CUDA stream 和 event 模块详解
Categories: Hpc
背景知识
cuda api 分类
cuda api 分为两个类型:
- cuda driver api: 以 cu 开头的 api,
- cuda runtime api: 以 cuda 开头的 api, 在 cuda driver api 的更上一层。
runtime API 通过提供隐式初始化、上下文管理和模块管理来简化设备代码管理。这使得代码更简单,但也缺乏 driver API 所具有的那种细粒度控制。
cuda runtime api 模块主要分为 Device、Thread、Stream、Event 和 Memory 管理。
下文介绍的 API 及用法都是指 cuda runtime api。CUDA API 可分为同步和异步两类,同步函数会阻塞 host 端的线程执行,异步函数会立刻将控制权返还给 host 从而继续执行之后的动作。
一 Stream 概述
1.1 Stream 理解
Stream 是一种抽象概念,译为流, 官方定义: A sequence of operations that execute in issue-order on the GPU。其本质上是用来控制 GPU 侧任务(主要是 compute kernel,memory 搬运及 graph)异步执行的顺序,即维护 GPU 任务执行顺序的队列,CUDA runtime 会决定这些任务合适的执行时机。
通过显式或隐式 Stream 能保证 GPU 测的任务执行顺序与CPU 侧定义的提交任务顺序一致。
- Stream 内的 kernels 是串行(顺序)执行的;
- 不同 CUDA 流中的操作可能会并发执行;
- 来自不同 CUDA 流的操作可能会交错执行(interleaved)。
1.2 Stream 应用分析
在 cuda 编程模型中,cpu 和 gpu 是有通信但又可以并行运行任务的机器,gpu 相当于 cpu 的附属硬件, cpu 是 host,gpu 是 device。另外,在 cuda/torch 程序中是可以不指定 Stream 的,因为程序会帮你隐式创建一个默认 Stream(default_stream)。
上面内容我们对 Stream 的意义有了大致的了解,下面再从一个实例来直接感知 cpu、gpu 不同 func 的执行顺序。
一个 CPU thread 和一个 GPU Stream
从时间维度分析 cpu、gpu(stream)任务的执行顺序,是会有两条并行的程序运行线,如下图所示:
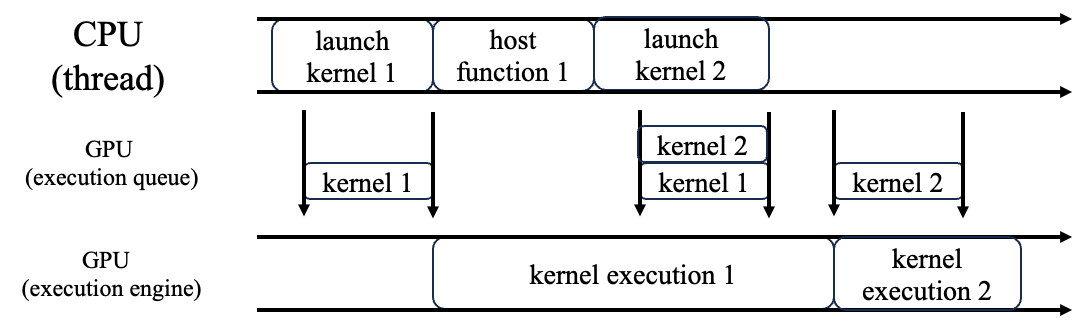
上图 cpu/gpu 任务执行的顺序分析:
- CPU launch kernel 1,kernel 1 入默认 Stream,此时 Stream 里面只有 kernel1,于是 kernel 1 马上在 GPU执行;
- CPU 同步调用 host function,与 GPU 无关
- CPU launch kernel 2,kernel 2 默认 Stream,此时 GPU 还在执行 kernel 1,于是 kernel 2 继续待在任务队列里;
- GPU 执行完 kernel 1后,驱动程序发现队列里还有 kernel 2,于是开始执行 kernel 2(这一步不需要 CPU 参与)。
一个 CPU thread 和四个 GPU Stream
在大部分 cuda 程序中,设计多个 streams 的主要目的是交错执行(interleaved)kernel 计算和内存拷贝。
当使用 CUDA 异步函数和多流(Multi Stream)时,多线程间可以实现并行数据传输与计算交错执行。下图展示了,使用 4 个 streams 和异步方式执行数据传输和计算的并行效果和串行执行的效果对比。
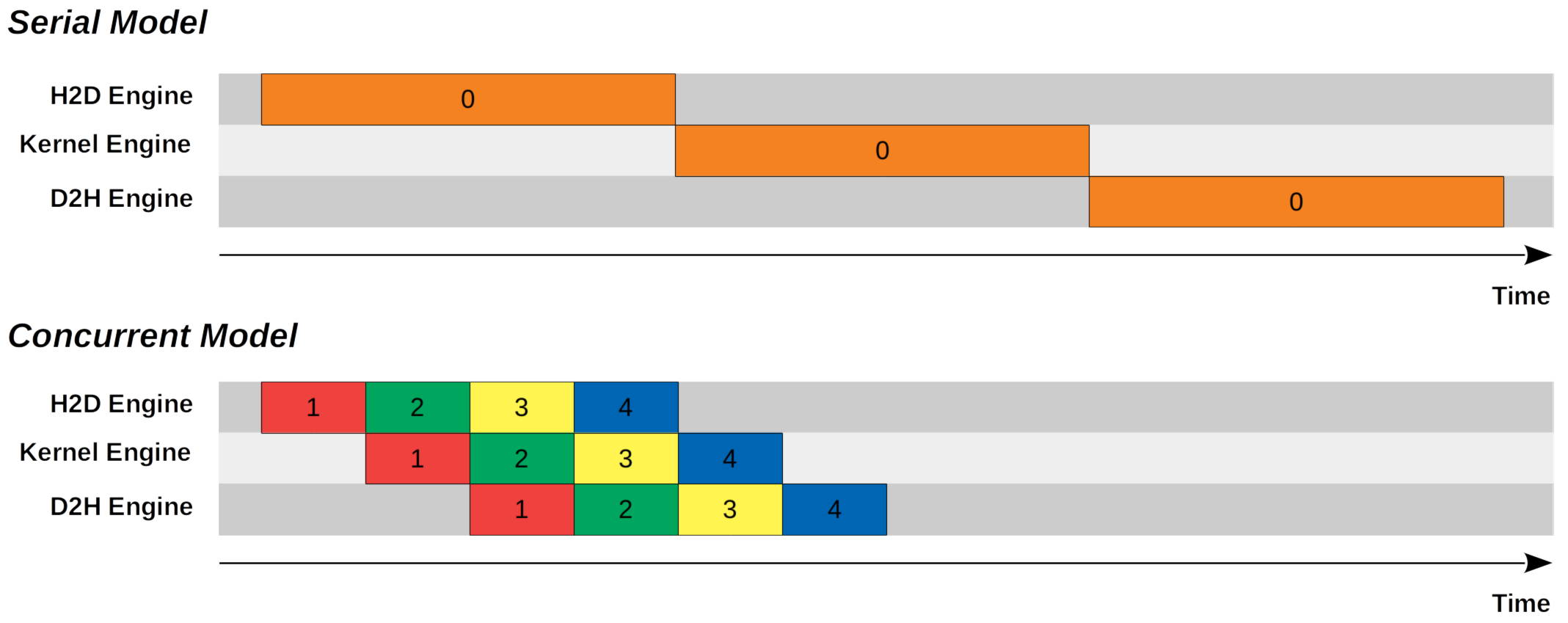
在 Concurrent streams Model 中,我们可以将从 host 到 device 的内存拷贝、 kernel 的执行以及从 device 到 host 的内存拷贝都设为异步操作,同时将内存划分为 $N$ trunks(块)。
在上述具体示例中,设置了 $N=4$。
- 使用
cudaMemcpyAsync函数完成从 host 到 device 的第一个 trunk 拷贝后,我们启动了较小的 kernel 来处理第一个 trunk。 - 同时,host 到 device( H2D )引擎变得可用,并继续将第二个 trunk 从 host 复制到 device。
- 一旦 kernel 处理完第一个 trunk,输出内存就会通过 device 到 host( D2H)引擎复制回 host。与此同时,host 到 device(H2D)引擎和 kernel 引擎变得可用,它们分别继续复制第三个 trunk 从 host 到 device 以及处理第二个 trunk。
从上图可以看出,Concurrent Model 所需的时间仅为 Serial Model 所需时间的一半。
1.3 Streams 数量设置总结
值得注意的是,在 CUDA 中,虽然显式流设计为支持异步执行,但以下情况可能导致操作无法异步执行:
- 存在操作依赖:如果多个流访问相同的内存地址,可能会导致数据竞争,进而导致隐式同步。
- 硬件资源限制:计算核心、内存带宽等资源有限,过多的流同时提交任务可能会导致性能下降,操作被串行化。
- CUDA Kernel 并行执行限制:如果提交的 Kernel 数量超过 GPU 的并发执行能力,剩余 Kernel 将排队等待。
三 Stream API 和用法
3.1 default Stream
默认流用于当 0 作为 cudaStream_t 传递或由隐式操作流的 API 时。
默认流的同步行为可以配置为 legacy 和 per-thread 的同步行为,通过 nvcc --default-stream 选项控制默认 stream 的 行为:
1,Legacy default stream 旧默认流
在较早的 CUDA 版本中,默认 stream(即 stream 0)具有全局同步的特性。任何在默认流上执行的操作会与所有非默认 stream 操作产生同步,保证默认流中的操作在启动前先等待其他 stream 的完成。
2,Per-thread default stream(与非默认流的一致)
从 CUDA 7.0 开始,引入了 per-thread default stream 的概念,这时每个线程都有自己的默认 stream,默认 stream 不再与非默认 stream 隐式同步。这种模式下,默认流行为和非默认流一致,都支持异步执行。
3.2 Stream 管理 API
Stream 管理的 API 在 cuda runtime api 文档的这个链接。
stream 类型为 cudaStream_t:
Stream 模块(类)常用的函数包括:
cudaStreamCreate():创建一个 stream。cudaStreamCreateWithPriority(): 创建一个具有指定优先级的异步流。cudaStreamDestroy:销毁并清理异步 stream。cudaStreamGetDevice(): 查询 stream 的设备。cudaStreamQuery():查询异步 stream 的状态。cudaStreamSynchronize(): 等待 stream 中的任务全部完成。cudaStreamWaitEvent(): 等待事件并使计算 stream 暂停。cudaStreamBeginCapture(): 在流中开始图捕获。
1,创建异步 stream 的接口
- cudaStreamCreate
- cudaStreamCreateWithFlags
- cudaStreamCreateWithPriority: 创建具有指定优先级的异步 stream。
__host__cudaError_t cudaStreamCreate ( cudaStream_t* pStream)
__host____device__cudaError_t cudaStreamCreateWithFlags ( cudaStream_t* pStream, unsigned int flags )
__host__cudaError_t cudaStreamCreateWithPriority ( cudaStream_t* pStream, unsigned int flags, int priority)
2, stream 的同步接口,即等待 stream 的任务队列全部执行完毕。
__host__cudaError_t cudaStreamSynchronize ( cudaStream_t stream)
3,stream 信息查询接口
- cudaStreamGetDevice: 查询 stream 所在的设备。
- cudaStreamGetPriority:查询 stream 的优先级
__host__cudaError_t cudaStreamGetAttribute ( cudaStream_t hStream, cudaStreamAttrID attr, cudaStreamAttrValue* value_out )
__host__cudaError_t cudaStreamGetDevice ( cudaStream_t hStream, int* device )
__host__cudaError_t cudaStreamGetPriority ( cudaStream_t hStream, int* priority )
__host__cudaError_t cudaStreamGetCaptureInfo ( cudaStream_t stream, cudaStreamCaptureStatus ** captureStatus_out, unsigned long long* id_out = 0, cudaGraph_t* graph_out = 0, const cudaGraphNode_t** dependencies_out = 0, size_t* numDependencies_out = 0 )
cudaStreamGetDevice 接口的参数:
hStream:要查询的流的句柄device: 返回该流所属的设备
4,销毁 stream 接口
__host____device__cudaError_t cudaStreamDestroy ( cudaStream_t stream )
下面是一个实例代码,用于验证在默认流(Stream 0)中调用 cudaMemcpyAsync() 后再启动 kernel 的行为,用于加深 stream 内任务顺序执行的理解。
- cudaMemcpyAsync() 和 kernel 启动都不会阻塞主机(host),它们会立即返回;
- 默认流中操作是按顺序执行的,异步内存拷贝必须完成后,后续的 kernel 才能开始执行,从而“阻塞”了 kernel 的启动。
5,stream 等待,直到 event 结束。
// 将所有后续提交到 stream 的工作(任务)等待 event 中捕获的所有工作完成。
__host____device__cudaError_t cudaStreamWaitEvent ( cudaStream_t stream, cudaEvent_t event, unsigned int flags = 0 )
接口详述:
- 将所有后续提交到
stream的工作(任务)等待 event 中捕获的所有工作完成。event 捕获的内容参考 cudaEventRecord()。当适用时,synchronization将在设备上高效执行。 event 可能来自与 stream 不同的设备(应该是指多 GPU 并行执行的时候情况,但是具体细节有点不理解)。
参数:
- stream: Stream to wait
- event: Event to wait on
- flags: Parameters for the operation
返回:
- cudaSuccess, cudaErrorInvalidValue, cudaErrorInvalidResourceHandle
6, 在 stream 中捕获现有 graph。
__host__cudaError_t cudaStreamBeginCapture (cudaStream_t stream, cudaStreamCaptureMode mode)
值得注意的是,legacy default stream 不能被 capture,其他所有 stream 均可以被capture。这是因为,legacy default stream 的依赖关系太强,如果可以被 capture 会把所有其他 blocking stream 拉入 capture 状态,这不符合 graph 的设计,所以其不能被 capture 是合理的。
3.3 Stream 用法
CUDA Stream 的使用一般是如下步骤:
- 创建流:调用 cudaStreamCreate(&stream) 创建一个新的流。
- 异步操作:在特定流上调用
cudaMemcpyAsync()或kernel<<<… , stream>>>,将操作排队到该流中。 - 同步流:调用
cudaStreamSynchronize(stream)等待流中所有操作完成。
3.4 stream 示例代码
cudaMemcpyAsync、和 cuda stream 接口的实例代码如下:
#include <cuda_runtime.h>
#include <iostream>
#include <chrono>
// 一个简单的 kernel,将每个元素乘以2
__global__ void dummyKernel(float* d_data, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
d_data[idx] *= 2.0f;
}
}
int main() {
// 数据大小:约 256MB(假设 float = 4 bytes)
const size_t N = 1 << 26; // 67 million floats (~268MB)
size_t size = N * sizeof(float);
// 分配页锁定主机内存(pinned memory)以支持异步拷贝
float* h_data;
cudaMallocHost(&h_data, size);
for (size_t i = 0; i < N; ++i) {
h_data[i] = 1.0f;
}
// 分配设备内存
float* d_data;
cudaMalloc(&d_data, size);
// 使用默认流(Stream 0)
cudaStream_t stream = 0; // 默认流
// 记录主机计时(这些调用本身不会阻塞)
auto t0 = std::chrono::high_resolution_clock::now();
// 异步从 Host 到 Device 拷贝数据
cudaMemcpyAsync(d_data, h_data, size, cudaMemcpyHostToDevice, stream);
auto t1 = std::chrono::high_resolution_clock::now();
// 在同一默认流中启动 kernel(kernel 调用也是异步的)
int blockSize = 256;
int gridSize = (N + blockSize - 1) / blockSize;
dummyKernel<<<gridSize, blockSize, 0, stream>>>(d_data, N);
auto t2 = std::chrono::high_resolution_clock::now();
// 主机调用后立即返回;此时两项操作都在默认流中排队
// 主机继续执行其他工作(本例直接等待设备完成所有操作)
cudaDeviceSynchronize();
auto t3 = std::chrono::high_resolution_clock::now();
// 计算各阶段的耗时(单位:微秒和毫秒)
auto memcpyAsyncTime = std::chrono::duration_cast<std::chrono::microseconds>(t1 - t0).count();
auto kernelLaunchTime = std::chrono::duration_cast<std::chrono::microseconds>(t2 - t1).count();
auto totalTime = std::chrono::duration_cast<std::chrono::milliseconds>(t3 - t0).count();
std::cout << "Time for cudaMemcpyAsync call (host): " << memcpyAsyncTime << " microseconds\n";
std::cout << "Time for kernel launch call (host): " << kernelLaunchTime << " microseconds\n";
std::cout << "Total elapsed time until synchronization: " << totalTime << " ms\n";
// 清理内存
cudaFree(d_data);
cudaFreeHost(h_data);
return 0;
}
程序编译执行后,输出类似如下(具体数值依硬件和数据量而定):
Time for cudaMemcpyAsync call (host): 10 microseconds
Time for kernel launch call (host): 25 microseconds
Total elapsed time until synchronization: 150 ms
结果解释:
- 10μs 和 25μs 表示主机调用这两个 API 时几乎不阻塞;
- 150ms 的总时间主要来自大块数据的传输(256MB)和 kernel 执行时间;
- 此结果验证了:在默认流中,虽然主机调用是非阻塞的,但数据拷贝会阻塞后续在同一流中排队的 kernel 的执行。
四 Event 概述
4.1 Event 理解
Event 也是一种抽象概念,译为事件,它的定义和使用是为 Stream 而服务的!cuda events 记录的是 stream 中任务队列的状态,主要有两个作用:
- 时间测量:记录 GPU 上某个操作的开始和结束时间,从而可以通过计算两个 event 之间的时间差来估算内核执行时间或数据传输时间。
- 同步机制:可以在多个流之间进行同步。例如,一个流可以等待另一个流中记录的
event完成,再继续执行后续操作。
4.2 Event 管理 API
1,event 类型为 cudaEvent_t。
2,Event 管理的常用的函数包括:
cudaEventCreate():创建一个事件。cudaEventRecord():在指定的流中记录一个事件。cudaEventQuery():查询事件是否完成。cudaEventSynchronize():阻塞(等待)事件完成。cudaEventElapsedTime():计算两个事件之间经过的时间(单位为毫秒)。
函数接口定义如下所示:
// Creates an event object with the specified flags.
__host____device__cudaError_t cudaEventCreateWithFlags ( cudaEvent_t* event, unsigned int flags )
// Creates an event object.
__host__cudaError_t cudaEventCreate ( cudaEvent_t* event )
// Destroys an event object.
__host____device__cudaError_t cudaEventDestroy ( cudaEvent_t event )
// Computes the elapsed time between events.
__host__cudaError_t cudaEventElapsedTime ( float* ms, cudaEvent_t start, cudaEvent_t end )
__host__cudaError_t cudaEventElapsedTime_v2 ( float* ms, cudaEvent_t start, cudaEvent_t end )
// Queries an event's status.
__host__cudaError_t cudaEventQuery ( cudaEvent_t event )
// Records an event.
__host____device__cudaError_t cudaEventRecord ( cudaEvent_t event, cudaStream_t stream = 0 )
__host__cudaError_t cudaEventRecordWithFlags ( cudaEvent_t event, cudaStream_t stream = 0, unsigned int flags = 0 )
// Waits for an event to complete.
__host__cudaError_t cudaEventSynchronize ( cudaEvent_t event )
1,cudaEventRecord: 记录一个事件。
__host____device__cudaError_t cudaEventRecord ( cudaEvent_t event, cudaStream_t stream = 0 )
参数:
- event: Event to record
- stream: Stream in which to record event
接口详述:
- 在 event 中捕获了 stream 在调用时的内容。event 和 stream 必须位于同一个 CUDA 上下文中。随后的
cudaEventQuery()或cudaStreamWaitEvent()调用将检查或等待捕获的工作完成。cudaEventRecord函数调用之后,即使对 stream 继续添加任务,但 event 捕获的内容不会更新了。默认流的行为说明了在默认情况下捕获了什么内容。 - cudaEventRecord() 可以在同一事件上多次调用,并会覆盖之前捕获的状态。其他 API 如 cudaStreamWaitEvent() 在 API 调用时会使用最近一次捕获的状态,不会受到后续 cudaEventRecord() 调用的影响。在首次调用 cudaEventRecord() 之前,event 表示一个空的工作集,例如 cudaEventQuery() 会返回 cudaSuccess.
4.3 Event 用法
使用 CUDA event 的一般步骤如下:
- 创建事件(event)
- 使用 cudaEventCreate() 或 cudaEventCreateWithFlags()(可以设置阻塞等待或禁用计时等标志)来创建一个 event 对象。
- 记录 event
- 在需要测量或同步的位置,通过
cudaEventRecord(event, stream)将event记录到某个流中。记录操作会将 event 和 stream 中当前的工作排队关联。
- 在需要测量或同步的位置,通过
- 等待与查询
- 可以使用
cudaEventQuery(event)检查事件是否完成。如果返回 cudaSuccess,表示事件已经完成。 - 使用
cudaEventSynchronize(event)阻塞并等待事件完成,适用于需要确保 event 关联操作全部完成的情况。
- 可以使用
- 计算耗时
- 使用
cudaEventElapsedTime(&ms, start, stop)计算两个event之间的时间间隔(单位:毫秒)。
- 使用
- 销毁事件
- 使用
cudaEventDestroy(event)释放事件对象占用的资源。
- 使用
4.4 Event 示例代码
以下示例代码,实现在 GPU 上启动一个简单的 kernel,对数据进行处理(乘 2),并使用 event 记录内核执行时间。
#include <cuda_runtime.h>
#include <iostream>
// 简单的 kernel,将每个元素乘以 2
__global__ void simpleKernel(float* d_data, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
d_data[idx] *= 2.0f;
}
}
int main() {
const int N = 1 << 20; // 大约 1M 个元素
size_t size = N * sizeof(float);
// 分配设备内存
float* d_data;
cudaMalloc(&d_data, size);
// 创建 CUDA 事件
cudaEvent_t startEvent, stopEvent;
cudaEventCreate(&startEvent);
cudaEventCreate(&stopEvent);
// 在默认流中记录开始事件
cudaEventRecord(startEvent, 0);
// 启动 kernel
int blockSize = 256;
int gridSize = (N + blockSize - 1) / blockSize;
simpleKernel<<<gridSize, blockSize>>>(d_data, N);
// 在默认流中记录结束事件
cudaEventRecord(stopEvent, 0);
// 同步等待结束事件完成
cudaEventSynchronize(stopEvent);
// 计算 kernel 执行时间(毫秒)
float elapsedTime = 0;
cudaEventElapsedTime(&elapsedTime, startEvent, stopEvent);
std::cout << "Kernel execution time: " << elapsedTime << " ms" << std::endl;
// 清理资源
cudaEventDestroy(startEvent);
cudaEventDestroy(stopEvent);
cudaFree(d_data);
return 0;
}
上述 cu 程序编译运行后,结果如下所示(不同机器不一样):
Kernel execution time: 2.51234 ms