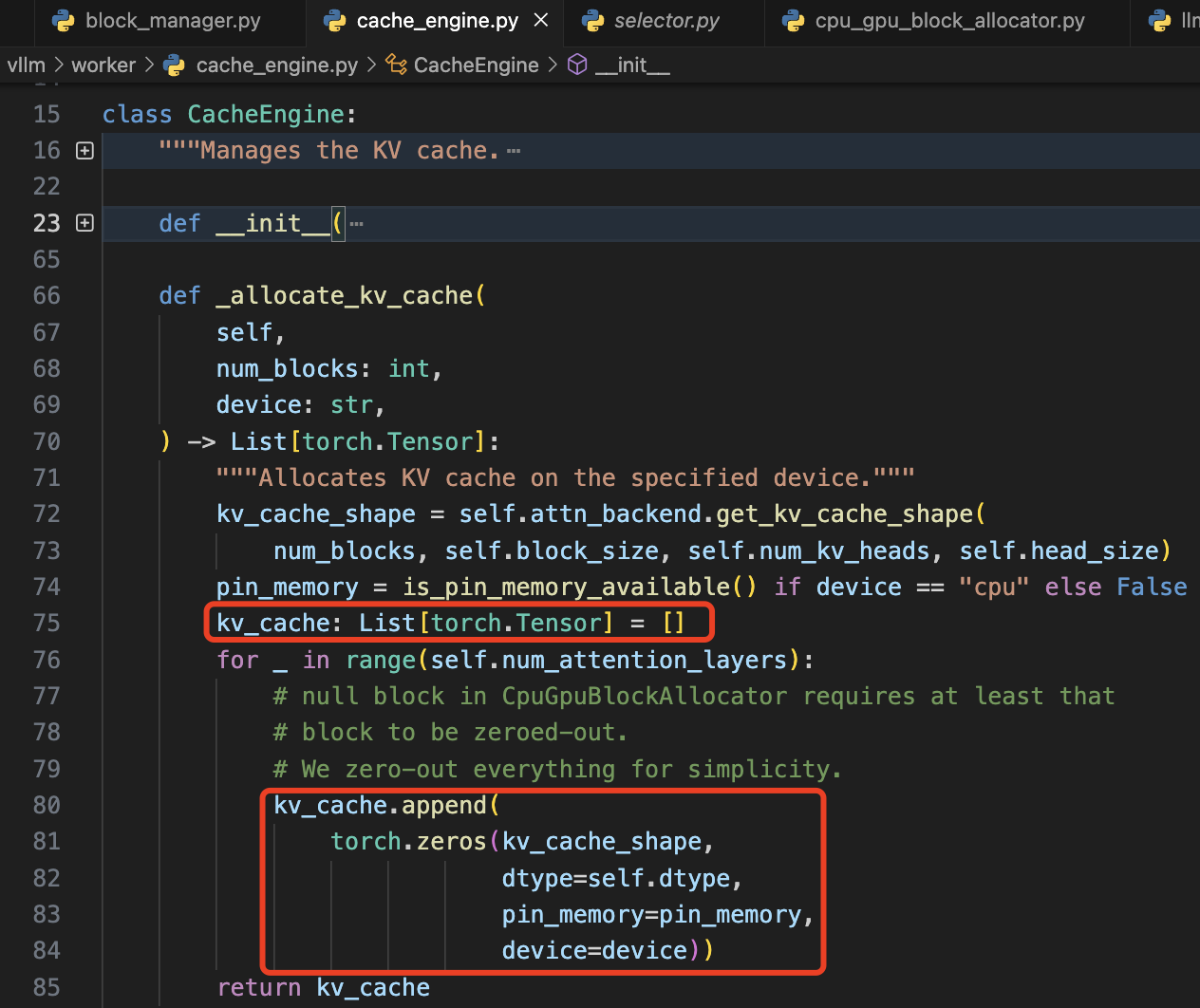
和 lightllm 的 tokenattention 直接提前分配一个可用最大形状的 Tensor,且后续 kv cache 的获取和释放都从这里操作不同。PagedAttention 为 transformer 模型的每个 layer 都分配一个可用最大尺寸的 tensor,并组合成列表的形式。也就是如果模型为 layer 为 16,对应的 kv cache 就是一个拥有 16 个 tensor 的列表。
代码通过循环遍历 self.num_attention_layers,为每个层分配独立的 KV 缓存张量,确保每层的 kv 张量能够被单独存储和访问,避免不同层之间的干扰。num_gpu_blocks 会通过 model_executor.determine_num_available_blocks 函数获取当前模型在指定设备上的每个 layer 的最大可用物理 blocks 数目。
绝大部分后端的 kv_cache_shape 形状都是 [2, num_blocks, block_size, num_kv_heads, head_size]。
# vllm/attention/ops/paged_attn.py
class PagedAttention:
def get_kv_cache_shape(
num_blocks: int,
block_size: int,
num_kv_heads: int,
head_size: int,
) -> Tuple[int, ...]:
return (2, num_blocks, block_size * num_kv_heads * head_size)
其中 block_size 由 llm 服务启动参数设定,而 num_gpu_blocks 既可以在服务启动的时候通过预热自动跑出来,也可通过服务启动参数 num_gpu_blocks_override 由用户自行设定并覆盖 num_gpu_blocks。
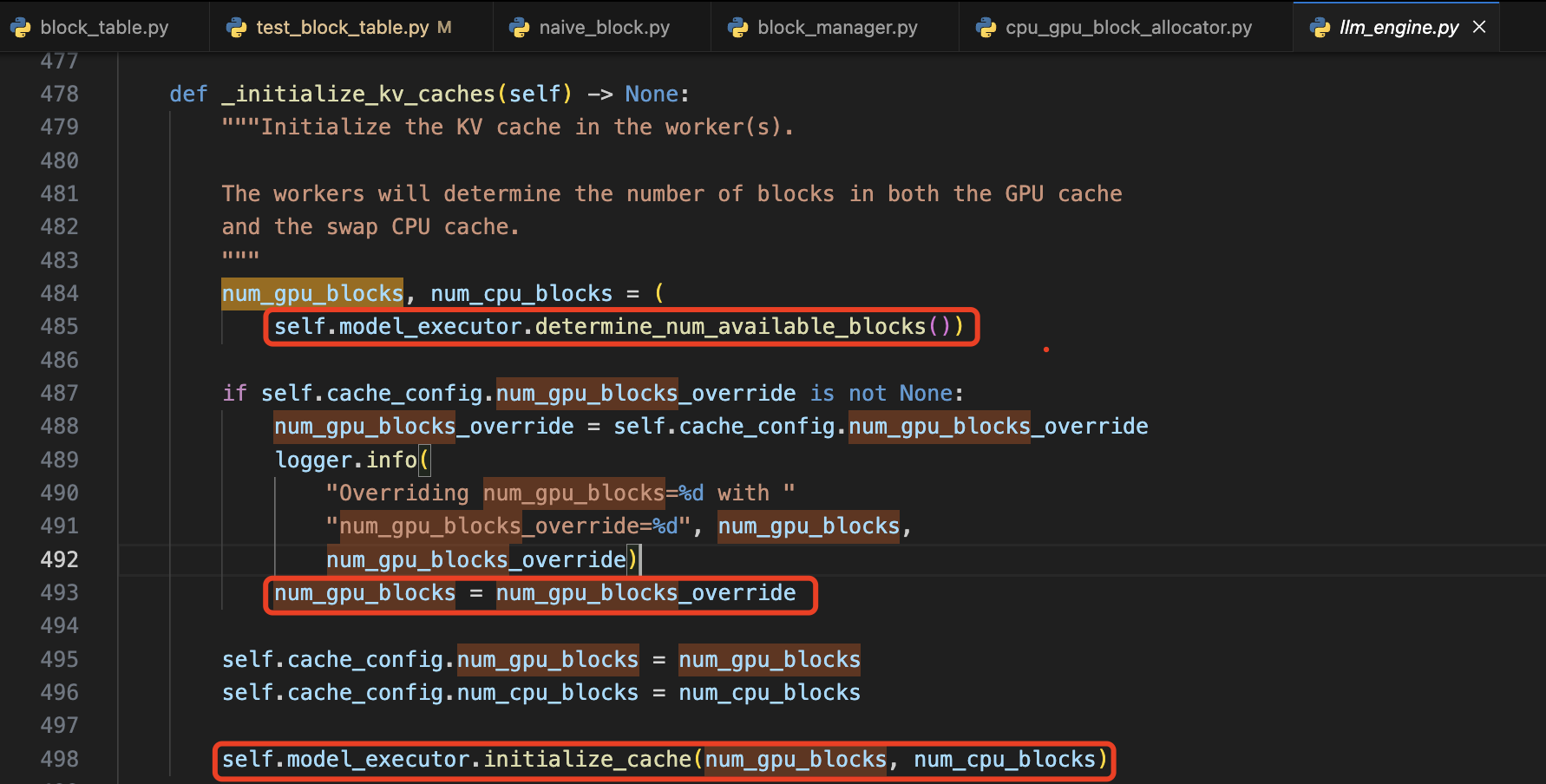
2.3.1 num_gpu_blocks 获取-determine_num_available_blocks 函数
determine_num_available_blocks 函数的具体实现是在 worker 目录下的各个设备的 work.py 实现,先以简单 cpu_work.py 的实现为例分析,cpu 中的 num_gpu_blocks(实际是 cpu 的可用内存块数量)计算是通过理论计算得到的,通过 cpu/gpu 设备可用的内存空间除以相关 kv_cache_block_size 得到可用 blocks 数量。
cache_block_size = self.get_cache_block_size_bytes()
# self.cache_config.cpu_kvcache_space_bytes 可通过环境变量 `VLLM_CPU_KVCACHE_SPACE` 定义
num_cpu_blocks = int(self.cache_config.cpu_kvcache_space_bytes // cache_block_size)
上述代码中的 get_cache_block_size_bytes 函数实际上是先计算对应模型 kv 每个 token 占用的空间,又因为 block_size 表示一个 block 对应 block_size 个 tokens,自然需要再乘以 block_size。get_cache_block_size 具体实现代码如下所示:
值得一提的是,指定设备的 kv cache 可用空间,以及可分配的 tokens 数量,也可以参考我的 llm_counts 工具理论计算得到,代码更优雅,使用更简单。
@staticmethod
def get_cache_block_size(
block_size: int,
cache_dtype: str,
model_config: ModelConfig,
parallel_config: ParallelConfig,
) -> int:
head_size = model_config.get_head_size()
num_heads = model_config.get_num_kv_heads(parallel_config)
num_layers = model_config.get_num_layers(parallel_config)
key_cache_block = block_size * num_heads * head_size
value_cache_block = key_cache_block
# 每层 layer 的 block size
total = num_layers * (key_cache_block + value_cache_block)
if cache_dtype == "auto":
dtype = model_config.dtype
else:
dtype = STR_DTYPE_TO_TORCH_DTYPE[cache_dtype]
dtype_size = torch.tensor([], dtype=dtype).element_size()
return dtype_size * total
gpu_work.py 中的实现的计算逻辑和 cpu_work.py 一样,不同的是,这里借助了 torch.cuda.mem_get_info() 函数直接获取 gpu 总内存和在加载完模型之后的剩余显存。另外,用户在启动 llm 服务时,--block-size 参数可设置的取值范围是 {8,16,32,64,128},默认值是 16。
@torch.inference_mode()
def determine_num_available_blocks(model_config, gpu_memory_utilization = 0.9) -> Tuple[int, int]:
"""
评估模型的峰值内存使用情况,以确定在不发生内存溢出的情况下可以分配的 KV(键值)缓存块的数量。
该方法首先清理 CUDA 缓存,然后使用虚拟输入执行一次前向传播,以评估模型的内存使用情况。
接着,计算在剩余可用内存下,最多可以分配的 GPU 和 CPU 缓存块数量。
提示:
可以通过调整 `gpu_memory_utilization` 参数来限制 GPU 内存的使用。
"""
# 清理 CUDA 缓存,以确保获取准确的内存使用信息
torch.cuda.empty_cache()
# 使用虚拟输入执行一次前向传播,以评估模型的内存使用情况
self.model_runner.profile_run()
# 同步 CUDA 操作,确保内存信息准确
torch.cuda.synchronize()
# 获取当前 GPU 的空闲内存和总内存(单位:字节)
free_memory_pre_profile, total_gpu_memory = torch.cuda.mem_get_info()
# 计算模型加载后的峰值内存使用量
# Get the peak memory allocation recorded by torch
peak_memory = torch.cuda.memory_stats()["allocated_bytes.all.peak"]
# 清理未使用的缓存,计算非Torch分配的内存
torch.cuda.empty_cache()
torch_allocated_bytes = torch.cuda.memory_stats()["allocated_bytes.all.current"]
total_allocated_bytes = torch.cuda.mem_get_info()[1] - torch.cuda.mem_get_info()[0]
non_torch_allocations = total_allocated_bytes - torch_allocated_bytes
if non_torch_allocations > 0:
peak_memory += non_torch_allocations
available_kv_cache_memory = (
total_gpu_memory * gpu_memory_utilization -
peak_memory)
# 计算每个缓存块的大小
cache_block_size = _get_cache_block_size(model_config)
# 计算在剩余可用内存下,最多可以分配的 GPU 缓存块数量
num_gpu_blocks = int(
(total_gpu_memory * gpu_memory_utilization -
peak_memory) // cache_block_size
)
# 确保缓存块数量不为负数
num_gpu_blocks = max(num_gpu_blocks, 0)
logger.info(
"Memory profiling results: total_gpu_memory=%.2fGiB \n"
" initial_memory_usage=%.2fGiB peak_torch_memory=%.2fGiB \n"
" memory_usage_post_profile=%.2fGib \n"
" non_torch_memory=%.2fGiB kv_cache_size=%.2fGiB \n"
" gpu_memory_utilization=%.2f", total_gpu_memory / (1024**3),
(total_gpu_memory - free_memory_pre_profile) / (1024**3),
(peak_memory - non_torch_allocations) / (1024**3),
total_allocated_bytes / (1024**3),
non_torch_allocations / (1024**3),
available_kv_cache_memory / (1024**3),
gpu_memory_utilization)
# 进行垃圾回收,释放未使用的内存
gc.collect()
# 再次清理 CUDA 缓存
torch.cuda.empty_cache()
# 返回可分配的 GPU 和 CPU 缓存块数量(此处 CPU 块数量为 0)
return num_gpu_blocks, 0
总结:至此 vllm 的 pagedattention 内核设计和动态分配、管理 kv cache 内存的模块分析完毕,难点主要有三个:
cpu/gpu设备在指定模型上的可分配的内存blocks的计算;- (不同设备的)
block_tables的创建和管理,以及基于Scheduler的调度策略去分配、释放和回收blocks。 - 最后就是
pagedattention内核代码中相关线程索引和偏移的计算怎么改成基于block_tables的形式,多了三个参数:k_cache, v_cache, block_table,其中block_tables尺寸为 [num_seqs, max_num_blocks_per_seq],v_cache尺寸为 [num_blocks, num_heads, head_size, block_size]。
以上,这都需要反复阅读理解代码才能得到清晰的理解。